📝 Paper Summary
Medical Visual Question Answering (Med-VQA)
Visual Chain-of-Thought (CoT)
Interpretability in Medical AI
S-Chain introduces a large-scale, expert-verified dataset of medical images with structured, visually-grounded reasoning steps, demonstrating that training on faithful human annotations significantly outperforms synthetic data for medical visual question answering.
Core Problem
Current medical Vision-Language Models (VLMs) lack transparency and rely on synthetic reasoning chains (generated by GPT-4) that frequently hallucinate or fail to accurately ground text in specific image regions.
Why it matters:
- Medical diagnosis requires high-stakes reliability; 'black box' models without transparent reasoning are untrustworthy for clinical use
- Existing expert-annotated datasets are too small or lack visual grounding (bounding boxes linked to text), while large synthetic datasets contain factual errors and hallucinations
Concrete Example:
When diagnosing dementia from an MRI, a model trained on synthetic data might generate a correct final label but highlight the wrong brain region or describe 'hippocampal shrinkage' when none is visible, creating a misleading rationale.
Key Novelty
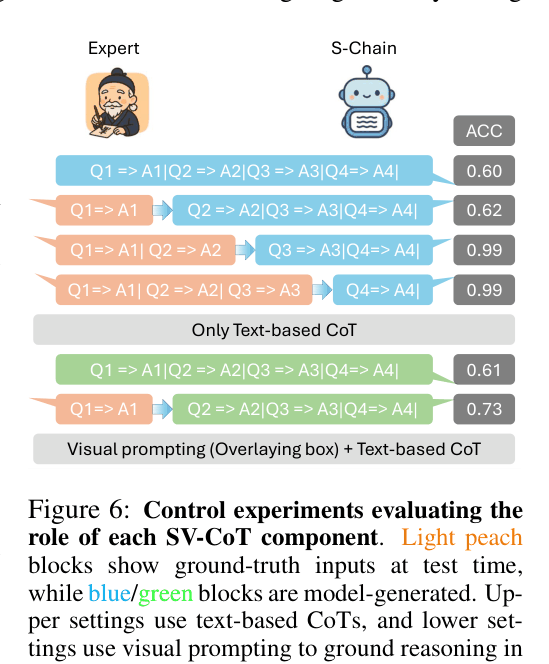
Structured Visual Chain-of-Thought (SV-CoT)
