📝 Paper Summary
Reasoning Distillation
Small Language Models (SLMs)
Chain-of-Thought (CoT)
D-CoT teaches small models to structure their reasoning using control tags (e.g., for fact-checking vs. exploration) during training, significantly improving accuracy and reducing token usage by eliminating 'overthinking'.
Core Problem
When distilling complex Chain-of-Thought from frontier models, Small Language Models (SLMs) suffer from 'overthinking'—generating unnecessary loops, drifting context, and excessive tokens due to limited capacity.
Why it matters:
- Simply copying frontier model thoughts causes SLMs to exceed their optimal context/compute scaling laws, degrading performance
- Existing methods like passive filtering (removing CoT segments) sacrifice the exploration diversity needed for hard tasks
- Inefficient reasoning wastes computational resources and increases latency without improving answers
Concrete Example:
A base SLM might enter a 'Wait, but...' loop, wasting hundreds of tokens simulating longhand arithmetic (e.g., '831.81 / 160 = ...') or hesitating endlessly. D-CoT performs a focused verification and moves on.
Key Novelty
Disciplined Chain-of-Thought (D-CoT) with Control Tags
- Uses explicit control tags (e.g., <TEMP_LOW> for facts, <TEMP_HIGH> for exploration) as scaffolding during training to regulate the 'temperature' and mode of thought
- Trains on domains completely unrelated to benchmarks (e.g., Legacy IT, Corporate Politics) to force learning of reasoning *structure* rather than domain knowledge
- Optimizes the reasoning trajectory to be disciplined and efficient, allowing the model to internalize these patterns even without tags at inference
Architecture

Contrast between traditional distilled CoT (overthinking) and D-CoT (disciplined reasoning) using control tags
Evaluation Highlights
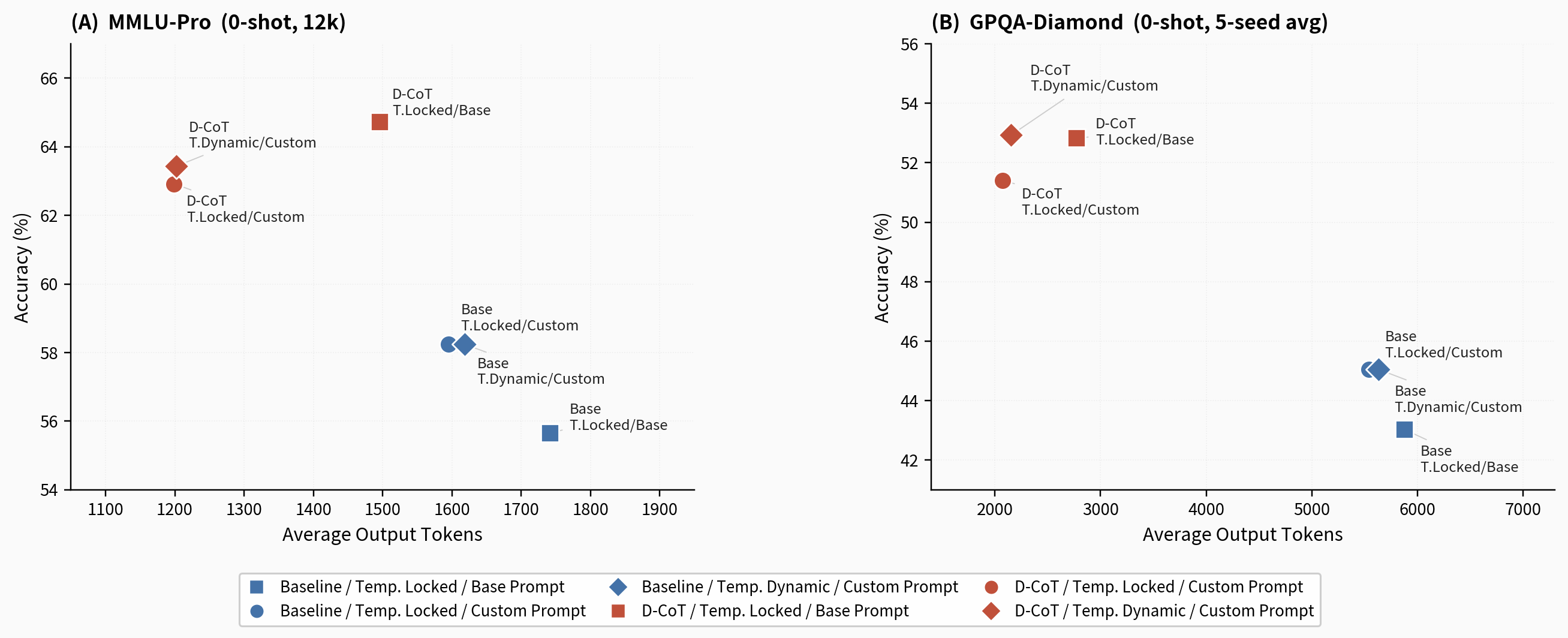
- +9.9% accuracy improvement on GPQA-diamond (0-shot) using Qwen3-8B compared to the base model
- +9.07% accuracy boost on MMLU-Pro (0-shot) while reducing average token count by 31.2%
- Reduced 'Null rate' (failure to produce valid answer) on GPQA from 30.91% to <5%, proving improved reasoning stability
Breakthrough Assessment
9/10
Achieves massive gains (+9-10%) on very hard benchmarks (GPQA) for a small model (8B) while drastically cutting compute costs. The internalization finding and use of unrelated training domains are methodologically strong.