📝 Paper Summary
Model Compression
Reasoning Models
Reasoning-Aware Compression improves pruning accuracy by calibrating on self-generated chain-of-thought traces, preventing the performance collapse and 'rambling' behavior seen with standard prompt-based calibration.
Core Problem
Standard pruning methods calibrate on short input prompts, failing to capture the activation distribution of reasoning models which is dominated by long, self-generated chains of thought.
Why it matters:
- Pruned reasoning models suffer disproportionate accuracy drops compared to standard language models when using generic calibration (e.g., C4)
- Ineffective pruning causes models to 'ramble'—generating longer, less accurate chains of thought—which paradoxically increases inference latency despite the theoretical speedup of compression
- Deploying large reasoning models like DeepSeek-R1 is resource-intensive; effective compression is critical for real-world usage
Concrete Example:
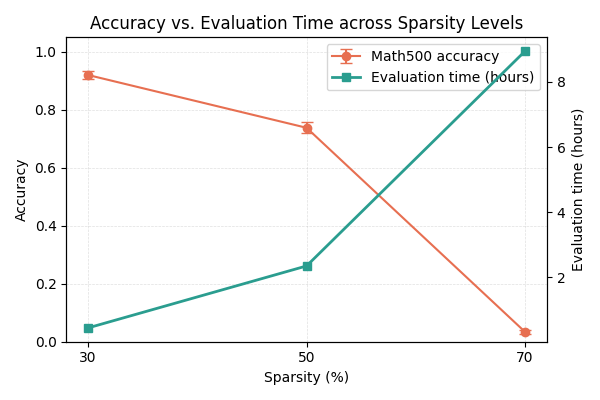
When pruned to 50% sparsity using standard C4 calibration, the DeepSeek-R1-Distill-Qwen-7B model drops from 92.8% to 74.4% accuracy on MATH-500 and generates significantly longer, incoherent reasoning traces, slowing down inference.
Key Novelty
Reasoning-Aware Compression (RAC)
- Augment the calibration dataset used for pruning by including 'on-policy' chain-of-thought traces generated by the model itself
- Align the pruning objective with the inference-time distribution, where activations are driven primarily by reasoning tokens rather than input prompts
Architecture
The calibration data collection process for RAC
Evaluation Highlights
- +15.6% accuracy on MATH-500 for DeepSeek-R1-Distill-Qwen-7B at 50% sparsity compared to standard C4 calibration (90.0% vs 74.4%)
- +30.8% accuracy on MATH-500 for the 1.5B model at 50% sparsity (66.4% vs 35.6%), recovering most of the dense model's performance
- Eliminates inference slowdown: RAC-pruned models maintain decoding lengths similar to dense models, avoiding the 'rambling' pathology of standard pruning
Breakthrough Assessment
8/10
Identifies a critical, counter-intuitive failure mode in pruning reasoning models (rambling) and provides a simple, highly effective fix that aligns calibration with the specific nature of reasoning tasks.