📝 Paper Summary
Chain-of-Thought Reasoning
Prompt Tuning / Soft Prompts
Efficient Fine-tuning
SoftCoT improves large language model reasoning by using a small, frozen assistant model to generate continuous soft thought tokens that guide the main model, avoiding full fine-tuning and catastrophic forgetting.
Core Problem
Existing methods for continuous-space reasoning (using internal latent states instead of words) require full-model fine-tuning, which causes catastrophic forgetting of general capabilities in state-of-the-art instruction-tuned models.
Why it matters:
- Current continuous reasoning methods (like Coconut) degrade the zero-shot performance of powerful models like LLaMA-3.1-8B-Instruct.
- Full fine-tuning is computationally expensive and risks overriding the model's pre-trained instruction-following abilities.
- Discrete Chain-of-Thought (CoT) is constrained by vocabulary space, while existing soft reasoning methods aren't applicable to modern instruction-tuned LLMs due to forgetting.
Concrete Example:
When fine-tuning LLaMA-3.1-8B-Instruct with the Coconut method (continuous reasoning), its accuracy on the GSM8K math benchmark drops significantly compared to standard zero-shot CoT, indicating catastrophic forgetting of its original reasoning capabilities.
Key Novelty
Assistant-Generated Soft Thoughts via Projection
- Uses a small, frozen assistant model (e.g., Llama-3.2-1B) to generate 'soft thoughts' (hidden states) specific to each problem instance.
- Trains a lightweight projection module to map these assistant states into the main LLM's embedding space, acting as instance-specific soft prompts.
- Keeps the main LLM frozen (or uses parameter-efficient tuning), preventing the catastrophic forgetting observed in prior continuous reasoning works.
Architecture
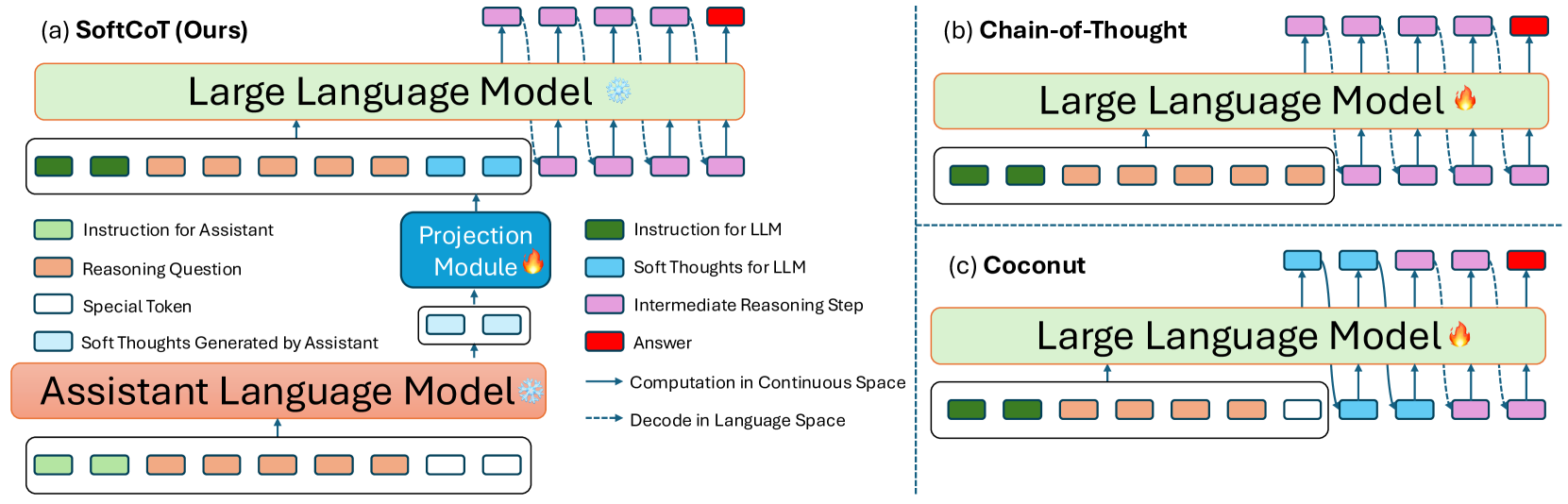
The SoftCoT framework illustrating the assistant model generating soft thoughts, the projection to the LLM space, and the final reasoning process.
Evaluation Highlights
- +3.4% average accuracy improvement over Zero-shot CoT on five reasoning benchmarks using Llama-3.1-8B-Instruct.
- Outperforms Coconut (a prior continuous reasoning method) by ~10% on GSM8K when applied to Llama-3.1-8B-Instruct, effectively mitigating catastrophic forgetting.
- Achieves superior performance on the newly constructed 'ASDiv-Aug' hard math dataset compared to standard prompting baselines.
Breakthrough Assessment
7/10
Effective solution to the specific problem of catastrophic forgetting in continuous reasoning. While not a paradigm shift in reasoning itself, it makes soft-prompting practical for modern instruction-tuned LLMs.