📝 Paper Summary
Commonsense Reasoning in Dialogue
Knowledge Distillation
Chain-of-Thought Reasoning
The paper proposes a framework to distill high-quality multi-hop commonsense reasoning capabilities from unreliable Large Language Models into a smaller, efficient dialogue agent via rigorous alignment filtering.
Core Problem
Existing dialogue agents struggle with commonsense reasoning because key evidence is implicitly scattered across multiple turns, requiring multi-hop reasoning that single-hop knowledge models miss.
Why it matters:
- Current methods like COMET generate single-hop inferences that fail to integrate scattered context, leading to dull or incoherent responses
- Simply prompting LLMs for reasoning is unreliable due to hallucinations (unfaithfulness) and generation of irrelevant rationales (unhelpfulness)
Concrete Example:
In a dialogue about a lost handbag, implicit clues appear across turns ('lunch', 'restaurant', 'didn't find it there'). A single-hop model vaguely suggests 'Call the police', whereas the proposed multi-hop reasoner correctly infers 'You should go to the restaurant where you had lunch'.
Key Novelty
Dialogue Chain-of-Thought (CoT) Distillation & DOCTOR
- Formulates dialogue reasoning as a multi-step QA process (Dialogue CoT) to uncover implicit evidence, rather than a single generation step
