📝 Paper Summary
Chain-of-Thought (CoT) Compression
Visual Latent Reasoning
Multimodal LLMs
Render-of-Thought compresses verbose textual reasoning into compact visual latent embeddings by rendering text as images and aligning the model's hidden states with a frozen vision encoder.
Core Problem
Chain-of-Thought (CoT) enhances reasoning but increases inference latency and memory cost due to verbosity; existing compression methods either lose information (sparse tokens) or create opaque, uninterpretable latent vectors.
Why it matters:
- Prolonged inference latency and excessive memory consumption hinder the scalability of LLMs for complex reasoning tasks.
- Existing latent reasoning methods often lack supervision on intermediate steps, making the reasoning process a 'black box' that is hard to analyze or debug.
- Purely linguistic compression techniques remain bound to sparse token representations, limiting the density of information that can be processed.
Concrete Example:
In explicit CoT, a math problem might require generating 108 tokens of text to reach an answer. Render-of-Thought condenses this entire reasoning path into just 32 visual latent tokens, reducing computational cost while maintaining the ability to trace the rationale via the aligned visual space.
Key Novelty
Render-of-Thought (RoT)
- Reifies reasoning by rendering textual Chain-of-Thought steps into images, leveraging the high information density of visual modalities for compression.
- Uses the frozen vision encoder of a VLM as a 'semantic anchor,' aligning the LLM's latent states with structured visual embeddings instead of learning reasoning tokens from scratch.
- Implements a two-stage training strategy: first aligning LLM states with visual embeddings, then fine-tuning for autoregressive generation of these visual tokens without explicit text decoding.
Architecture

The two-stage training pipeline for Render-of-Thought.
Evaluation Highlights
- Achieves 3-4x token compression on Qwen3-VL-4B-Instruct (32 latent tokens vs 108 explicit tokens) while maintaining 55.4% accuracy on GSM8k-Aug.
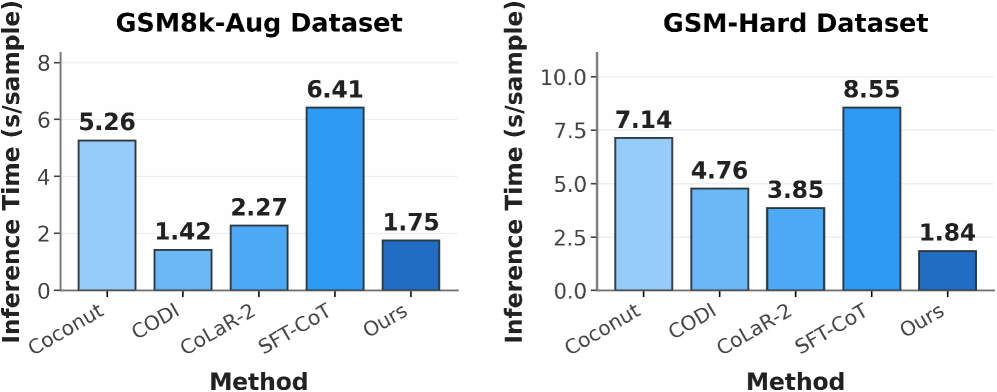
- Reduces inference time on the challenging GSM-Hard dataset from 8.55s (Explicit CoT) to 1.84s, a ~4.6x speedup.
- Outperforms the best LLM-based latent reasoning baseline (CoLaR-2) by 8.1% on average across four grade-school reasoning datasets.
Breakthrough Assessment
7/10
Novel paradigm of using visual rendering for CoT compression with significant efficiency gains. Solves the 'black box' issue of latent reasoning by grounding it in decodable visual semantics.