📝 Paper Summary
Multimodal Reasoning
Visual Question Answering (VQA)
Prompt Engineering
CCoT improves multimodal reasoning by prompting Large Multimodal Models to generate their own scene graphs as an intermediate reasoning step, without needing fine-tuning or external annotations.
Core Problem
State-of-the-art Large Multimodal Models (LMMs) often view images as a simple "bag of objects," failing to understand compositional relationships (attributes and spatial relations between objects).
Why it matters:
- Current models struggle with questions requiring precise spatial or attribute understanding (e.g., distinguishing a person *on* a horse vs. *beside* it)
- Existing solutions using Scene Graphs (SGs) typically require expensive ground-truth annotations which are not scalable
- Fine-tuning models on Scene Graph data can lead to catastrophic forgetting of the original pre-training objectives
Concrete Example:
Given an image of a desk, a standard LMM might list "laptop, mouse, books." However, it fails to describe exactly *how* they are situated (e.g., "a stack of books on a laptop"). CCoT generates a structured graph first to capture these relations before answering.
Key Novelty
Compositional Chain-of-Thought (CCoT)
- Zero-shot prompting strategy that forces the LMM to first generate a Scene Graph (SG) in JSON format containing objects, attributes, and relationships based on the image and task
- Uses this self-generated SG as an explicit context in a second prompt to answer the user's question, effectively creating a reasoning bridge between the visual input and the final textual response
Architecture
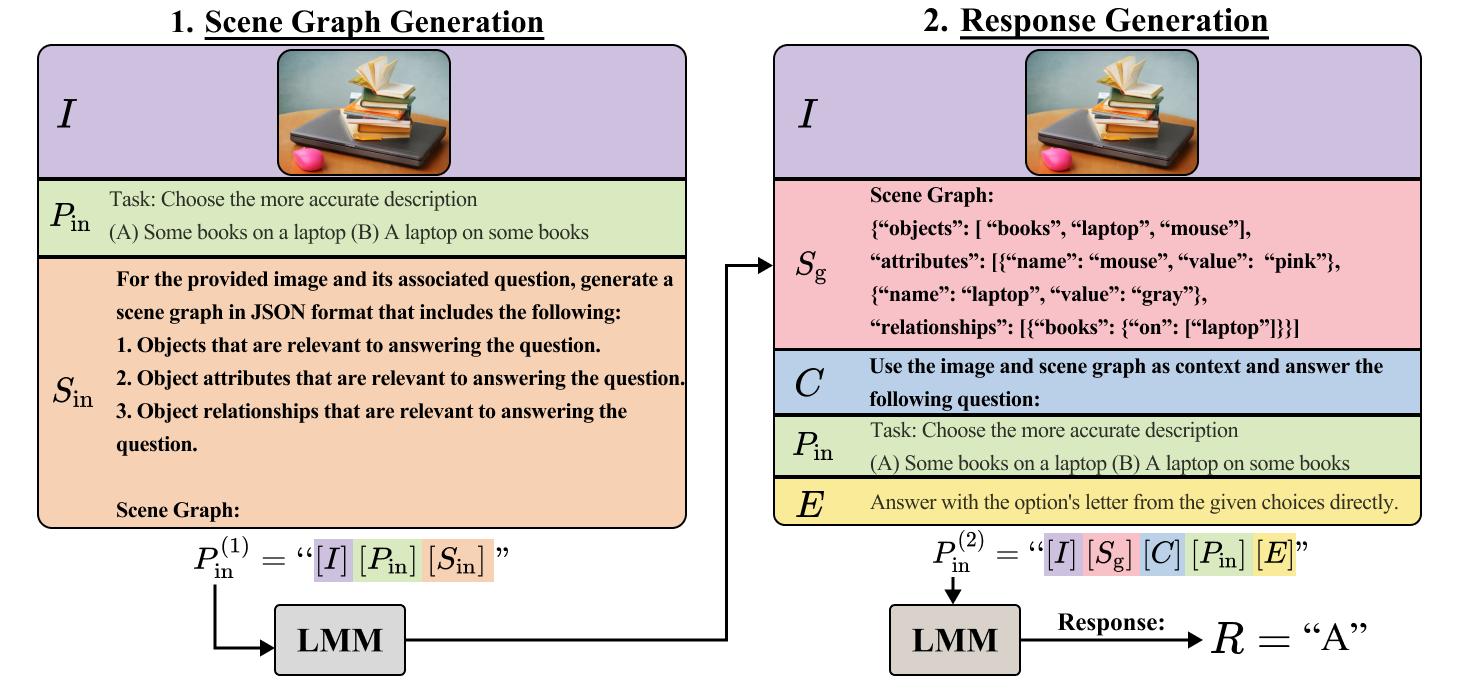
The CCoT inference pipeline: (1) Image + SG Generation Prompt creates a JSON Scene Graph. (2) Image + Original Prompt + Generated Scene Graph creates the Final Response.
Evaluation Highlights
- Significant improvement on Winoground (a compositional benchmark) using GPT-4V, outperforming the previous state-of-the-art (SGVL) which required fine-tuning on annotated scene graphs
- Consistently outperforms baseline zero-shot prompting and standard Chain-of-Thought (CoT) across LLaVA-1.5, InstructBLIP, SPHINX, and GPT-4V
- Improves performance on general multimodal benchmarks like SEEDBench and MMBench, not just compositional tasks
Breakthrough Assessment
8/10
Simple yet highly effective prompting strategy that solves a known LMM weakness (compositionality) without training or data costs. Demonstrates that structured intermediate representations work better than free-text reasoning for vision tasks.
