📝 Paper Summary
Multimodal Reasoning
Chain-of-Thought (CoT) Prompting
Multimodal-CoT separates rationale generation and answer inference into a two-stage framework incorporating dense vision features, enabling small models (<1B parameters) to perform effective reasoning without hallucination.
Core Problem
Small language models (<1B parameters) fail to perform effective Chain-of-Thought reasoning, often hallucinating rationales that degrade answer accuracy compared to direct prediction.
Why it matters:
- Existing CoT methods focus on large language models (>100B params), which are resource-intensive to deploy.
- Converting images to captions for LLMs results in significant information loss.
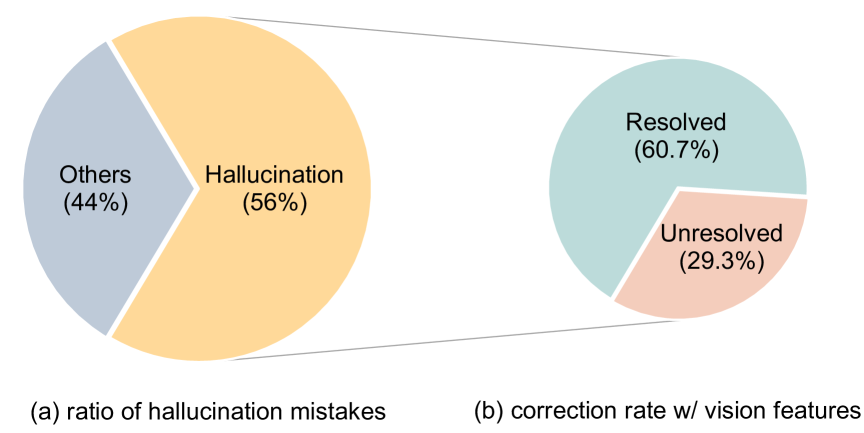
- Naive fine-tuning of small models for CoT causes 'hallucinated rationales' where the reasoning contradicts the image or leads to wrong answers (e.g., accuracy drops from 81.63% to 69.32%).
Concrete Example:
In a ScienceQA physics problem about magnets, a text-only model hallucinates the rationale 'The south pole of one magnet is closest to the south pole of the other' because it cannot see the image, leading to an incorrect answer. The proposed method uses vision features to correctly identify the poles.
Key Novelty
Two-Stage Multimodal-CoT Framework
- Separates the reasoning process into two distinct stages: (1) generating a rationale based on image and text, and (2) inferring the answer based on the image, text, and generated rationale.
- Injects dense vision features (via ViT) directly into the language model's encoder rather than relying on lossy image captions.
Architecture
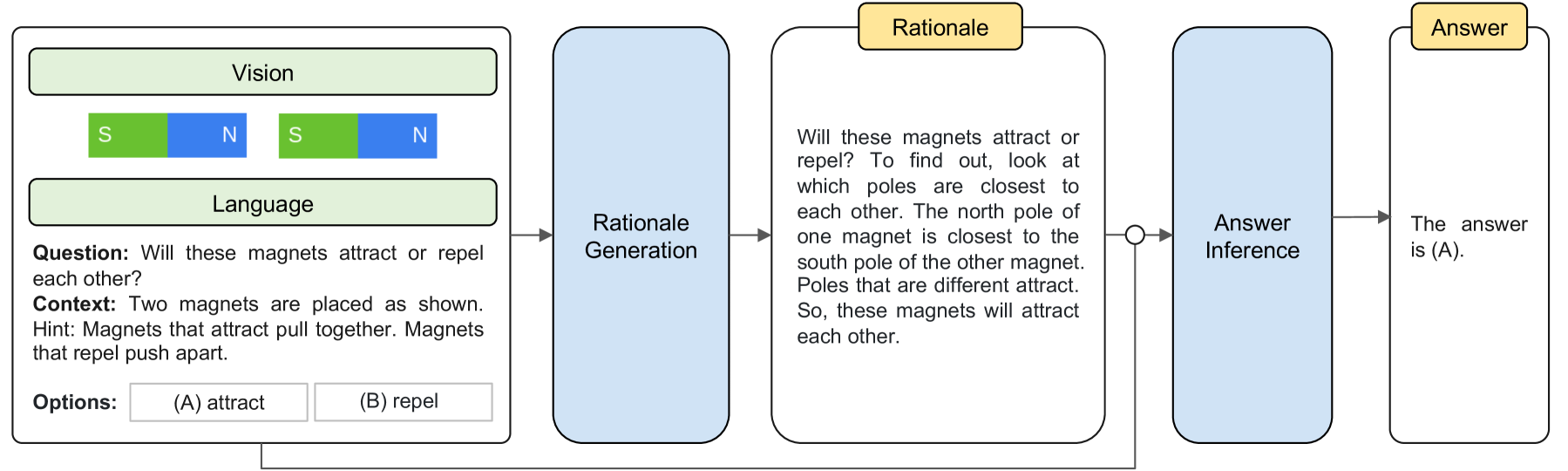
The two-stage framework for Multimodal-CoT. Stage 1 generates the rationale from language and vision inputs. Stage 2 appends the generated rationale to the language input to infer the final answer.
Evaluation Highlights
- Achieves 85.31% accuracy on ScienceQA with a model under 1B parameters, surpassing the previous text-only baseline of 81.63%.
- Corrects 60.7% of hallucination errors observed in text-only baselines by incorporating vision features.
- Outperforms caption-based multimodal approaches (79.37%) by using deep fusion of vision features.
Breakthrough Assessment
8/10
Significant because it demonstrates that small models (<1B params) can perform effective CoT reasoning if the architecture (two-stage) and modality fusion (vision features) are handled correctly, challenging the assumption that CoT requires >100B parameters.