📝 Paper Summary
Chain-of-Thought (CoT) Prompting
Prompt Engineering
In-context Learning
Automate-CoT automatically generates reasoning chains for labeled data and selects the optimal subset of exemplars using a variance-reduced policy gradient strategy to maximize task performance.
Core Problem
Manual design of Chain-of-Thought (CoT) exemplars is labor-intensive and sensitive to factors like order, complexity, diversity, and style, making adaptation to new tasks difficult.
Why it matters:
- Human-written prompts are costly to create and optimize for every new dataset
- Performance of Large Language Models (LLMs) fluctuates significantly based on arbitrary choices like exemplar order (up to 3.3% drop on GSM8K)
- Static human prompts often fail to match the complexity or diversity required by specific questions
Concrete Example:
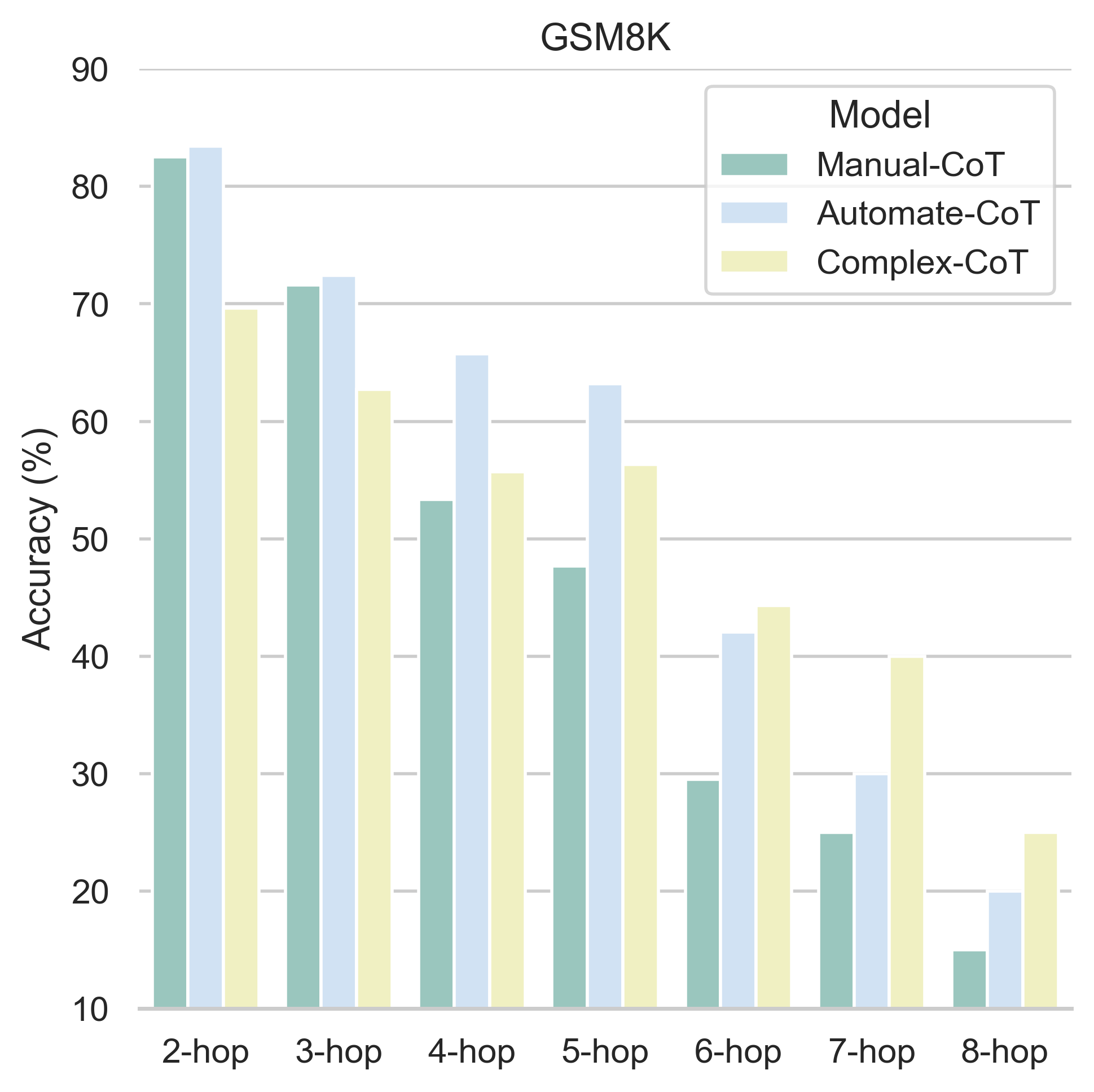
On the GSM8K math dataset, simply shuffling the order of human-written Manual-CoT exemplars causes accuracy to drop from 63.1% to 59.8%. Furthermore, using only complex exemplars helps hard questions but hurts performance on simple ones.
