📝 Paper Summary
Diffusion Language Models
Chain-of-Thought Reasoning
Non-autoregressive Text Generation
Diffusion-of-Thought enables diffusion language models to perform complex multi-step reasoning by treating reasoning steps as latent variables that diffuse over time, allowing for flexible computation trade-offs and self-correction.
Core Problem
Autoregressive Chain-of-Thought (CoT) suffers from error accumulation (left-to-right bias) where early mistakes propagate to final answers, and it lacks flexibility to trade computation for performance dynamically.
Why it matters:
- Errors in early reasoning steps of autoregressive models often lead to irreversible failures in the final answer.
- Autoregressive models have a fixed computational cost per token, whereas difficult problems might benefit from flexible 'thinking time' without generating more text.
- Existing pre-trained diffusion language models (like Plaid, SEDD) lag behind autoregressive models in complex reasoning capabilities.
Concrete Example:
In a math problem, an autoregressive model might generate '2*3=4' early on. Because it generates token-by-token left-to-right, it is forced to condition on this error for all subsequent steps, leading to a wrong answer. DoT can correct '<2*3=4>' to '<2*3=6>' in later diffusion timesteps before finalizing the output.
Key Novelty
Reasoning as a Denoising Process
- Treats intermediate reasoning steps (thoughts) as latent variables that are gradually denoised from random noise alongside the final answer.
- Allows the model to 'think' in parallel and revise earlier parts of the reasoning chain during the generation process (self-correction), unlike the rigid left-to-right generation of autoregressive models.
- Introduces a Multi-Pass variant (DoTMP) that generates one thought at a time to combine the benefits of diffusion flexibility with causal inductive bias.
Architecture
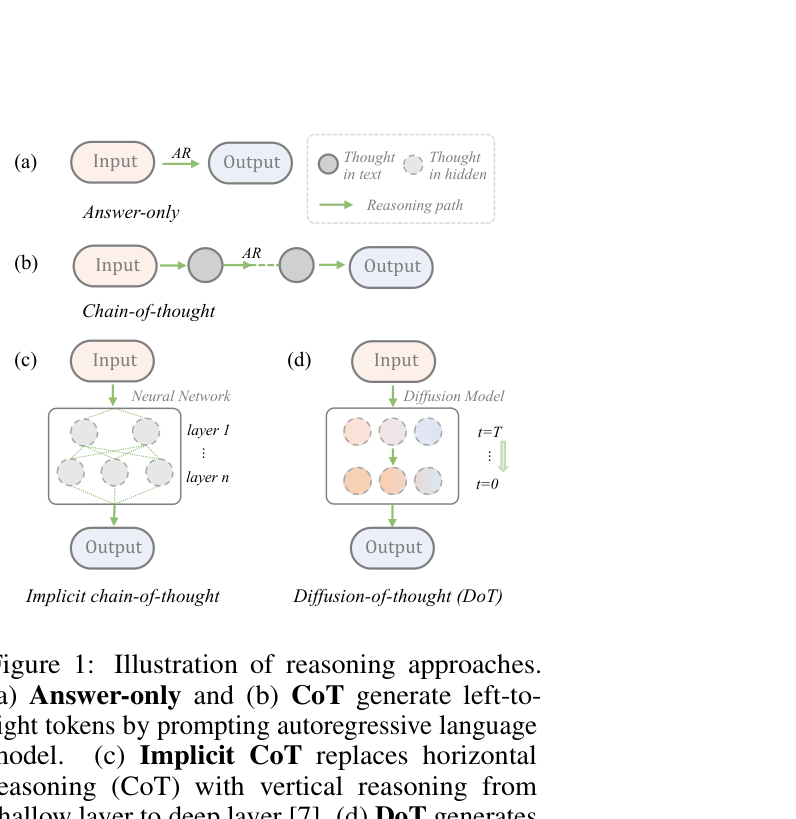
Conceptual comparison of Answer-only, CoT, Implicit CoT, and Diffusion-of-Thought (DoT).
