📝 Paper Summary
Neuro-symbolic AI
Logical Reasoning
SymbCoT enhances LLM logical reasoning by integrating symbolic expressions and rules into a plan-solve-verify Chain-of-Thought workflow entirely within the LLM, eliminating reliance on external solvers.
Core Problem
Standard Chain-of-Thought (CoT) struggles with precise logical calculations, while existing neuro-symbolic methods rely on external solvers that are brittle to syntax errors and lack interpretability.
Why it matters:
- Pure LLMs often hallucinate in rigid logical deduction tasks or fail to track long inference chains.
- External solvers (used in Logic-LM) fail completely if the LLM generates even slightly incorrect symbolic syntax.
- Relying on external tools creates an opacity barrier, making it hard to explain why a specific logical conclusion was reached.
Concrete Example:
In a logic puzzle about golf rankings, GPT-4 with standard CoT incorrectly infers 'Descampe is in the six-way tie' by affirming the consequent. SymbCoT translates the premises to First-Order Logic, realizes the necessary premise 'Tie(Descampe, sixWay)' is missing, and correctly concludes 'Unknown'.
Key Novelty
Fully LLM-based Symbolic Chain-of-Thought (SymbCoT)
- Replaces the 'think step-by-step' heuristic with a structured translation-planning-solving pipeline where the LLM itself acts as the symbolic engine.
- Uses a hybrid context of natural language and symbolic expressions to capture both nuance and rigid logic.
- Incorporates a retrospective verifier that checks both the translation accuracy and the logical validity of the reasoning steps before finalizing the answer.
Architecture
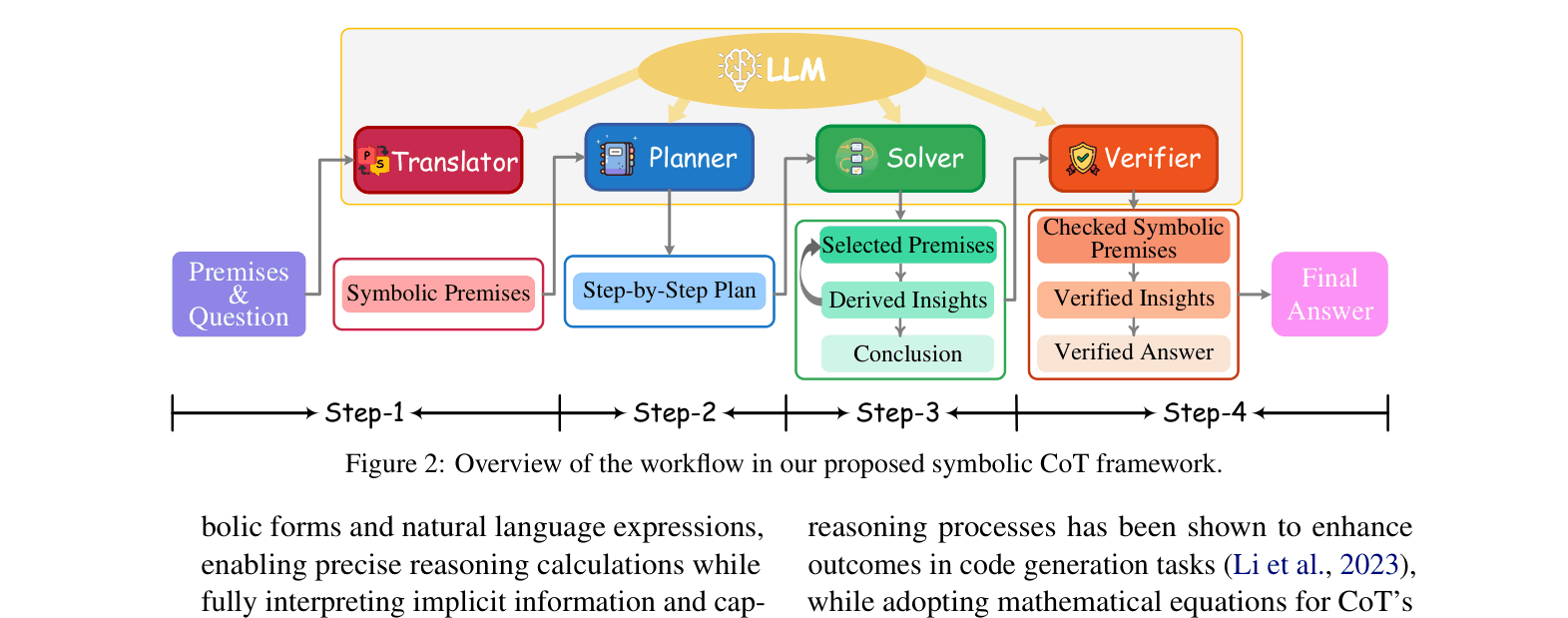
The SymbCoT workflow pipeline showing the four main modules interacting with the LLM.
Evaluation Highlights
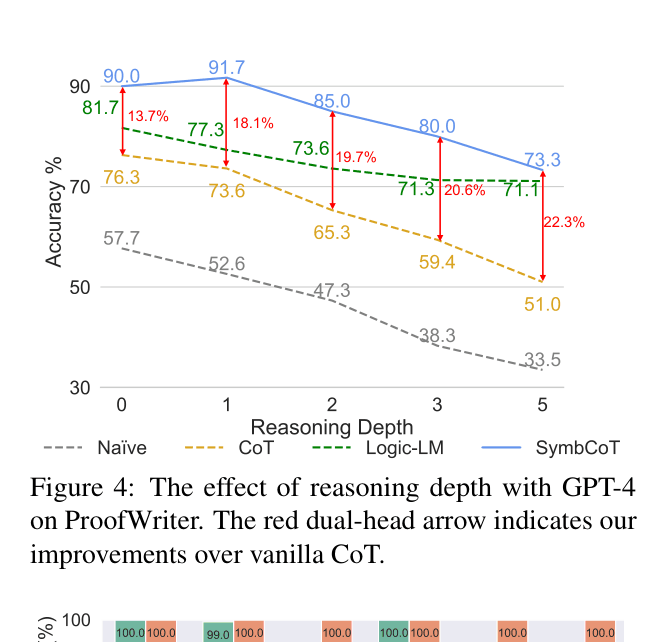
- Achieves 83.33% accuracy on FOLIO with GPT-4, outperforming the external-solver-based Logic-LM (78.92%) and CoT (70.58%).
- Attains 100% symbolic execution success rate on AR-LSAT, compared to only 67.4% for Logic-LM, demonstrating superior robustness to syntax errors.
- Outperforms CoT by +5.37% on LogicalDeduction (Constraint Optimization) using GPT-4, showing generalization across symbolic formats.
Breakthrough Assessment
8/10
Significantly advances neuro-symbolic reasoning by proving LLMs can effectively perform symbolic deduction without external tools, solving the 'brittle solver' bottleneck.