📝 Paper Summary
Mathematical Reasoning
Self-Improvement / Self-Correction
The paper proposes a self-rewarding pipeline where language models generate their own training data by performing step-by-step reasoning and acting as a judge for individual steps, enabling iterative improvement in mathematical reasoning.
Core Problem
Existing self-rewarding methods work well for instruction following but fail or degrade performance in mathematical reasoning because outcome-based rewards are too coarse for complex, multi-step problems.
Why it matters:
- Reliance on human-annotated preference data is expensive and constrained by human performance limits.
- Current self-rewarding paradigms often lead to performance decline in math tasks as iterations increase.
- Assigning a single score to a complex long-thought solution is difficult and has low consistency compared to step-wise verification.
Concrete Example:
In standard self-rewarding, a model might generate a long math solution that is mostly correct but fails at step 5. If the final answer is wrong, the whole chain is penalized equally, or if the answer is coincidentally correct (false positive), the bad logic is reinforced. This lack of granularity prevents effective learning.
Key Novelty
Process-based Self-Rewarding (Step-wise Judge + Step-wise DPO)
- Integrates 'LLM-as-a-Judge' at the individual reasoning step level, rather than judging the final answer.
- Uses Monte Carlo Tree Search (MCTS) guided by the model's own step-wise judgments to generate preference pairs (best vs. worst steps).
- Applies step-wise Direct Preference Optimization (DPO) to iteratively refine the model's reasoning process.
Architecture
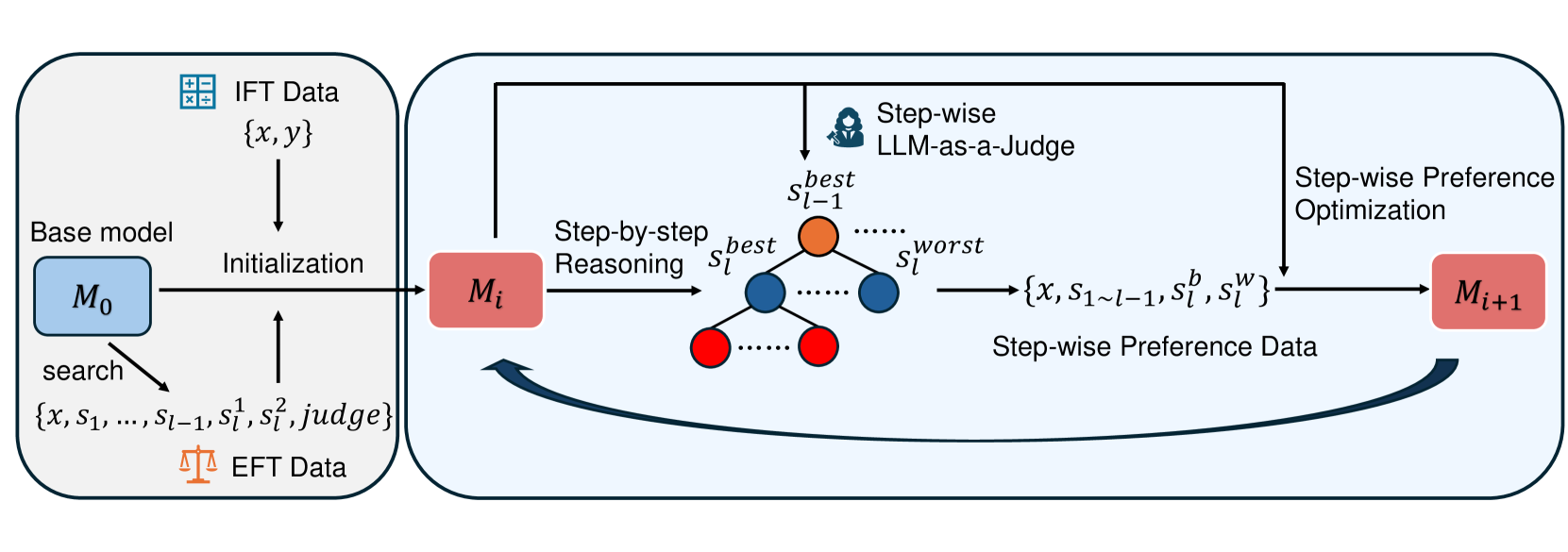
The iterative training pipeline of Process-based Self-Rewarding Language Models.
Evaluation Highlights
- Process-based Self-Rewarding outperforms the base model significantly on mathematical benchmarks (e.g., +6.8% on GSM8K, +3.7% on MATH for 7B model).
- Demonstrates iterative improvement: performance consistently increases across multiple self-rewarding iterations (M0 -> M1 -> M2 -> M3).
- The method improves both mathematical reasoning capability and the model's ability to act as a judge (meta-rewarding capability).
Breakthrough Assessment
8/10
Significantly addresses the failure of previous self-rewarding methods in math domains by shifting to process supervision. The iterative gains without external supervision are a strong signal for super-human scaling potential.