📝 Paper Summary
Reasoning Benchmarks
Neurosymbolic AI
MuSR is a challenging dataset of natural language narratives generated via a neurosymbolic process to evaluate large language models on multistep reasoning that integrates commonsense.
Core Problem
Current reasoning benchmarks are either too simple, lack natural text narratives, do not integrate commonsense with multistep logic, or are easily solvable by rule-based systems without true understanding.
Why it matters:
- Evaluating LLM reasoning is difficult because model capabilities outpace static benchmarks
- Existing datasets like CLUTRR or RuleTakers are solvable by rule-based systems and lack natural language nuance
- Benchmarks involving commonsense (e.g., SocialIQA) often lack multistep reasoning complexity
Concrete Example:
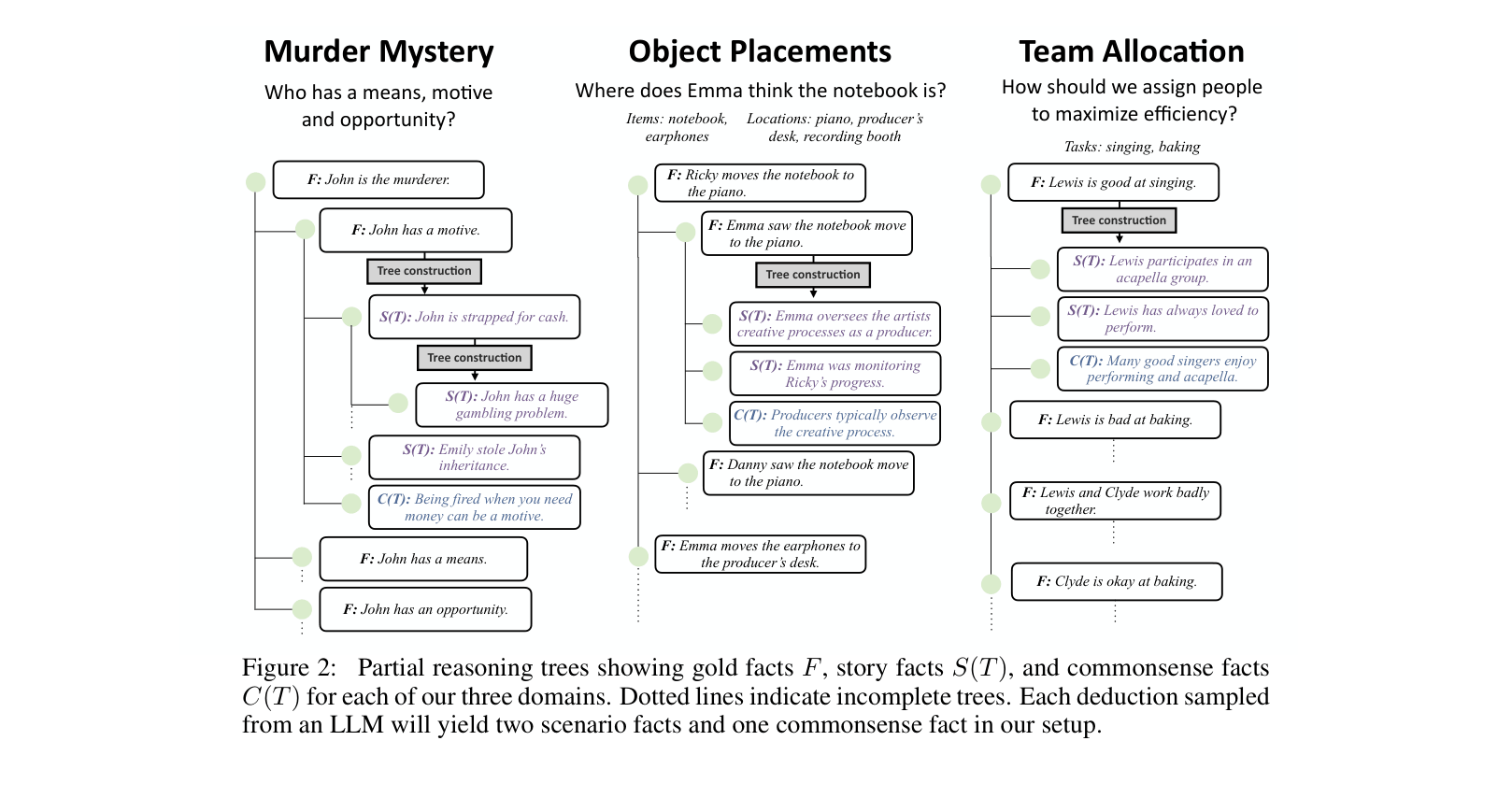
In a generated murder mystery, an LLM might successfully identify a suspect based on explicit text but fail to deduce 'motive' when it requires combining a social norm (e.g., getting fired causes anger) with a narrative fact (e.g., the suspect was fired).
