📝 Paper Summary
LLM Reliability and Robustness
Cognitive Evaluation of LLMs
This survey unifies fragmented research on Large Language Model (LLM) limitations by proposing a taxonomy that categorizes reasoning failures into fundamental, application-specific, and robustness issues across embodied and non-embodied domains.
Core Problem
Despite impressive performance, LLMs exhibit significant, systematic reasoning failures—ranging from simple logical slips to complex social misunderstandings—that remain fragmented across the literature without a unified framework.
Why it matters:
- Current research on failures is scattered and case-by-case, preventing the identification of common root causes like architectural deficits or training data biases
- LLMs are increasingly deployed in high-stakes domains, yet their reasoning is often brittle, failing under minor prompt variations (robustness issues) or specific contexts
- Understanding these failures through a cognitive science lens (e.g., lack of executive function) is necessary to guide the development of more reliable AI systems
Concrete Example:
In Theory of Mind (ToM) tasks, such as the 'false belief' test, advanced models like GPT-4 may solve the standard version but fail decisively when the prompt phrasing is slightly modified, revealing that they lack a robust, human-like understanding of others' mental states.
Key Novelty
Unified Reasoning Failure Taxonomy
- Classifies reasoning into two main axes: Embodied (requiring physical interaction) vs. Non-embodied (subdivided into Informal/Intuitive and Formal/Logical)
- Categorizes failures into three types: Fundamental (intrinsic to architecture), Application-specific (domain limitations), and Robustness (instability under minor variations)
- Synthesizes root causes by mapping LLM failures to human cognitive phenomena, such as deficits in working memory, inhibitory control, and susceptibility to cognitive biases
Architecture
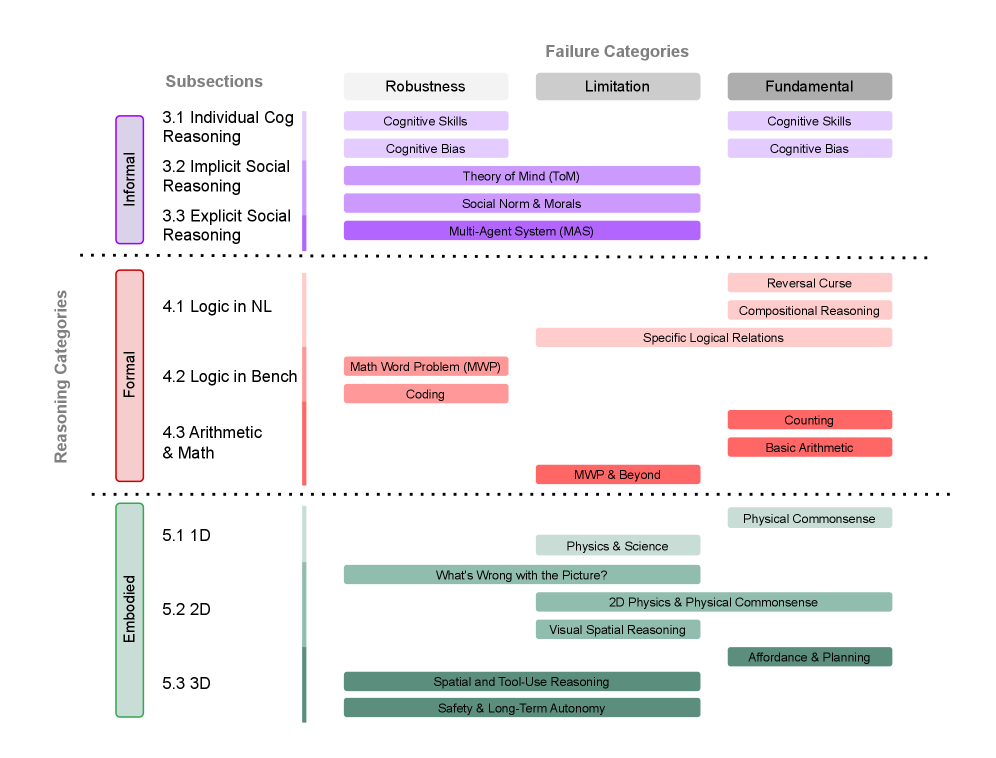
A hierarchical taxonomy chart organizing LLM reasoning failures
Breakthrough Assessment
8/10
Comprehensive survey that structures a critical but fragmented field. While it doesn't propose a new model, its taxonomy provides a necessary foundation for future robustness research.