📝 Paper Summary
Compositional Visual Reasoning (CVR)
Multimodal Large Language Models
This survey reviews over 260 papers to formalize Compositional Visual Reasoning, advocating for modular, step-by-step inference over monolithic models to improve grounding, robustness, and interpretability in multimodal AI.
Core Problem
Monolithic vision-language models treat inputs holistically, leading to reliance on spurious dataset biases, diminishing returns in complex reasoning, and a lack of interpretable, human-like decomposition.
Why it matters:
- Monolithic models frequently hallucinate by relying on linguistic priors (e.g., assuming bananas are always yellow) rather than visual evidence.
- Scaling data and compute yields diminishing returns for tasks requiring multi-hop reasoning or spatial understanding.
- Black-box architectures lack transparency, making them unsuitable for high-stakes applications like medical imaging or autonomous driving where reasoning steps must be verified.
Concrete Example:
When asked about the color of a green banana, a monolithic model might incorrectly answer 'yellow' due to statistical linguistic priors. In contrast, a compositional model would explicitly detect the object 'banana', extract its specific visual attribute 'color', and ground the answer in the actual pixel data.
Key Novelty
Unified Taxonomy of Compositional Visual Reasoning
- Formalizes a five-stage evolutionary roadmap: moving from prompt-enhanced pipelines and tool-enhanced LLMs/VLMs to Chain-of-Thought reasoning and Unified Agentic VLMs.
- Synthesizes the benefits of compositionality into seven key dimensions, including cognitive alignment, semantic fidelity, modular reuse, and hallucination mitigation.
Architecture
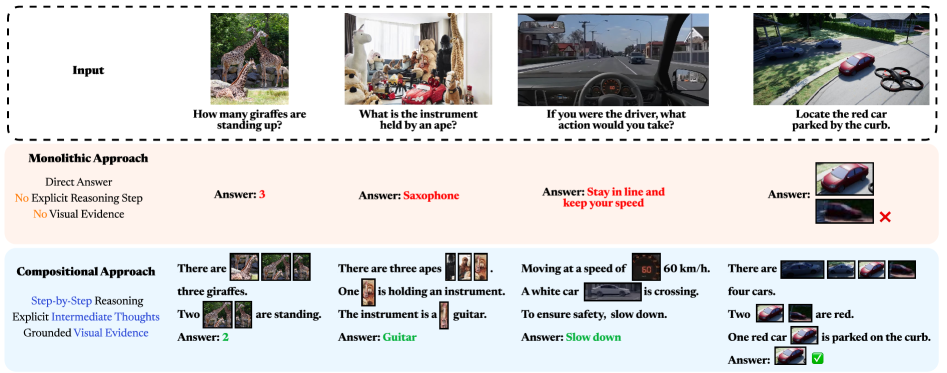
Contrast between Monolithic Visual Reasoning and Compositional Visual Reasoning (CVR) paradigms.
Evaluation Highlights
- Cataloged 260+ papers from top venues (CVPR, ICCV, NeurIPS, etc.) spanning January 2023 to May 2025.
- Identified and reviewed 60+ benchmarks focusing on dimensions such as grounding accuracy and chain-of-thought faithfulness.
Breakthrough Assessment
9/10
A timely and comprehensive synthesis of a rapidly expanding field. It provides a necessary structured taxonomy and defines the 'CVR' paradigm distinct from general multimodal learning.