📝 Paper Summary
In-Context Learning (ICL)
Robustness of LLMs
Chain-of-Thought (CoT) Prompting
The paper investigates LLM vulnerability to irrelevant or inaccurate reasoning steps in prompts and proposes a contrastive denoising method that uses a single clean example to rectify noisy rationales.
Core Problem
Large Language Models (LLMs) are highly vulnerable to 'noisy rationales'—demonstrations containing irrelevant or inaccurate reasoning steps—significantly degrading performance even if the final answers in examples are correct.
Why it matters:
- Noisy rationales are common in real-world data sources like crowd-sourced platforms, dialogue systems, and machine-generated data, making robustness critical for practical deployment.
- Existing research focuses on noisy questions or answers, leaving the specific impact of flawed intermediate reasoning steps (Noisy-R) under-explored.
- Standard robustness methods like self-consistency and self-correction fail to effectively handle noisy rationales, sometimes performing worse than base models.
Concrete Example:
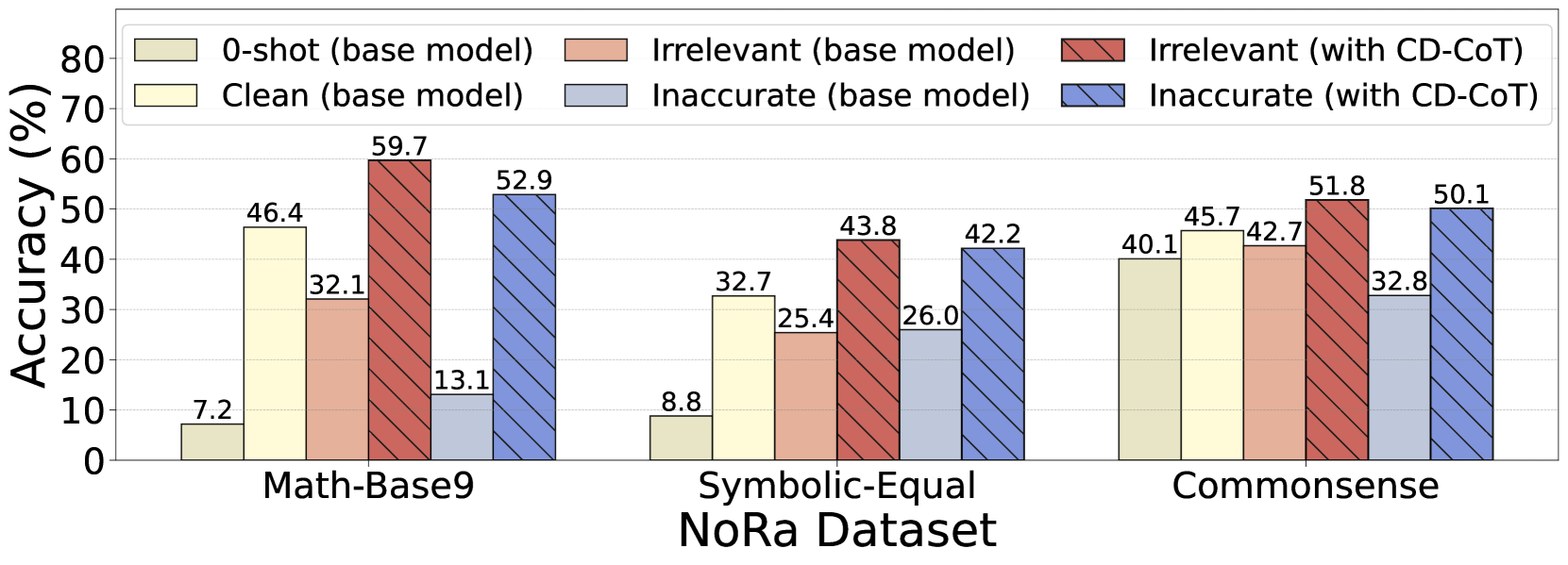
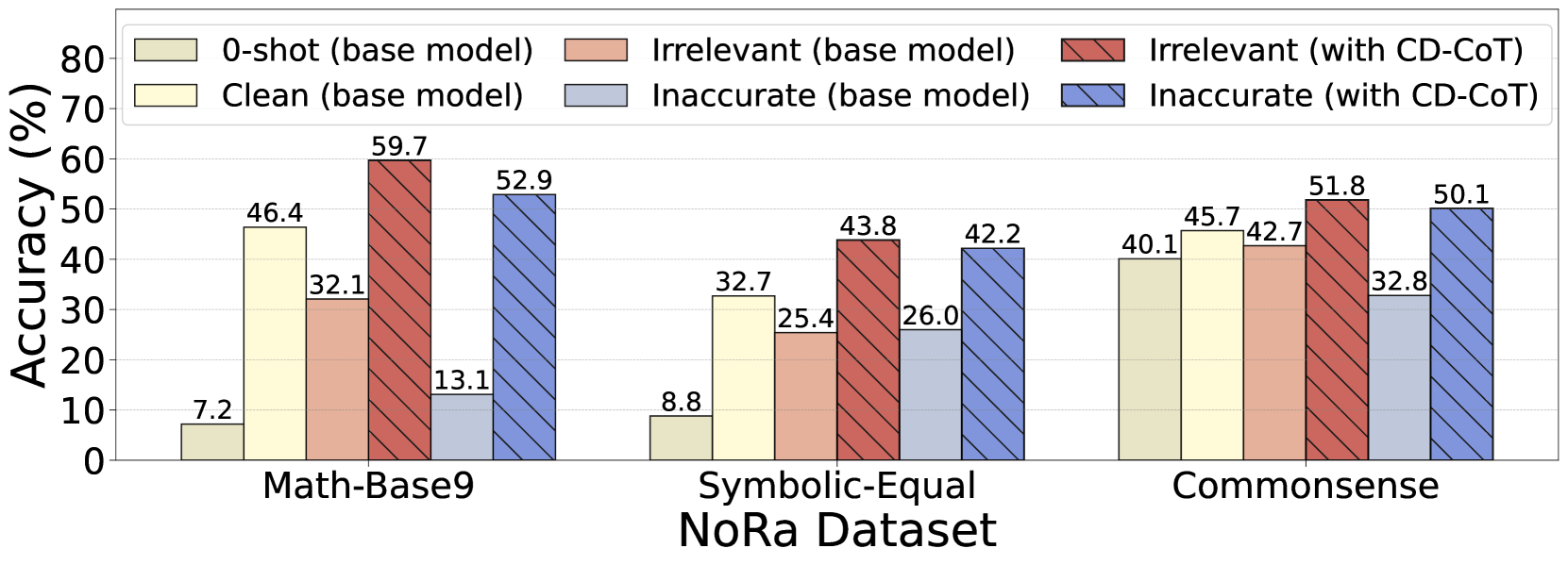
In a math problem using base-9 addition, a prompt might include a 'factually inaccurate' thought like '5+5=10' (incorrect in base-9). Alternatively, it might include 'irrelevant thoughts' about genetic overlap in a family relationship problem. These noises cause GPT-3.5's accuracy to drop by up to 40.4%.
Key Novelty
Contrastive Denoising with noisy Chain-of-Thought (CD-CoT)
- Leverages a single clean demonstration to 'denoise' multiple noisy examples by asking the LLM to contrast the noisy rationales against the clean one.
- follows an exploration-exploitation principle: first rephrasing and selecting high-quality rationales (explicit denoising), then generating diverse reasoning paths and voting on the final answer.
Architecture
The CD-CoT framework pipeline illustrating the four steps: Rationale Rephrasing, Rationale Selecting, Rationale Exploring, and Answer Voting.
Evaluation Highlights
- GPT-3.5 accuracy drops significantly with inaccurate thoughts (up to -40.4%) compared to clean rationales, highlighting intrinsic vulnerability.
- CD-CoT achieves an average accuracy improvement of 17.8% over the base model across three reasoning domains (Math, Symbolic, Commonsense).
- CD-CoT outperforms self-consistency baselines like SC (Self-Consistency) and SD (Self-Denoise), showing stronger denoising capabilities with minimal supervision.
Breakthrough Assessment
7/10
Identifies a distinct, under-explored failure mode (noisy rationales vs. noisy questions) and provides both a benchmark (NoRa) and a practical solution (CD-CoT). The reliance on a clean example is a constraint but realistic.