📝 Paper Summary
Chain-of-Thought (CoT) Reasoning
Instruction Tuning
Knowledge Distillation
LogiCoT enhances the logical reasoning capabilities of smaller open-source language models by fine-tuning them on high-quality chain-of-thought rationales distilled from GPT-4 across diverse logical tasks.
Core Problem
General instruction-tuned models (like Alpaca) improve general proficiency but struggle significantly with complex, multi-step logical reasoning tasks compared to proprietary models like GPT-4.
Why it matters:
- Current open-source community models lack robust logical deduction skills, inhibiting their use in complex real-world reasoning scenarios.
- Developing proprietary reasoning models requires massive undisclosed data/engineering; distilling this capability into smaller models is a cost-effective alternative.
Concrete Example:
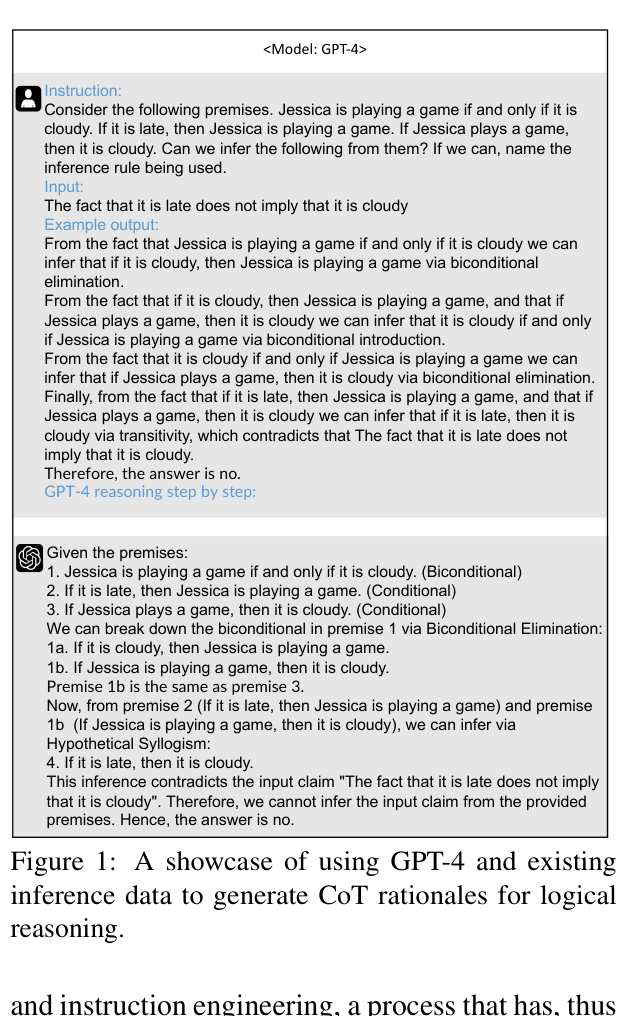
Given premises 'Jessica plays if and only if it is cloudy' and 'It is late implies Jessica plays', a standard model might fail to deduce 'It is late implies it is cloudy'. LogiCoT teaches the model to explicitly output 'via Biconditional Elimination... via Hypothetical Syllogism' to reach the correct conclusion.
Key Novelty
Logical Chain-of-Thought Distillation
- Constructs a dataset by repurposing existing logical benchmarks (symbolic and narrative) and prompting GPT-4 to act as a 'teaching assistant' that generates step-by-step rationales.
- Introduces specific instruction types (e.g., Language-to-Logic, Inference Chains, Argument Strengthening) to force the model to learn structured logical transitions.
Architecture
The data construction and instruction tuning pipeline.
Evaluation Highlights
- +32.2% accuracy improvement on LogiQA 2.0 (logical reading comprehension) compared to the LLaMA-7b-base model.
- Outperforms the larger LLaMA-30b-supercot model on 6 out of 8 logical reasoning datasets, despite having fewer parameters.
- Achieves parity with ChatGPT on English logical reasoning tasks like ReClor (57.60% vs 57.38%) and LogiQA OOD (38.79% vs 38.44%).
Breakthrough Assessment
7/10
Significant performance jump on specific logic tasks for a small 7B model. Demonstrates high utility of domain-specific CoT distillation, though it still lags behind GPT-4.