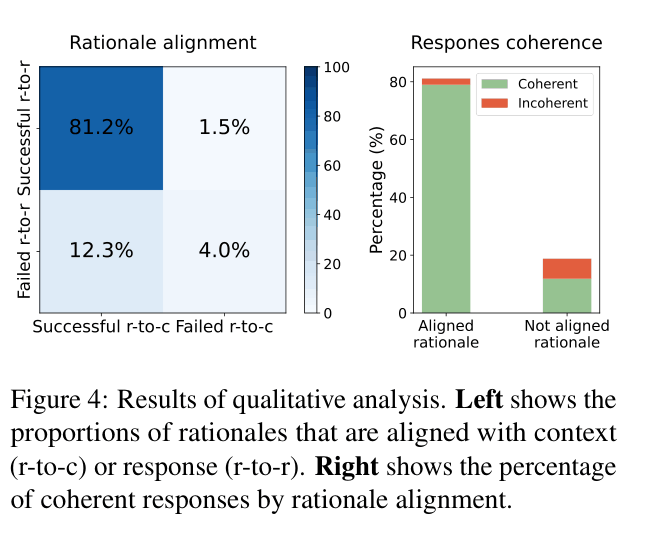
- Uses an 'unreliable' LLM (ChatGPT) to generate candidates, then cleans them with two alignment filters: one for consistency (detecting hallucinations) and one for helpfulness (relevance to response)
- Distills this filtered data into a smaller, specialized model (DOCTOR) that generates superior rationales compared to the original LLM prompting
Architecture
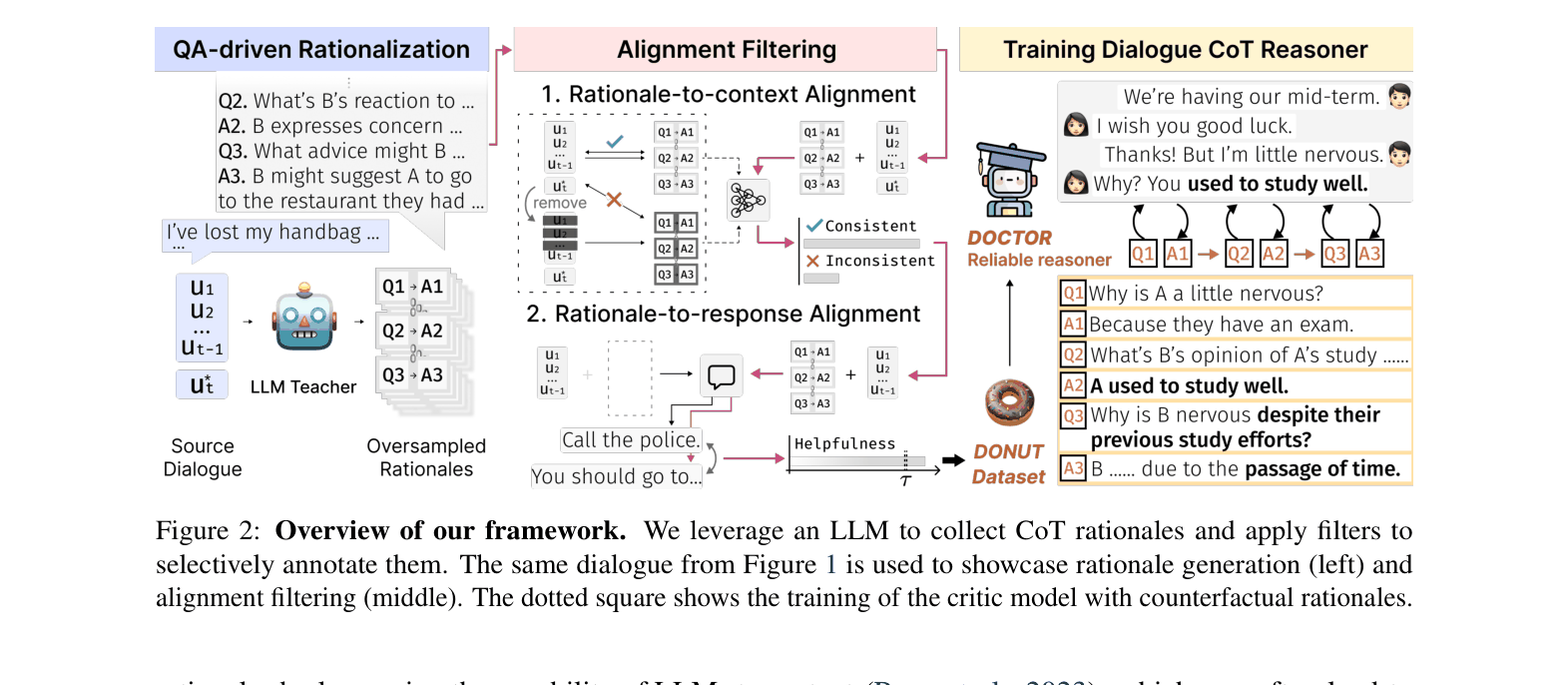
The distillation framework: (1) Rationale Generation using LLM, (2) Alignment Filtering (Critic + Helpfulness), and (3) Training the DOCTOR model.
Evaluation Highlights
- ChatGPT augmented with DOCTOR achieves +2.36 BLEU-1 and +1.26 BLEU-2 over vanilla ChatGPT on the DailyDialog dataset
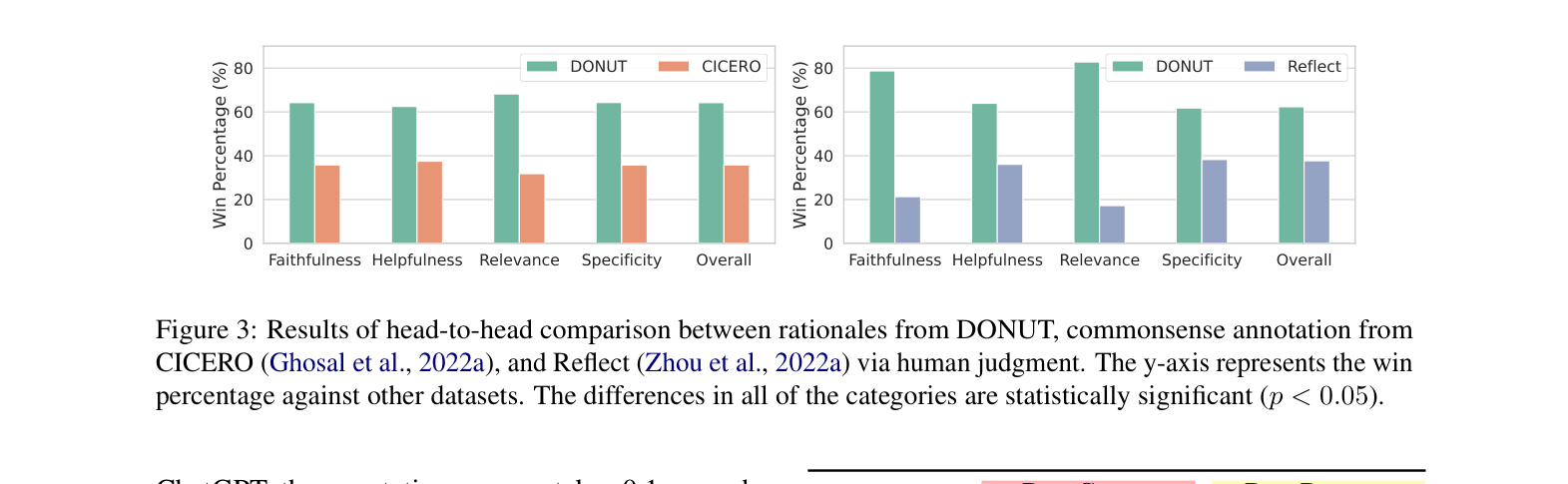
- Human judges prefer responses generated using DOCTOR over those using 'Self-CoT' (ChatGPT prompting itself) 67% of the time for naturalness
- DOCTOR generalizes well: on the out-of-domain Reflect-9K dataset, it outperforms the 'Reflect' baseline (+0.30 BLEU-1) which was trained specifically on that domain
Breakthrough Assessment
8/10
Significant contribution in defining 'Dialogue CoT' and proving that distilled, filtered small models can outperform large teacher models in reasoning quality. The release of the DONUT dataset is a major resource.