📝 Paper Summary
Efficient Reasoning
Large Reasoning Models (LRMs)
This survey systematically categorizes techniques for reducing the computational overhead of Chain-of-Thought reasoning in Large Language Models without sacrificing problem-solving accuracy.
Core Problem
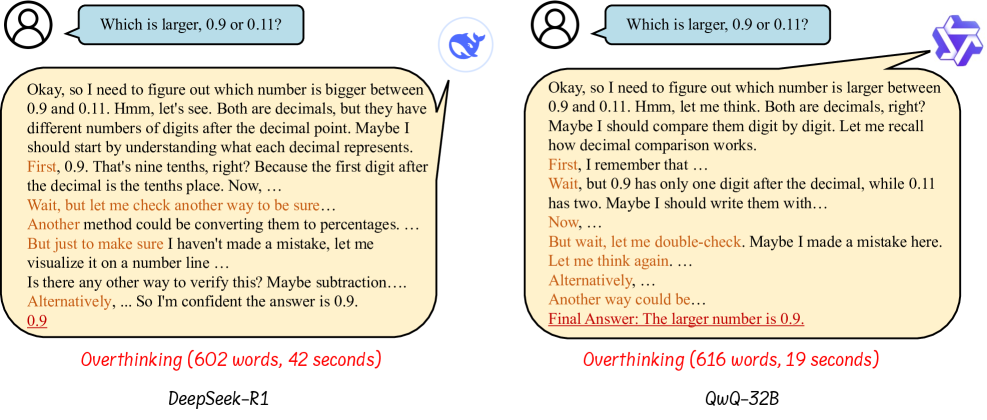
Large Reasoning Models (LRMs) like OpenAI o1 often exhibit the 'overthinking phenomenon,' generating verbose and redundant reasoning steps that increase inference costs and latency.
Why it matters:
- The verbosity of reasoning models (e.g., thousands of tokens for simple math) makes them prohibitively expensive and slow for real-time applications like autonomous driving or robotics
- Pre-training incentives often correlate longer reasoning with better performance, creating a tension where efficiency requires working against standard training objectives
- Current reasoning models lack mechanisms to dynamically adjust effort, spending excessive compute on trivial queries
Concrete Example:
When asked 'what is the answer of 2 plus 3?', smaller reasoning models may generate thousands of tokens of step-by-step derivation before outputting '5', wasting computational resources on a trivial task.
Key Novelty
Taxonomy of Efficient Reasoning
- Categorizes efficiency methods into three pillars: Model-based (optimizing the model itself via RL or SFT), Output-based (compressing steps dynamically during inference), and Prompt-based (guiding efficiency via inputs)
- Distinguishes 'efficient reasoning' (smart, concise thought processes) from traditional 'model compression' (quantization, pruning), focusing on reducing the reasoning length rather than model parameters
Architecture
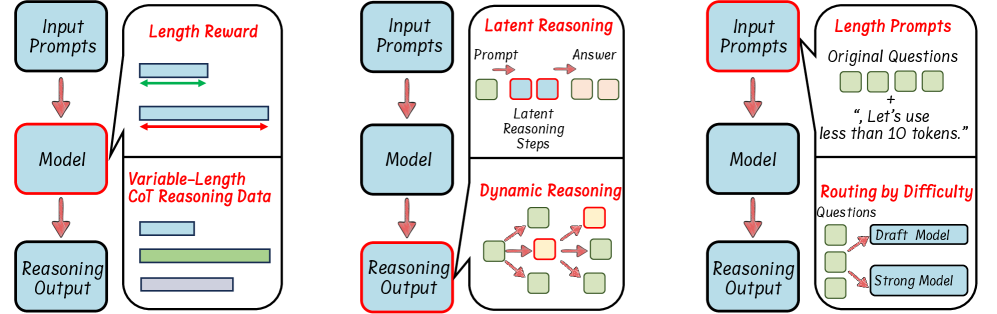
Taxonomy of Efficient Reasoning approaches
Evaluation Highlights
- Reviews RL methods that integrate length-based rewards (e.g., O1-Pruner, L1) to penalize verbosity while maintaining accuracy
- Discusses SFT strategies using variable-length CoT data (e.g., CoT-Valve) where models learn to skip steps or mix long/short reasoning paths
- Highlights dynamic inference methods (e.g., Speculative Rejection, Fast MCTS) that terminate reasoning early or switch strategies based on problem difficulty
Breakthrough Assessment
9/10
The first comprehensive survey to structure the emerging field of efficient reasoning, clearly distinguishing it from general model compression and providing a unified taxonomy for future research.