📝 Paper Summary
Chain-of-Thought Prompting
Neuro-symbolic Reasoning
Interpretability
Faithful CoT decouples reasoning into a translation stage (LLM generates a symbolic plan) and a problem-solving stage (deterministic solver executes the plan), guaranteeing the explanation causes the answer.
Core Problem
Standard Chain-of-Thought (CoT) prompting is unfaithful; the generated reasoning text does not necessarily cause the final answer, allowing models to hallucinate reasoning while guessing correct answers or vice versa.
Why it matters:
- Unfaithful explanations in high-stakes domains (e.g., legal, medical) mislead users into over-trusting the model based on plausible-looking but causally disconnected reasoning
- Standard CoT provides no guarantee that the model's stated logic is the actual mechanism producing the prediction
- Existing methods often conflate interpretability (faithfulness) with plausibility (convincingness), failing to provide true transparency
Concrete Example:
In a math problem about buying video games (Figure 1), standard CoT correctly calculates the intermediate value '$195' but concludes the final answer is '0', which contradicts its own reasoning chain. The explanation is hallucinated and unrelated to the output.
Key Novelty
Two-Stage Neuro-symbolic Decoupling
- Decomposes the reasoning process: The LLM acts solely as a translator from natural language queries to symbolic code (Python, Datalog, PDDL) interleaved with comments
- Delegates execution: The final answer is derived strictly by running the generated code with a deterministic external solver, ensuring the reasoning chain is the true cause of the answer
Architecture
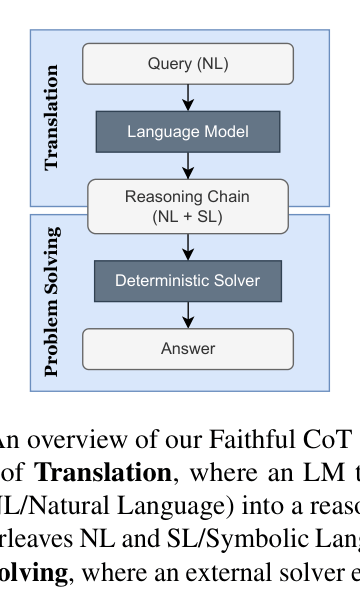
Overview of the Faithful CoT framework pipeline
Evaluation Highlights
- +21.7 percentage points accuracy gain on Date Understanding (Multi-hop QA) using code-davinci-002 with greedy decoding compared to standard CoT
- +14.2% relative accuracy improvement on Math Word Problems (GSM8K) compared to standard CoT, showing that enforcing faithfulness can also improve correctness
- Achieves 99.1% accuracy on Relational Inference (CLUTRR) with greedy decoding, outperforming standard CoT (48.5%) by a massive margin
Breakthrough Assessment
8/10
Strongly addresses the critical interpretability flaw of CoT (unfaithfulness) while simultaneously achieving SOTA results across diverse domains (Math, Logic, Planning) via neuro-symbolic integration.
