📝 Paper Summary
Mechanistic Interpretability
Prompt Engineering
This study reveals that while Chain-of-Thought reasoning heavily relies on pretrained priors, providing sufficient exemplars can override these priors (even with noise), and prompt engineering can induce reasoning-intensive "slow thinking" in smaller models.
Core Problem
The underlying mechanism of Chain-of-Thought (CoT) reasoning is unclear: it is debated whether models actually learn new reasoning skills from prompts (In-Context Learning) or merely retrieve latent knowledge (Pretrained Priors).
Why it matters:
- Current perspectives are conflicting: some argue models only imitate formats without learning logic, while others suggest they can learn novel mappings
- Understanding this balance is crucial for designing prompts that effectively leverage model capabilities without introducing hallucinations or instability
- Disentangling ICL from priors helps explain when and why CoT fails (e.g., under misleading prompts) or succeeds (e.g., reasoning emergence)
Concrete Example:
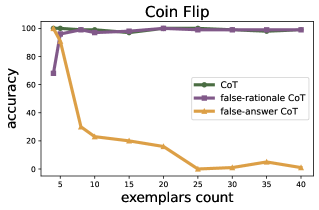
In a Coin Flip task (binary outcome), if a prompt contains exemplars with incorrect 'flipped' logic, does the model stick to its pretrained knowledge of coin physics, or does it copy the error? This paper shows 8B models *do* eventually copy the error and flip labels given enough noisy examples.
Key Novelty
Dual-Process Analysis of CoT (ICL vs. Priors)
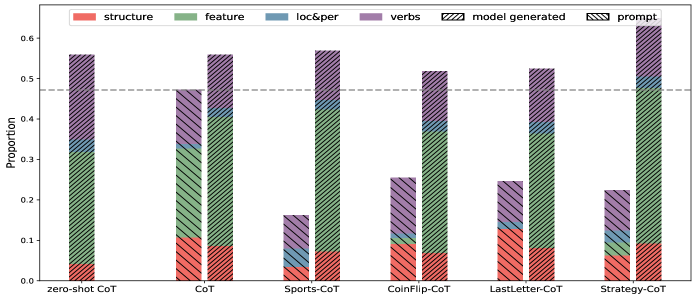
- Conducts fine-grained lexical analysis (counting verbs, structure words) to prove models mimic reasoning *structure* from prompts while relying on priors for *content*
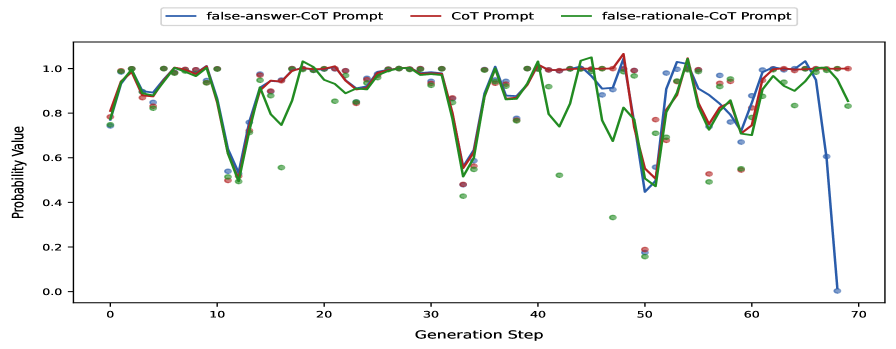
- Uses 'False-Answer' and 'False-Rationale' stress tests to quantify the exact point where ICL signals override pretrained semantic priors
- Demonstrates that 'slow thinking' (extended reasoning chains) can be induced in standard LLMs purely through prompt engineering, without architectural changes
Architecture
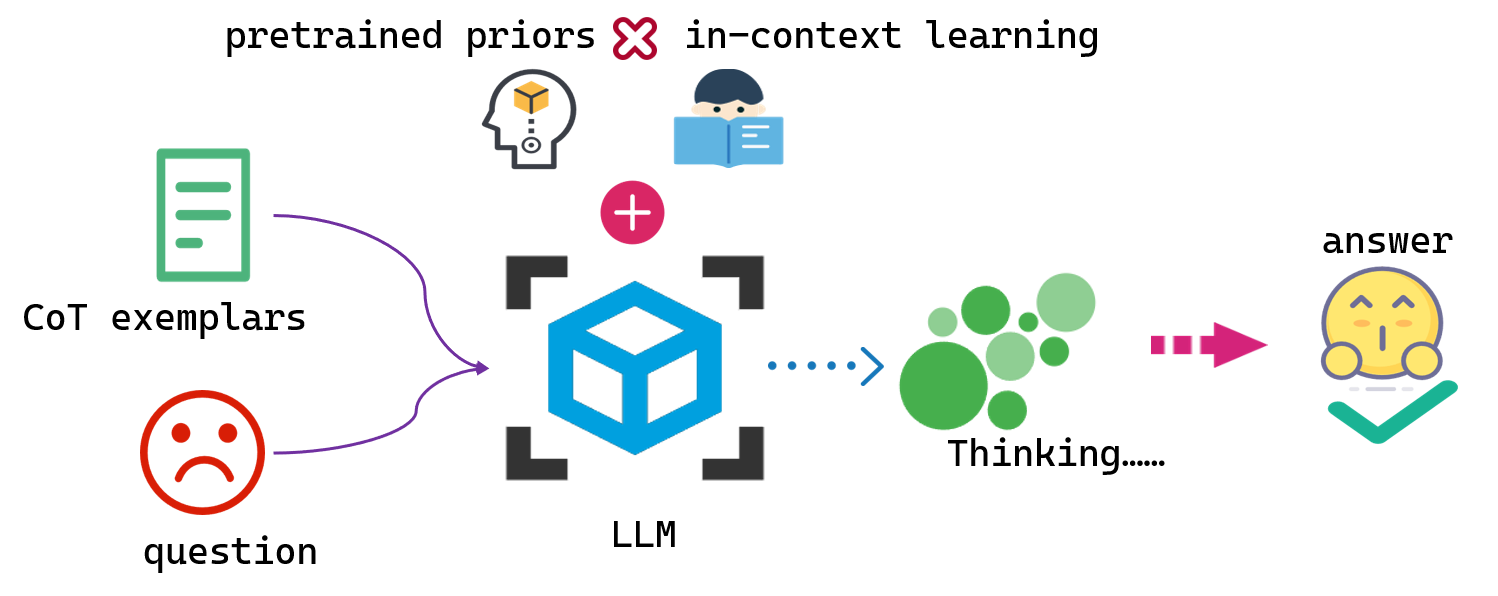
Conceptual diagram illustrating the dual interaction between In-Context Learning (ICL) and Pretrained Priors during Chain-of-Thought reasoning.
Evaluation Highlights
- In open-domain tasks (GSM8K, Date Understanding), providing 40 noisy/incorrect exemplars causes reasoning accuracy to drop by nearly half, showing ICL eventually overpowers priors.
- Contradicting prior beliefs, smaller models (8B) *can* learn to systematically flip labels in closed-domain tasks (Coin Flip) when provided with sufficient counter-factual CoT exemplars.
- Reasoning performance correlates with the density of 'reasoning verbs' in the output; optimal verb counts exist, beyond which performance degrades.
Breakthrough Assessment
7/10
Provides strong empirical evidence resolving conflicts about CoT mechanisms (imitation vs. learning) and successfully demonstrates induced 'slow thinking' via prompting, though it relies on analysis of existing models rather than a new architecture.