📝 Paper Summary
Synthetic Tabular Data Generation
Logical Consistency in Data Synthesis
LLM-TabLogic uses Large Language Models to extract and compress logical rules from tabular data, then conditions a score-based diffusion model to generate synthetic data that strictly adheres to these rules.
Core Problem
Existing generative models for tabular data focus on global statistical properties but fail to maintain domain-specific logical consistency between columns.
Why it matters:
- Industrial applications (e.g., supply chains) require data to follow strict rules, such as delivery dates occurring after order dates.
- Synthetically generated data without logical consistency lacks real-world utility for simulation and decision-making.
- Current methods like GANs and Diffusion models struggle with discrete logical constraints, while LLMs are too slow for efficient large-scale generation.
Concrete Example:
In a logistics dataset, a standard diffusion model might generate a row where 'Delivery Date' is before 'Order Date', or a retail record where 'Total Price' does not equal 'Unit Price' × 'Quantity'. LLM-TabLogic enforces these constraints explicitly.
Key Novelty
LLM-Reasoning Guided Diffusion
- Uses an LLM as a 'relational conditioner' to infer, compress, and structurally encode logical dependencies (hierarchical, mathematical, temporal) from table metadata.
- Decouples deterministic logic from probabilistic generation: rigid rules are handled by the LLM-derived compressor, while the diffusion model learns the remaining latent distribution.
- Introduces a decompression phase that reconstructs the full data using the preserved logic, ensuring 100% consistency for deterministic relationships.
Architecture
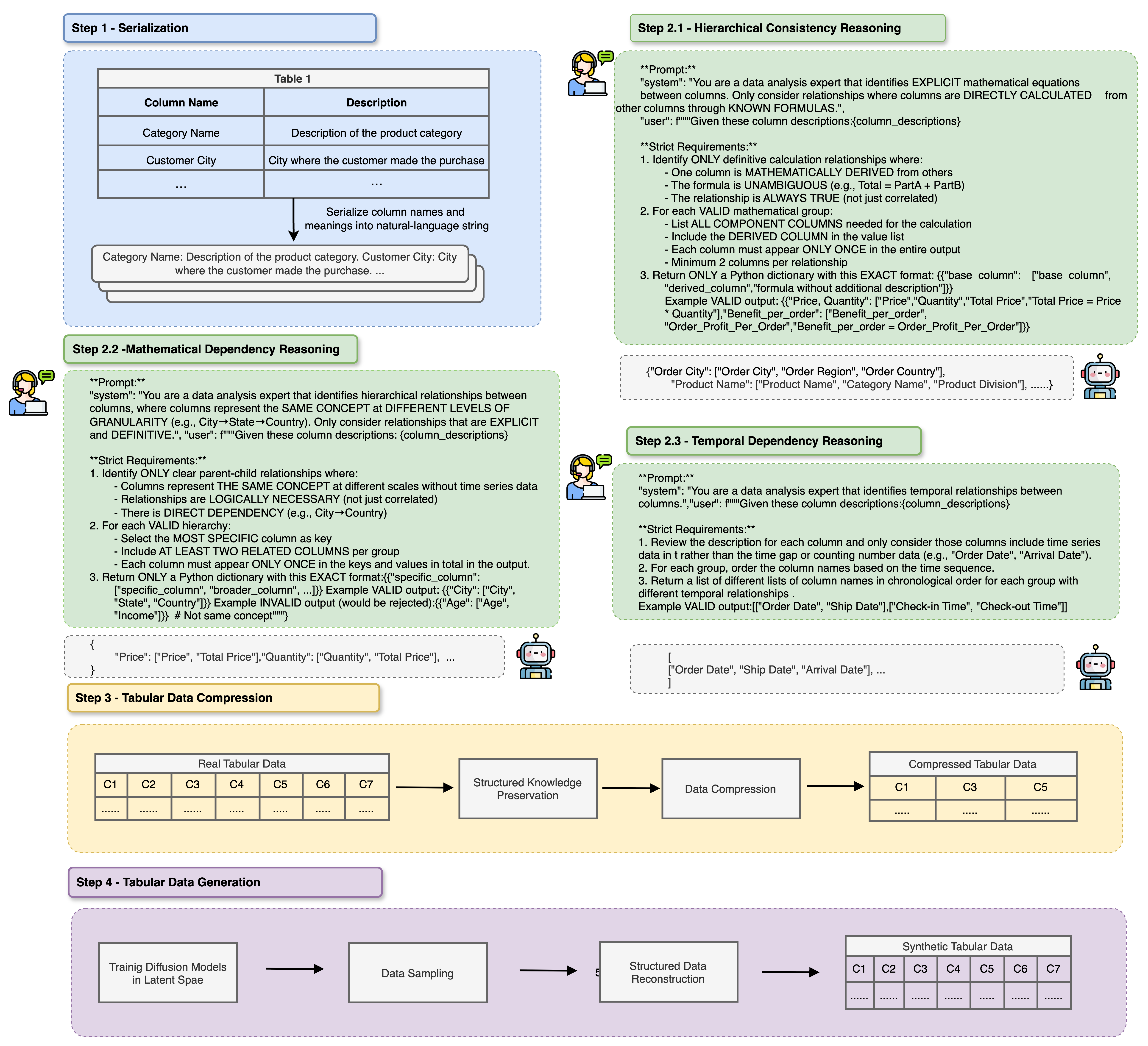
The workflow of LLM-TabLogic, showing the serialization of data, LLM reasoning to extract logic, compression into latent space, diffusion training, and final reconstruction.
Evaluation Highlights
- Achieves over 90% accuracy in logical inference on unseen tables, demonstrating strong generalization in capturing inter-column rules.
- Outperforms state-of-the-art baselines (including TabSyn and GReaT) across data fidelity, utility, and privacy metrics on real-world industrial datasets.
- Specifically preserves complex logical constraints that other methods violate, such as mathematical formulas and temporal sequences.
Breakthrough Assessment
8/10
Significant step forward in making synthetic tabular data usable for operations research by explicitly solving the logical inconsistency problem, which is often ignored by purely statistical generative models.