Evaluation Highlights
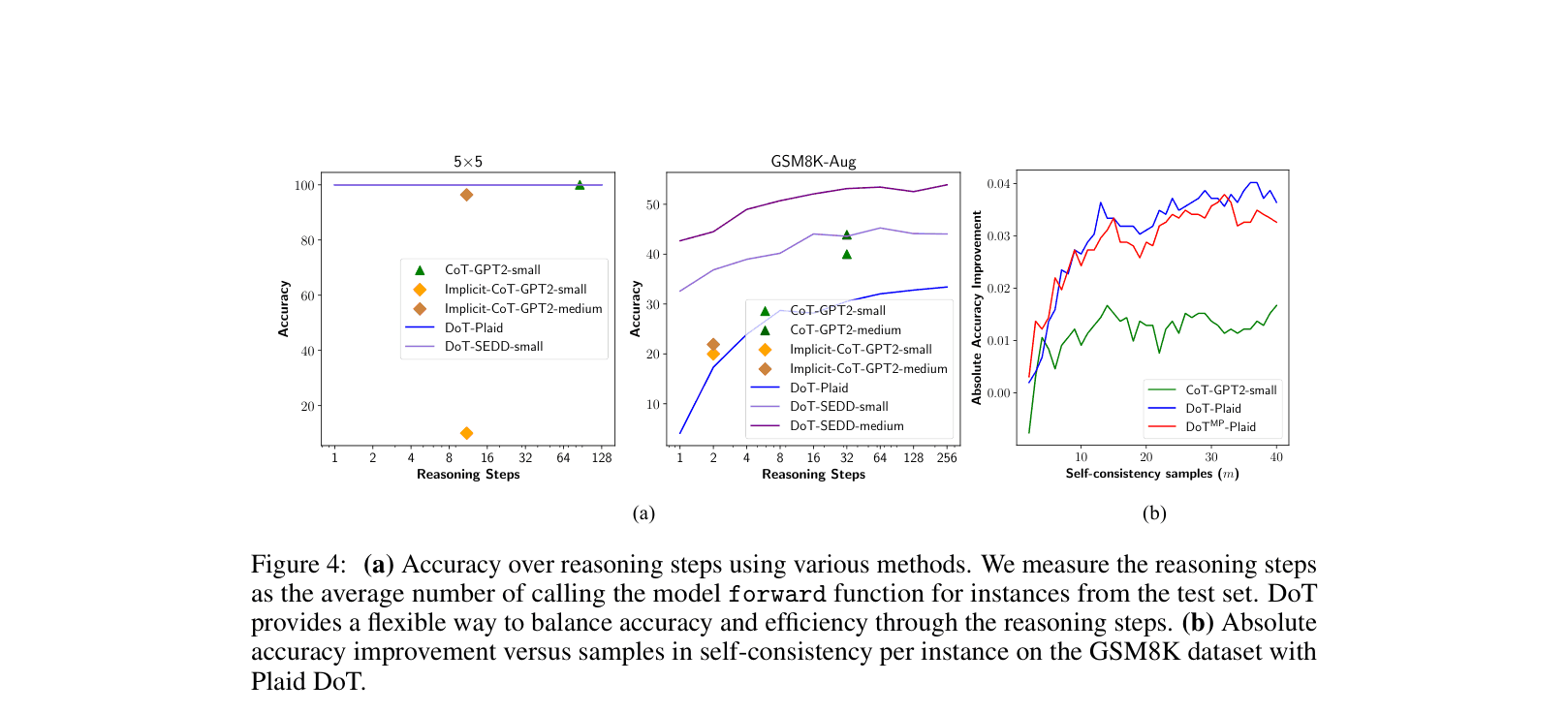
- Small diffusion model (SEDD-medium, 424M) outperforms a 1.8x larger GPT-2 Large (774M) on Grade School Math (GSM8K) by ~8.7% (53.5% vs 44.8%).
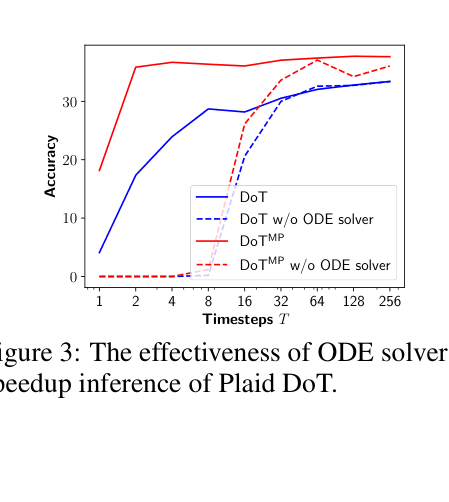
- Achieves up to 27x speed-up on simple digit multiplication tasks compared to autoregressive CoT without performance drop.
- Self-consistency decoding boosts SEDD-medium performance on GSM8K from 53.5% to 59.4%.
Breakthrough Assessment
7/10
First successful application of CoT to pre-trained diffusion LMs with competitive results against AR baselines. While absolute performance is below SOTA LLMs, it proves diffusion models can reason and self-correct.