📝 Paper Summary
Hierarchical Planning
Robotic Manipulation
Foundation Models
HiP solves long-horizon robotic tasks by chaining independently trained language, vision, and action foundation models, using iterative refinement classifiers to ensure the output of one model is feasible for the next.
Core Problem
Solving long-horizon tasks in novel environments requires hierarchical reasoning across language, vision, and control, but collecting paired data across all three modalities is expensive and unscalable.
Why it matters:
- End-to-end training requires massive, expensive paired language-vision-action datasets that are hard to scale
- Existing methods that fine-tune large language models (LLMs) on robot data face barriers because top-tier model weights (e.g., GPT-4) are often closed-source
- Naïve composition of independent models fails because abstract plans (language) may generate subgoals that are physically impossible in the current visual environment
Concrete Example:
If a language model suggests 'pick up the kettle from the cabinet', but the video model sees no cabinet in the current room, a naïve chain will fail. HiP uses feedback to reject this plan before attempting execution.
Key Novelty
Iterative Refinement for Compositional Foundation Models (HiP)
- Decomposes planning into three independently trained experts: Language (Task), Video Diffusion (Visual), and Inverse Dynamics (Action), avoiding the need for paired tri-modal data
- Introduces 'iterative refinement' where lightweight classifiers act as critics, using feedback from downstream models (e.g., 'is this video executable?') to guide the sampling of upstream models (e.g., 'generate a better video')
Architecture
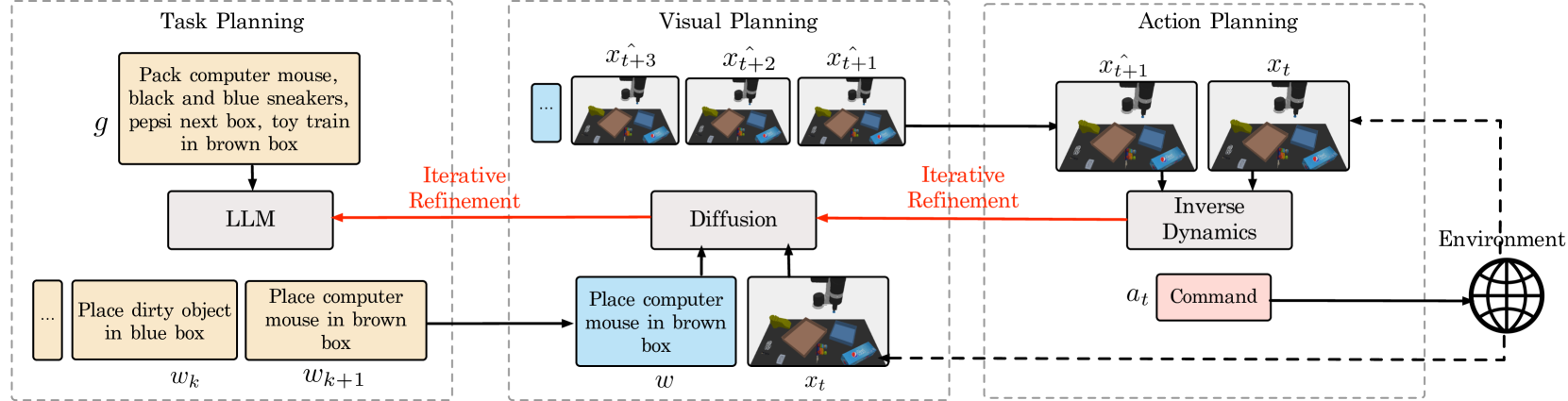
The hierarchical architecture of HiP. It shows the flow from Language Goal -> Task Planner -> Visual Planner -> Action Planner, with backward feedback loops for refinement.
Evaluation Highlights
- Demonstrates efficacy on three distinct long-horizon table-top manipulation tasks involving multi-step reasoning
- Approach works with models that offer only API access, as the refinement mechanism trains separate classifiers rather than fine-tuning the large foundation models themselves
Breakthrough Assessment
7/10
Offers a pragmatic, modular solution to the data scarcity problem in robotics by leveraging Internet-scale pre-training without requiring expensive end-to-end paired data.