📝 Paper Summary
Text-to-SQL Parsing
In-Context Learning
Chain-of-Thought Prompting
QDecomp improves Text-to-SQL parsing by prompting LLMs to decompose complex questions into sub-questions and identify relevant columns in a single pass, avoiding the error propagation of detailed SQL-based reasoning.
Core Problem
Large Language Models struggle with Text-to-SQL parsing because standard prompting lacks reasoning, while existing Chain-of-Thought methods introduce error propagation through overly detailed steps or computationally expensive iteration.
Why it matters:
- Text-to-SQL is critical for building natural language interfaces to databases, but training supervised models requires expensive expert annotation
- Existing CoT methods like Least-to-Most prompting require multiple model calls (iterative), increasing latency and cost
- Detailed reasoning steps (describing every SQL clause) often contain hallucinations that cascade into the final SQL query (error propagation)
Concrete Example:
For the question 'How many United Airlines flights go to City Aberdeen?', a Least-to-Most prompter generates a sub-query for 'go to City' first. It might incorrectly guess a column name for 'City' in this intermediate step because it hasn't seen the full context 'Aberdeen' yet. This incorrect column name propagates to the final query, causing execution failure.
Key Novelty
Question Decomposition Prompting (QDecomp + InterCOL)
- Instead of describing SQL execution steps (which is error-prone), prompt the model to break the natural language question into sub-questions in a single pass
- Augment reasoning steps with 'InterCOL' (Intermediate Column detection), where the model explicitly lists the table and column names relevant to each sub-question before generating the final SQL
Architecture
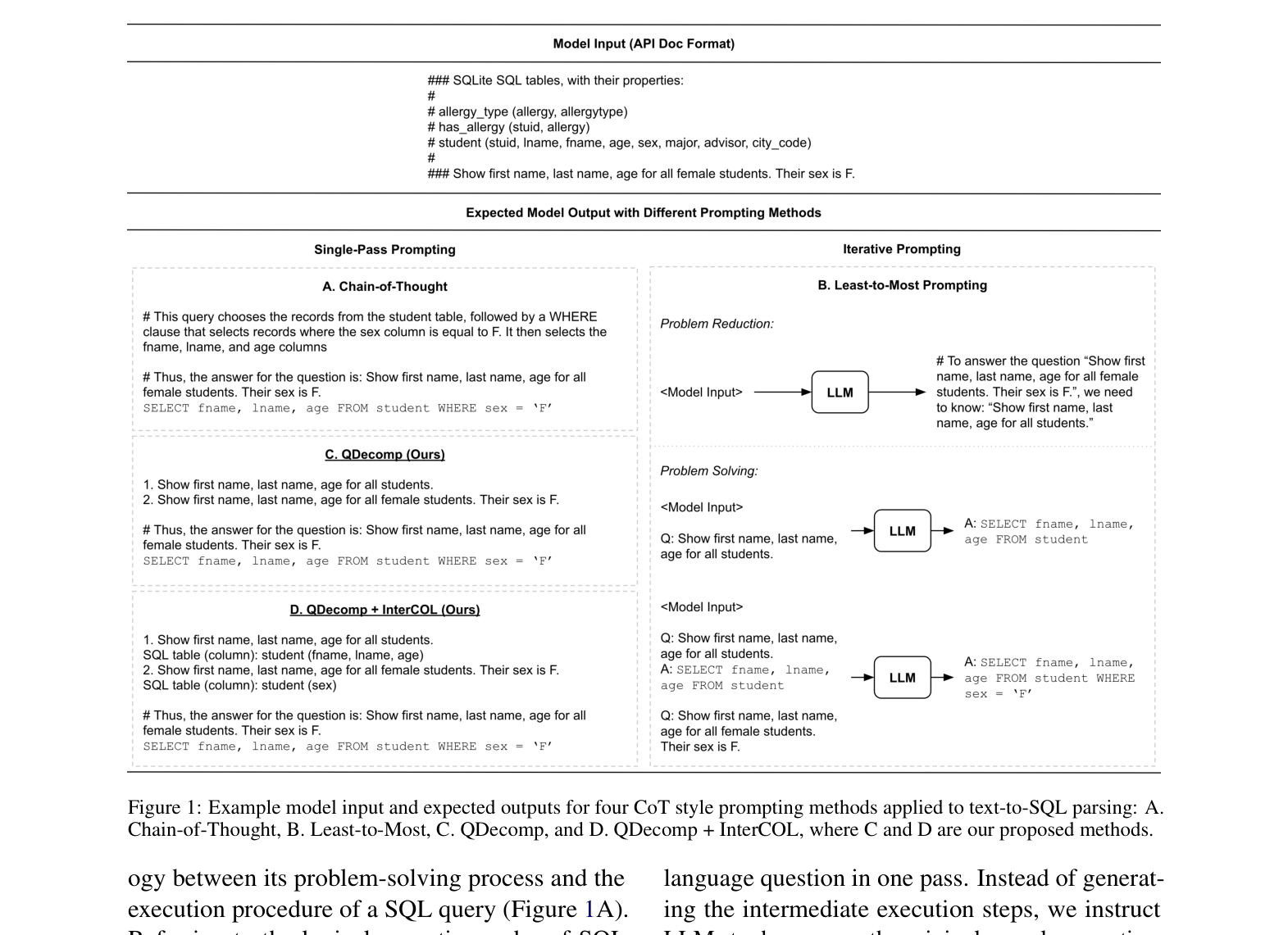
Comparison of four prompting strategies: Standard, Chain-of-Thought, Least-to-Most, and the proposed QDecomp / QDecomp+InterCOL
Evaluation Highlights
- +5.2% absolute gain in test-suite accuracy on Spider Dev compared to standard prompting (68.4% vs 63.2%)
- +5.5% absolute gain on Spider Realistic compared to standard prompting (56.5% vs 51.0%)
- Outperforms Least-to-Most prompting by 2.4% on Spider Dev while using a single-pass generation instead of iterative prompting
Breakthrough Assessment
8/10
Significantly improves Text-to-SQL performance without fine-tuning, challenging the prevailing assumption that iterative prompting is necessary for complex reasoning. The QDecomp+InterCOL design effectively isolates schema linking errors.