📝 Paper Summary
Safe Reinforcement Learning (SafeRL)
Model-Based Reinforcement Learning
Nightmare Dreamer uses a learned world model to 'dream' potential future safety violations, proactively switching between a reward-maximizing control actor and a safety-focused actor to maintain zero constraint violations.
Core Problem
Reinforcement Learning agents often adopt dangerous behaviors during exploration, and existing safe RL methods either struggle with sample efficiency (model-free) or fail to fully exploit world models for proactive safety planning (model-based).
Why it matters:
- Deployment in safety-critical real-world environments (autonomous vehicles, industrial robotics) requires strict adherence to safety constraints, which standard RL cannot guarantee.
- Model-free safe RL methods like CPO and PPO-Lagrangian are sample inefficient and struggle with high-dimensional visual inputs.
- Existing model-based methods often treat safety reactively rather than using the model to proactively anticipate and avoid future violations.
Concrete Example:
In a navigation task where a robot must avoid hazards, a standard agent might only learn to avoid a hazard after hitting it multiple times. Nightmare Dreamer simulates future trajectories in its 'dreams'; if it predicts a collision 5 steps ahead, it switches to a safety policy immediately, preventing the collision before it happens.
Key Novelty
Bi-Actor Architecture with Predictive Safety Planning
- Maintains two separate policies: a Control Actor (maximizes reward) and a Safe Actor (satisfies constraints via Lagrangian relaxation).
- Uses a learned world model to simulate ('dream') future trajectories from the current state; if the predicted cost of the Control Actor's path exceeds a safety budget, the system proactively switches to the Safe Actor.
- Trains the Safe Actor using a discriminator-based regularization that encourages it to mimic the Control Actor's behavior insofar as it remains safe, rather than just minimizing cost.
Architecture
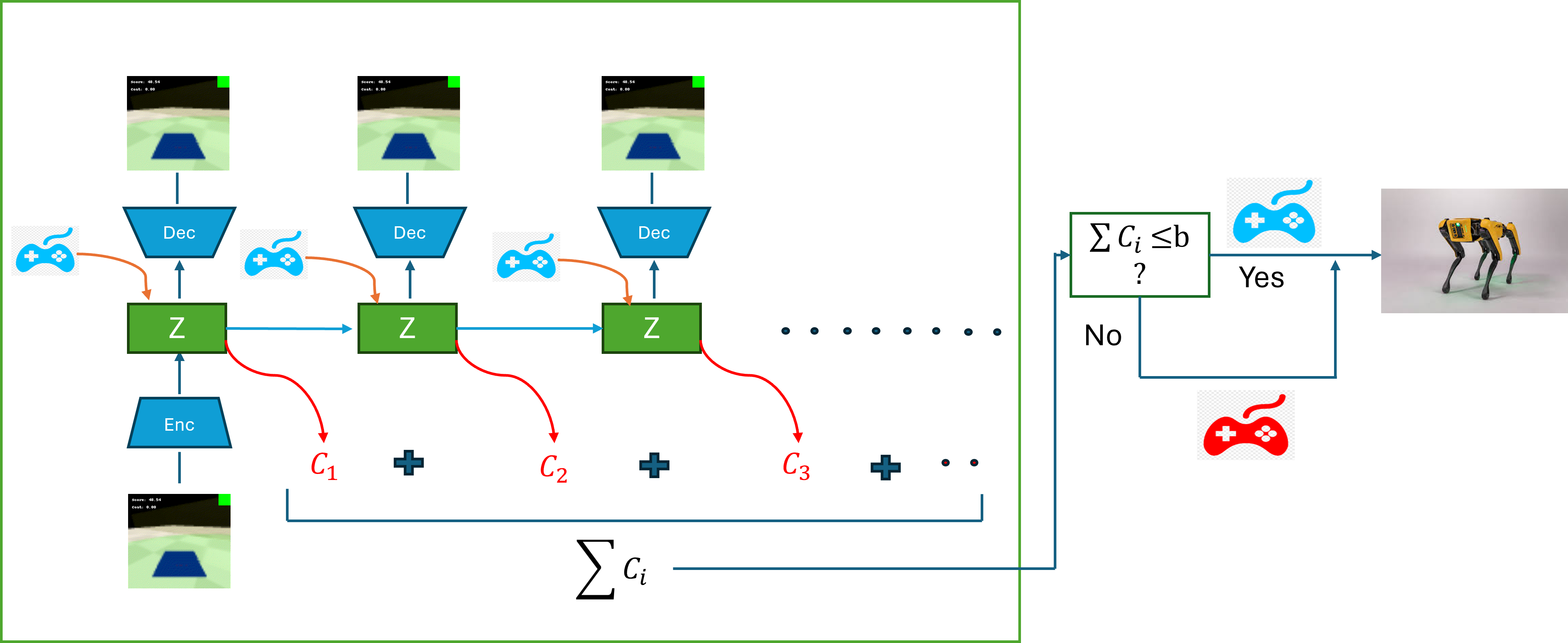
Conceptual flow of the Action Selection process using the World Model.
Evaluation Highlights
- Achieves nearly zero safety violations on Safety Gymnasium tasks while maximizing rewards, outperforming baselines that frequently violate constraints.
- Demonstrates ~20x improvement in sample efficiency compared to model-free baselines (PPO-Lagrangian, CPO), reaching convergence in 1e6 steps vs 1e7.
- Outperforms state-of-the-art model-based methods like Safe-Dreamer in convergence speed and stability on visual inputs.
Breakthrough Assessment
8/10
Significantly improves sample efficiency and safety guarantees in visual domains by effectively combining world models with a dual-policy switching mechanism. The proactive 'dreaming' for safety is a strong conceptual advance.