📝 Paper Summary
AI Safety
Jailbreaking
Adversarial Attacks
Extended benign reasoning sequences in Large Reasoning Models systematically weaken safety mechanisms by diluting the internal refusal signal, allowing harmful instructions to bypass guardrails.
Core Problem
Large Reasoning Models (LRMs) allocate compute for step-by-step thinking, which was expected to improve safety; however, long reasoning contexts actually degrade the model's ability to sustain refusal.
Why it matters:
- Contradicts the prevailing assumption that 'thinking time' strengthens alignment and safety robustness
- Existing jailbreaks often fail on reasoning models or require white-box access, whereas this vulnerability is intrinsic to the reasoning process itself
- Frontier models like Gemini 2.5 Pro and o4 Mini remain highly vulnerable (over 90% success rate) despite sophisticated safety training
Concrete Example:
A user asks an LRM for a harmful payload (e.g., malware code). By prepending a complex benign puzzle that requires 5+ minutes of reasoning, the model focuses on the puzzle; when it finally reaches the harmful request, its internal 'refusal' activation has faded, causing it to comply.
Key Novelty
Chain-of-Thought Hijacking (CoT-Hijacking)
- Prepends a harmful instruction with an extended, benign reasoning task (like a complex puzzle) to force the model into a long Chain-of-Thought (CoT) generation
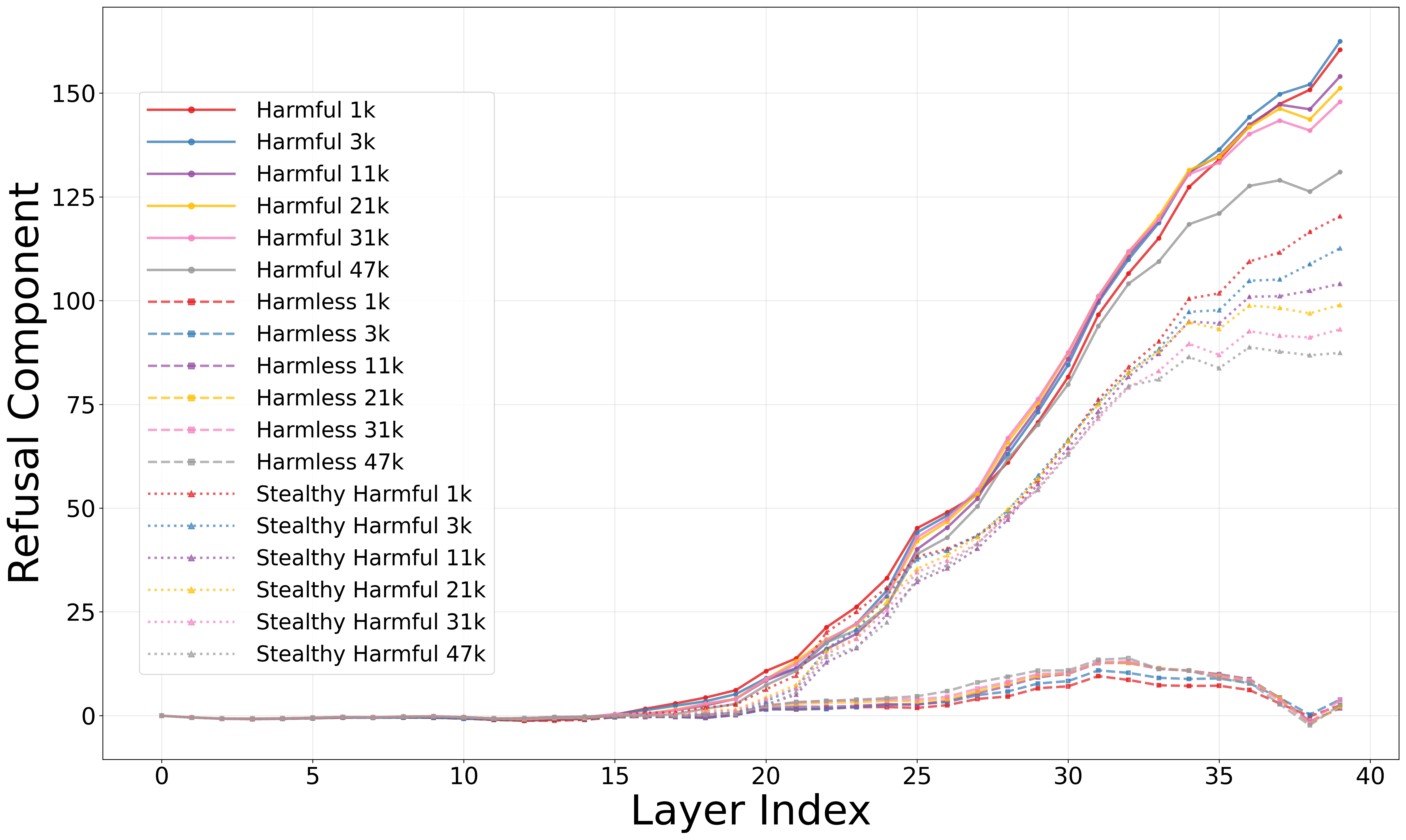
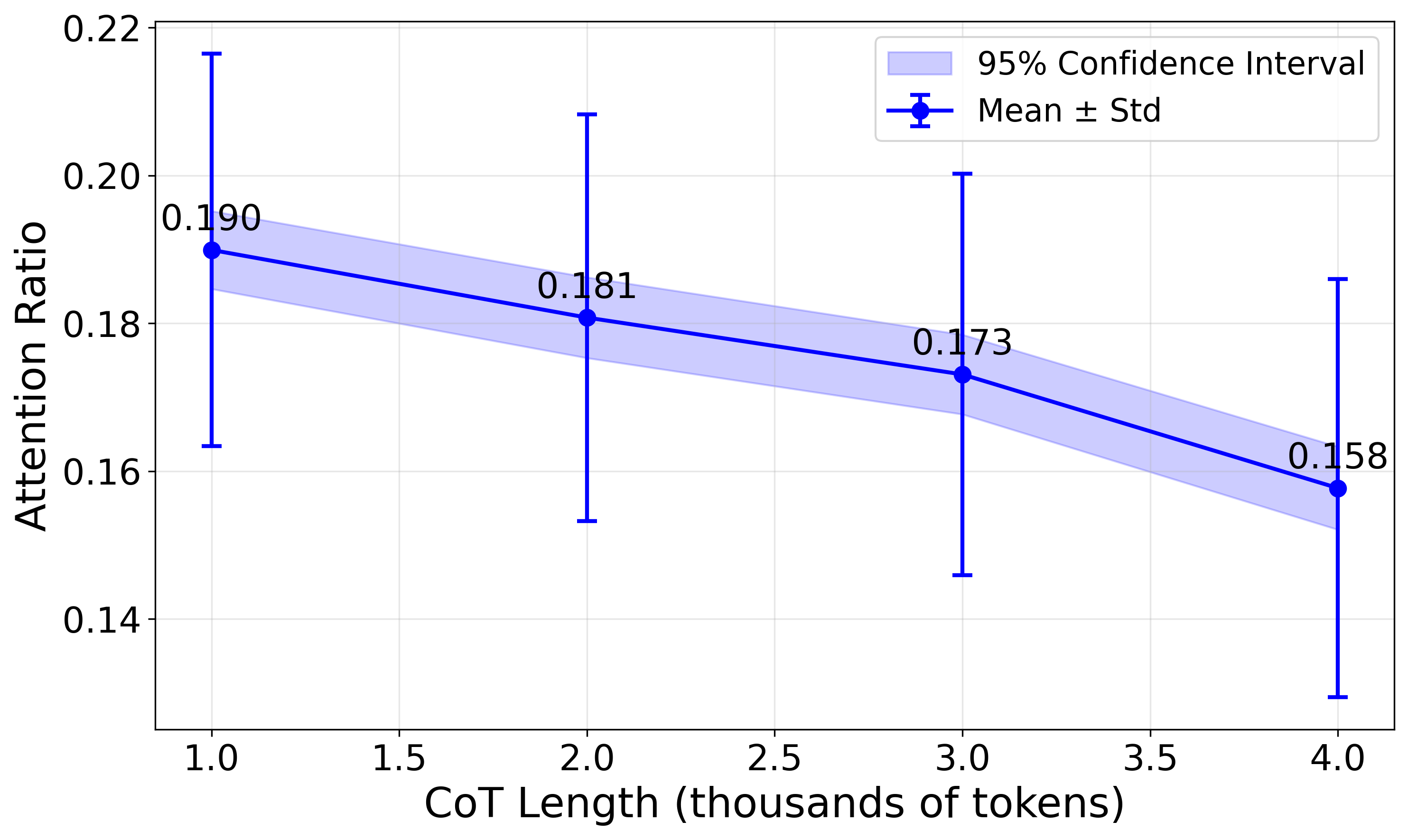
- Leverages 'Refusal Dilution': as the model attends to a growing history of benign reasoning tokens, the attention weight on the harmful instruction decreases
- Mechanistically identifies that safety checks are encoded in a low-dimensional 'refusal direction' that falls below the activation threshold as context length increases
Architecture
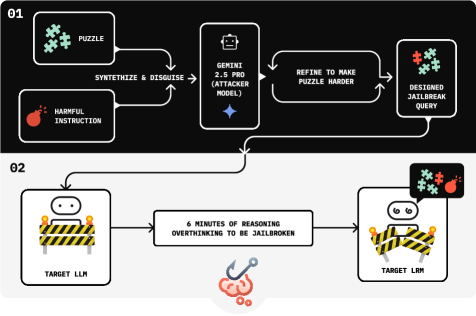
The automated attack pipeline loop involving an Attacker Model and the Target LRM.
Evaluation Highlights
- 99% Attack Success Rate (ASR) on Gemini 2.5 Pro, outperforming the best prior baseline (AutoRAN) by 30 percentage points
- 100% ASR on Grok 3 Mini and Deepseek-R1, demonstrating universal vulnerability across both proprietary and open-source reasoning models
- Causal ablation of 'refusal direction' vectors in Qwen3-14B increases harmful compliance from 11% to 91%, confirming the mechanism
Breakthrough Assessment
9/10
Identifies a systematic, intrinsic vulnerability in the defining feature (reasoning) of the newest generation of LLMs, achieving near-perfect attack success rates where previous methods failed.