- Decomposes medical reasoning into four explicit, expert-verified stages: (1) Object Localization (bounding boxes), (2) Lesion Description, (3) Lesion Grading (standardized scales), and (4) Classification
- Provides the first large-scale (12k images) expert-annotated dataset where every reasoning step is visually grounded, unlike prior works that rely on unverified synthetic text or loose image-text pairs
Architecture
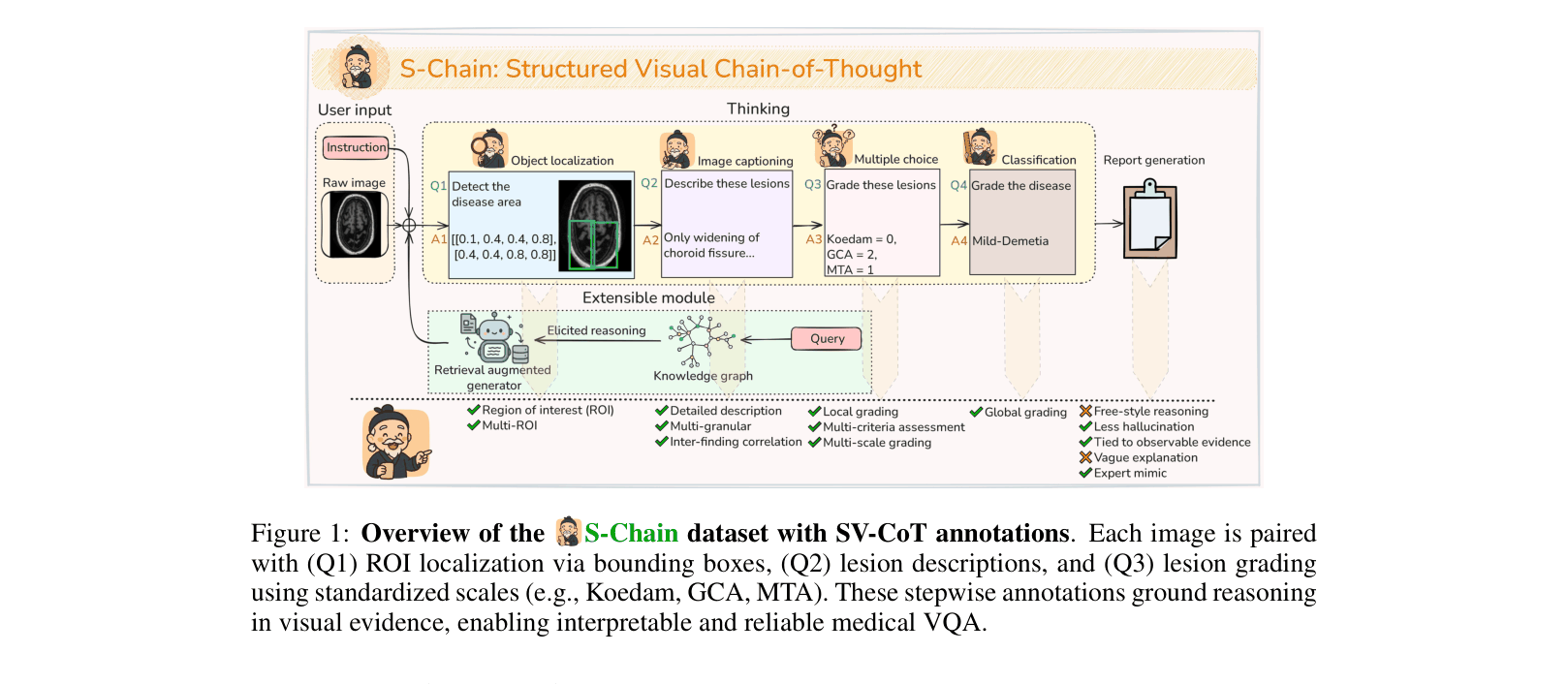
The 4-stage Structured Visual Chain-of-Thought (SV-CoT) process
Evaluation Highlights
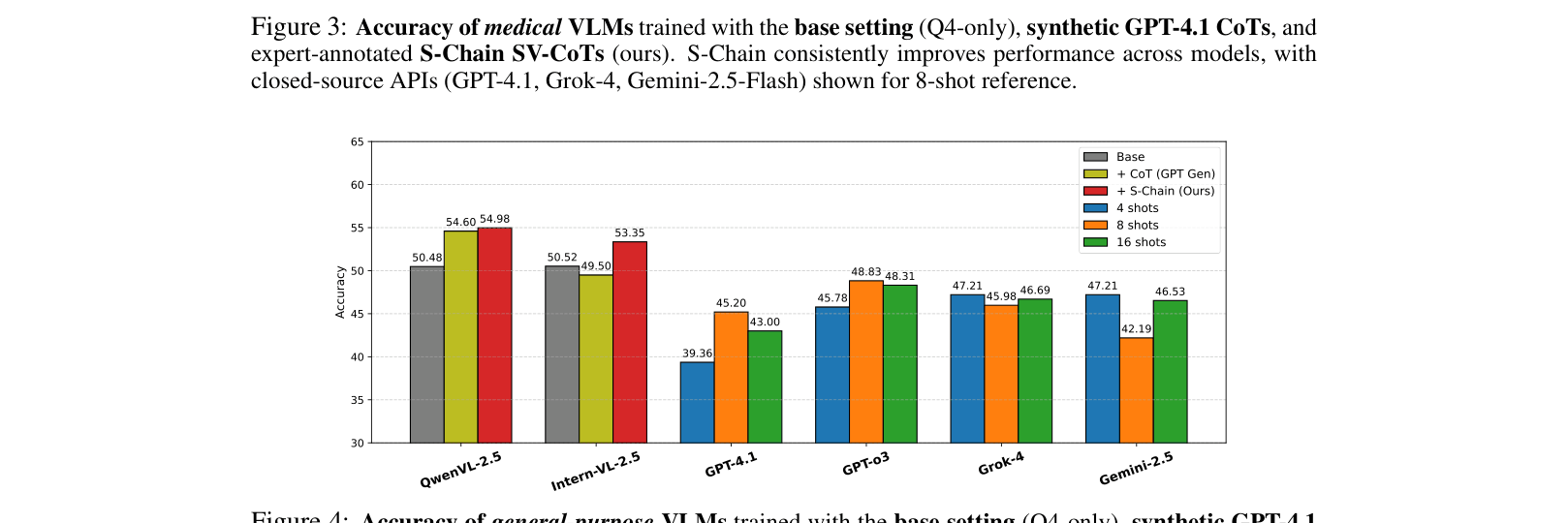
- S-Chain supervision improves ExGra-Med accuracy by +11.09% over base training and +4.47% over synthetic GPT-4.1 supervision on the test set
- Intermediate reasoning quality improves drastically: mIoU (localization accuracy) jumps from 4.3 (Synthetic) to 25.3 (S-Chain) on ExGra-Med
- Combining S-Chain supervision with Medical RAG (Retrieval-Augmented Generation) yields the highest performance, reaching 64.8% accuracy on ExGra-Med (+15.4% over base)
Breakthrough Assessment
9/10
Addresses a critical bottleneck in medical AI (lack of grounded, expert reasoning data) with a massive human-annotation effort. The dataset is a significant public resource that exposes the flaws of prevalent synthetic data approaches.