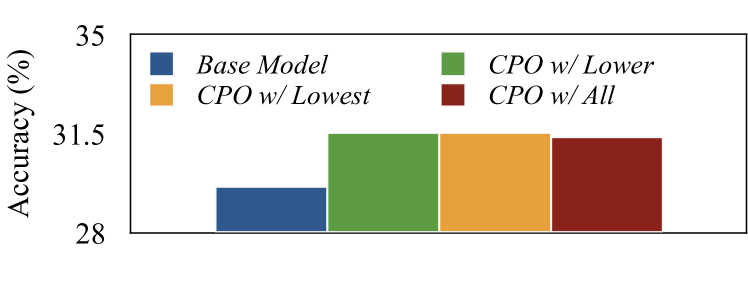📝 Paper Summary
Reasoning in Large Language Models
Alignment / Preference Optimization
CPO fine-tunes LLMs to internalize the optimal reasoning paths found by Tree-of-Thought search using Direct Preference Optimization on intermediate steps, boosting Chain-of-Thought performance without the inference cost.
Core Problem
Standard Chain-of-Thought (CoT) often overlooks optimal reasoning paths due to its single-path focus, while Tree-of-Thought (ToT) finds better paths but is computationally too expensive for practical inference.
Why it matters:
- ToT improves reasoning quality significantly but increases inference complexity by over 50x, making it impractical for real-time applications.
- Existing distillation methods only train on the final 'best' path, ignoring the valuable negative feedback (bad branches) explored during tree search.
- Current approaches overlook the preference information inherent in the tree structure: knowing which intermediate thoughts were discarded is as important as knowing which were kept.
Concrete Example:
In an arithmetic reasoning task, CoT might pursue a single incorrect calculation path. ToT would explore multiple branches, discard the incorrect calculation, and find the right one. Standard fine-tuning would just show the model the correct path. CPO explicitly teaches the model to prefer the correct step *over* the incorrect one at that specific junction.
Key Novelty
Chain of Preference Optimization (CPO)
- Constructs step-wise preference pairs from Tree-of-Thought search logs: thoughts in the final successful path are 'preferred' (winners), while rejected alternative branches at the same step are 'dispreferred' (losers).
- Applies Direct Preference Optimization (DPO) sequentially at each reasoning step, teaching the model not just *what* to think, but *which* thought to choose over alternatives.
- Allows the model to generate ToT-quality reasoning paths using standard greedy CoT decoding at inference time, effectively distilling the search tree into the model weights.
Architecture
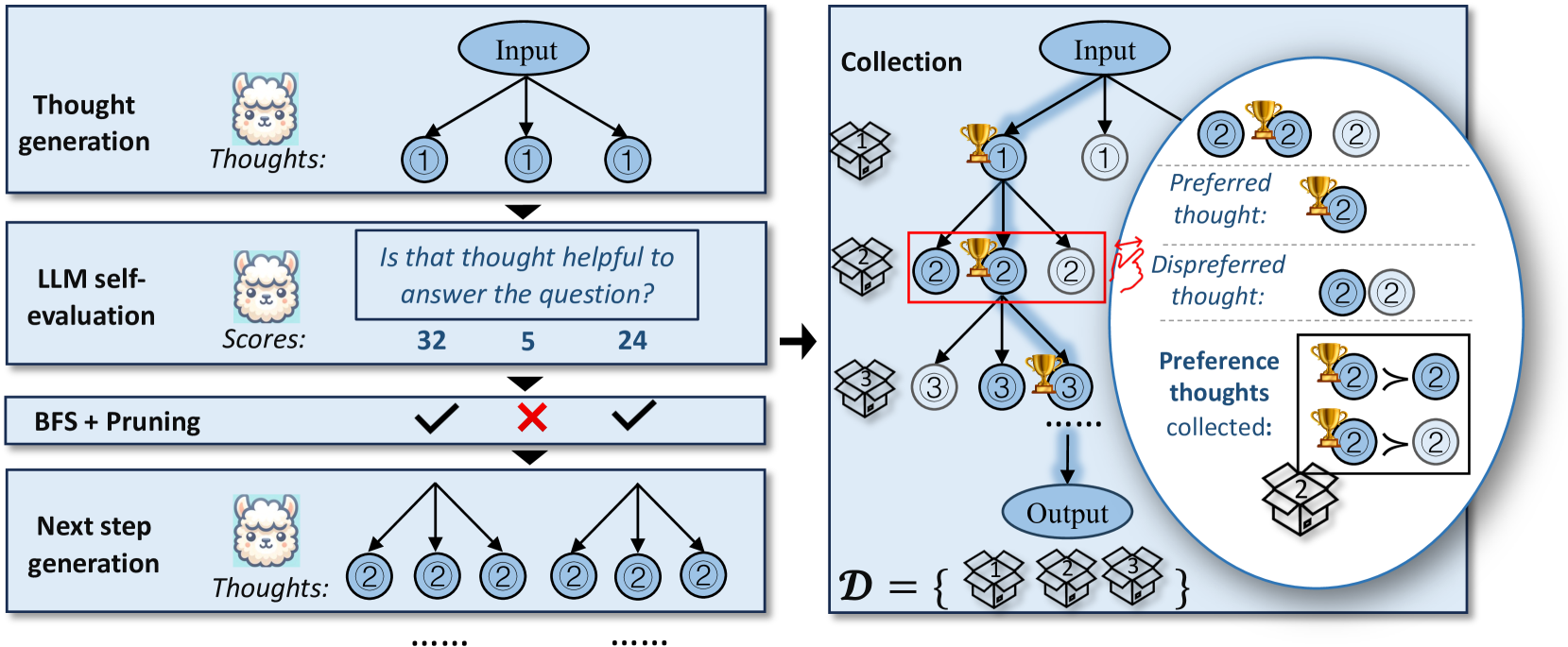
The CPO pipeline: Synthesizing preference thoughts from ToT and training via DPO.
Evaluation Highlights
- Achieves an average accuracy improvement of up to 4.3% compared to base models (LLaMA-2-7B/13B, Mistral-7B) across seven reasoning datasets.
- Matches or outperforms the heavy Tree-of-Thought (ToT) method while being >50x faster during inference (standard CoT decoding vs. tree search).
- Outperforms standard Supervised Fine-Tuning (SFT) and Rejection Sampling Fine-Tuning (RFT) on complex tasks like GSM8K and strategyQA.
Breakthrough Assessment
7/10
Cleverly combines ToT and DPO to solve the efficiency-performance trade-off in reasoning. It effectively extracts more signal from search trees (negatives) than prior distillation work.