📝 Paper Summary
Chain-of-Thought Reasoning
Controlled Decoding
GRACE improves multi-step reasoning by utilizing a contrastively trained discriminator to verify and select correct reasoning steps during decoding, training this discriminator without human annotations via a novel alignment algorithm.
Core Problem
Language models frequently assign high likelihood to incorrect reasoning steps, and standard decoding strategies (like greedy) or post-hoc filtering (like self-consistency) often fail to recover correct solutions once the generation goes off-track.
Why it matters:
- Current oversampling methods (Self-Consistency, Verifiers) are inefficient as they generate full solutions before checking, wasting compute on doomed paths
- Supervised fine-tuning on gold solutions can lead to overfitting, where valid alternative reasoning paths are penalized
- Existing step-level reward models often require expensive, non-scalable human annotations
Concrete Example:
When prompting LLaMA-13B on a GSM8K math problem with a correct prefix, the model assigns higher probability to incorrect next steps than to the correct one. Standard decoding picks the incorrect step, derailing the entire solution.
Key Novelty
Stepwise Discriminator-Guided Decoding
- Intervenes *during* generation: instead of filtering complete answers, it scores candidate steps at each point using a discriminator and selects the best one to proceed
- Self-supervised alignment: Creates training data for the discriminator by automatically aligning sampled incorrect solutions with correct references using the Needleman-Wunsch algorithm, avoiding the need for human step-level labels
Architecture
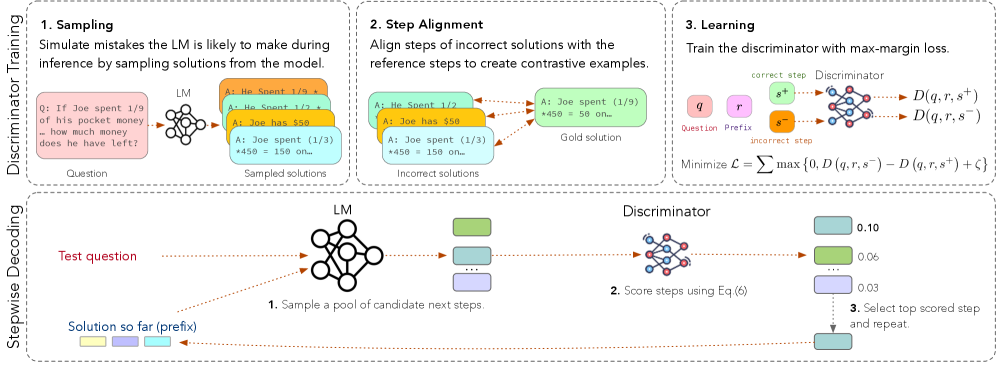
The complete GRACE pipeline: (Top) Discriminator Learning process involving Negative Sampling, Alignment, and Learning. (Bottom) Guided Decoding process.
Evaluation Highlights
- Reduces solution error rate on GSM8K human evaluation by 44% (from 9.0% error rate with greedy decoding to 5.0% with GRACE)
- Outperforms greedy decoding on GSM8K by 7.4% accuracy points using FLAN-T5-Large and 5.4% using LLaMA-7B
- When combined with self-consistency, outperforms vanilla self-consistency by 15.7% points on MultiArith
Breakthrough Assessment
7/10
Strong methodological contribution in automated alignment for discriminator training, addressing the supervision bottleneck. Significant gains over standard baselines like Self-Consistency.