Key Novelty
Neurosymbolic Synthetic-to-Natural Generation
- Constructs reasoning instances by first generating a logical 'reasoning tree' of gold facts and commonsense inferences, then using an LLM to generate a natural narrative based on that structure
- Ensures datasets have complex ground-truth intermediate structures (unlike pure synthetic text) but remain grounded in naturalistic narrative (unlike pure logic puzzles)
Architecture
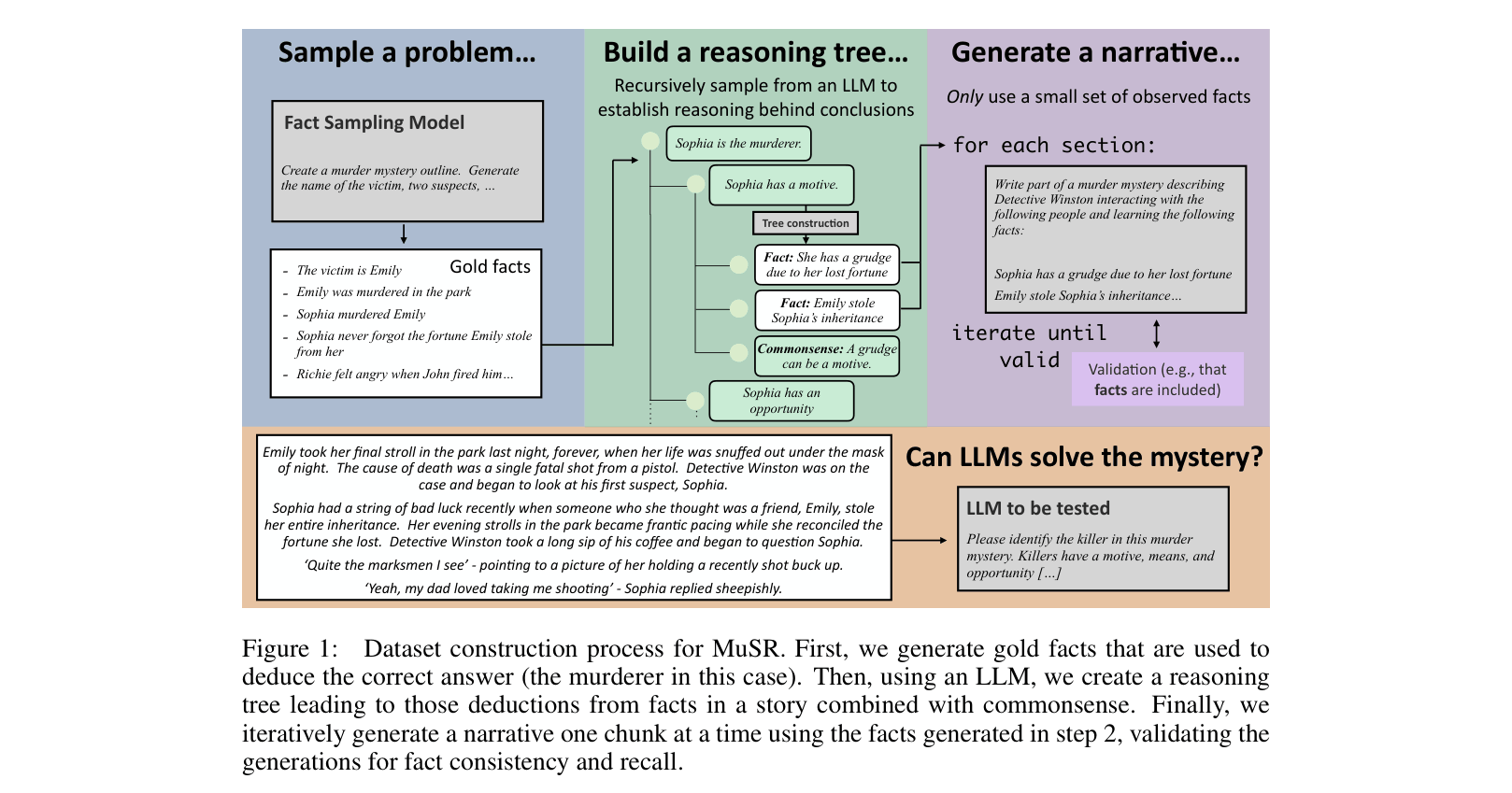
The Dataset Construction Process for MuSR.
Evaluation Highlights
- GPT-4 with CoT+ achieves 80.4% accuracy on Murder Mysteries, significantly lagging behind the Human Majority baseline of 94.1%
- Llama 2 70B Chat performs near random chance across all domains (e.g., 42.2% on Object Placements vs 24.6% random baseline)
- Program-Aided Language Models (PAL) outperform end-to-end GPT-4 on Team Allocation (87.2% vs 68.4%) by offloading calculation to Python
Breakthrough Assessment
8/10
A significant contribution to reasoning benchmarks. The generation methodology effectively bridges the gap between rigid logic puzzles and messy natural language, exposing clear limitations in current SOTA models.