📝 Paper Summary
Vision-Language-Action (VLA) Models
Embodied Chain-of-Thought Reasoning
VLA-Thinker enables robots to actively query visual information during reasoning via tool use, optimizing this interleaved process with reinforcement learning for robust long-horizon manipulation.
Core Problem
Existing VLA models encode visual observations once as static context, decoupling perception from the reasoning process and preventing the model from resolving ambiguities or recovering from errors in long-horizon tasks.
Why it matters:
- Static visual encoding limits a robot's ability to handle evolving environments where initial observations become outdated or insufficient.
- Current approaches struggle with long-horizon manipulation because they cannot actively 're-look' to track subgoals or verify intermediate states.
- Learning a direct perception-to-action mapping requires massive demonstrations; reasoning-based approaches need to be grounded in active visual evidence to be effective.
Concrete Example:
In a long-horizon task like 'organizing household objects', a standard VLA might fail if an object shifts slightly after the initial observation because it relies on the static starting image. VLA-Thinker can pause, invoke a 'ZOOM-IN' tool to inspect the new state, and adjust its plan.
Key Novelty
Thinking-with-Image Reasoning Framework
- Reformulates VLA reasoning as an iterative loop where visual perception is a dynamically invocable action (e.g., Zoom-In) rather than just a passive input.
- Treats the reasoning process as a trajectory of (Thought, Tool, Observation, Action), allowing the model to interleave text generation with active visual queries.
Architecture

Comparison between traditional text-based VLA reasoning (left) and the proposed VLA-Thinker approach (right) which uses active visual queries.
Evaluation Highlights
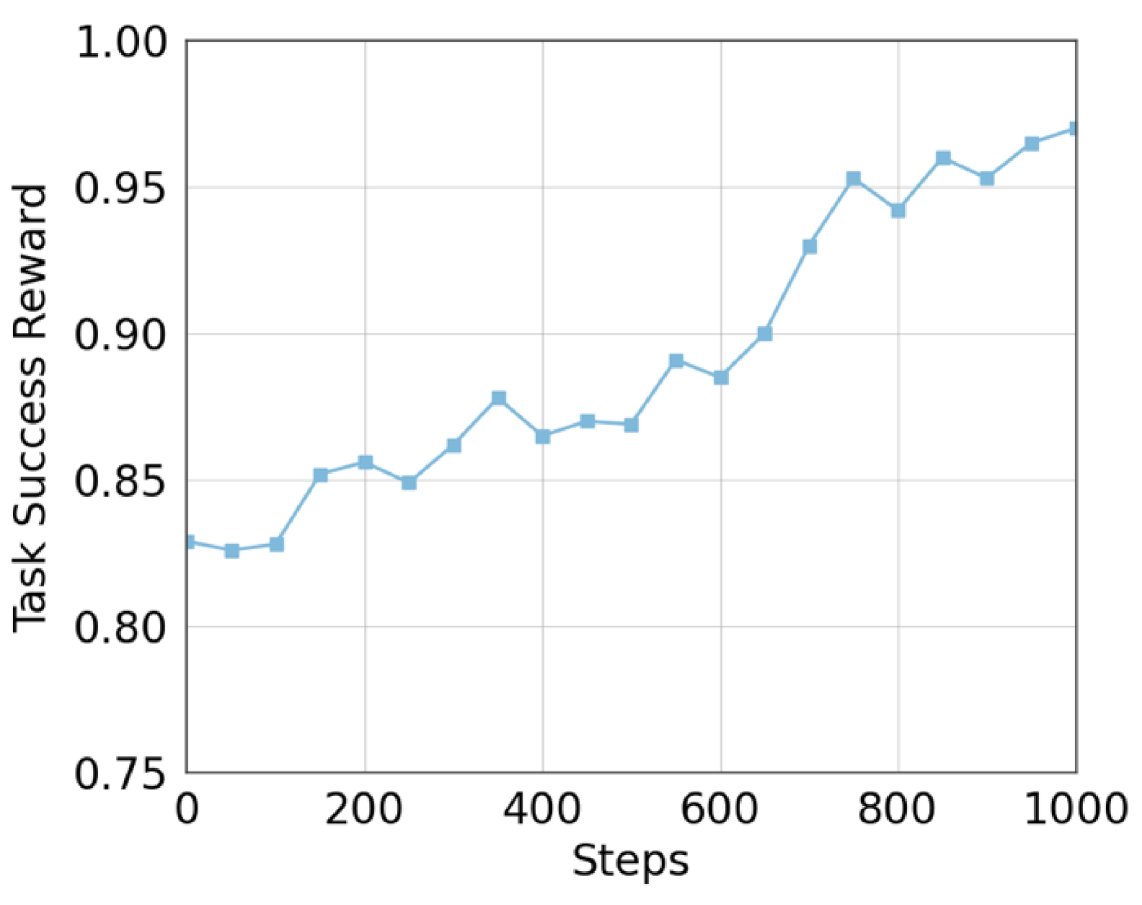
- Achieves 97.5% average success rate on the LIBERO benchmark, surpassing the OpenVLA-OFT backbone by 6.5%.
- Attains 64.6% success on RoboTwin 2.0 long-horizon tasks (280-650 steps), significantly outperforming OpenVLA-OFT (21.3%).
- Demonstrates 99.0% success on the LIBERO-Object suite, showing robust object manipulation capabilities.
Breakthrough Assessment
8/10
Successfully introduces active perception into the VLA reasoning loop with a novel RL integration (GRPO), yielding state-of-the-art results on standard benchmarks. The shift from static to active visual reasoning is a significant methodological step.