Key Novelty
Automate-CoT (Automatic Prompt Augmentation and Selection with Chain-of-Thought)
- Augments labeled data by using an LLM to generate pseudo-reasoning chains, pruning those that lead to incorrect answers
- Treats the selection of in-context exemplars as a latent variable optimization problem, using reinforcement learning (policy gradient) to find the combination that maximizes prediction accuracy
Architecture
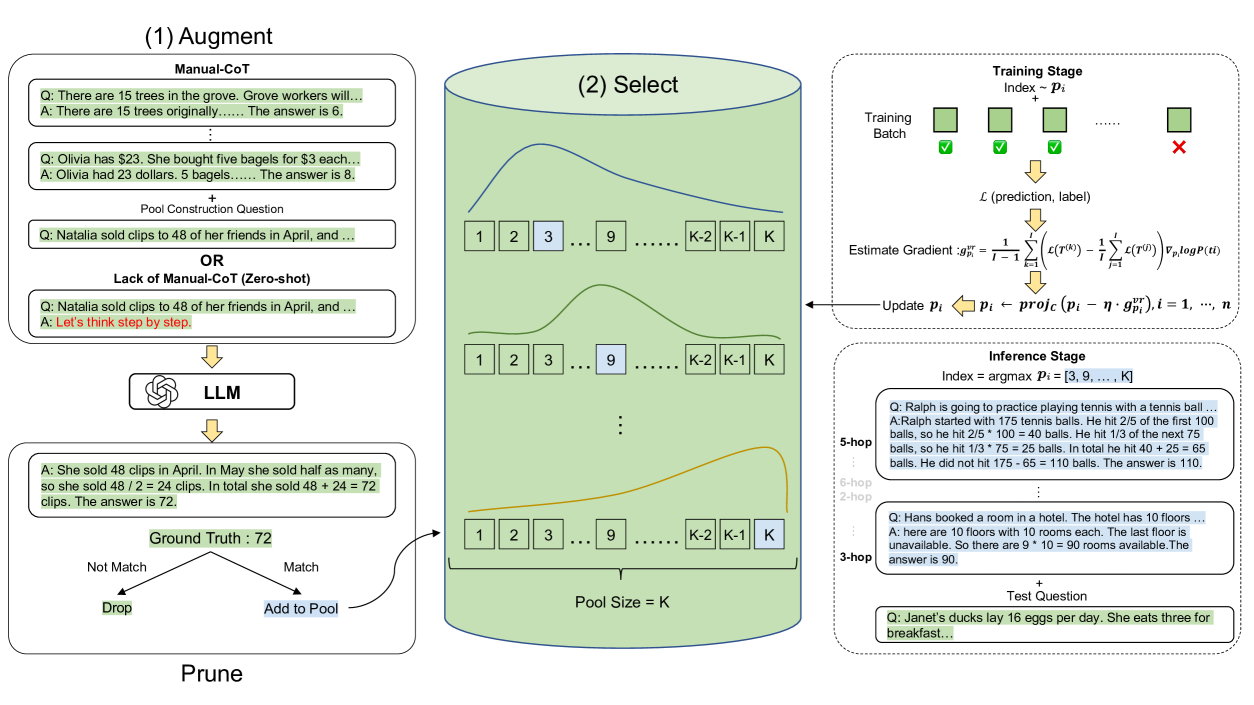
The overall three-step pipeline of Automate-CoT: Augment, Prune, and Select.
Evaluation Highlights
- +2.7% average accuracy improvement over Manual-CoT across five arithmetic reasoning tasks using text-davinci-002
- +3.3% average improvement over Self-Consistency (SC) on arithmetic tasks under the self-consistency setting
- Outperforms Auto-CoT by 4.8% on GSM8K using code-davinci-002
Breakthrough Assessment
7/10
Solid automated pipeline that removes the need for manual CoT engineering while achieving consistent gains across diverse reasoning tasks. Effectively addresses sensitivity issues identified in prior work.