📝 Paper Summary
Analogical Reasoning
Cognitive Modeling
LLM Evaluation
Advanced LLMs match human performance on complex analogical tasks requiring semantic re-representation, but failure on specific stress tests suggests they employ different underlying mechanisms than humans.
Core Problem
Humans flexibly re-represent concepts (e.g., viewing 'dog' as 'mammal' vs. 'four-legged') to solve analogies, but existing cognitive models (like SMT or Copycat) cannot handle this flexibility for rich semantic concepts.
Why it matters:
- Analogical reasoning is fundamental to human intelligence, allowing generalization from familiar to unfamiliar domains
- It is debated whether LLMs' emergent reasoning capabilities are robust and human-like or merely superficial statistical artifacts
- Existing computational models of analogy either lack semantic richness or cannot dynamically re-represent concepts, leaving a gap in cognitive theory
Concrete Example:
In the task 'ant => !!!!!!!, dog => ****, human => ?', the solver must re-represent concepts by 'number of legs' and 'mammal status' to output the correct symbols. Humans do this naturally; it is unclear if LLMs can induce such rules zero-shot.
Key Novelty
Evaluation of LLMs on novel 'Semantic Structure' and 'Semantic Content' analogy tasks
- Introduces tasks requiring mapping between semantic words and abstract symbol sequences, forcing the solver to induce rules based on specific semantic attributes (e.g., size, biology) rather than just surface text patterns
- Systematically manipulates task presentation (permutations, distractors, removal of semantic content) to diagnose whether models rely on genuine structural mapping or superficial heuristics
Architecture

Example of a 'Defaults' condition question in the Semantic Structure experiment
Evaluation Highlights
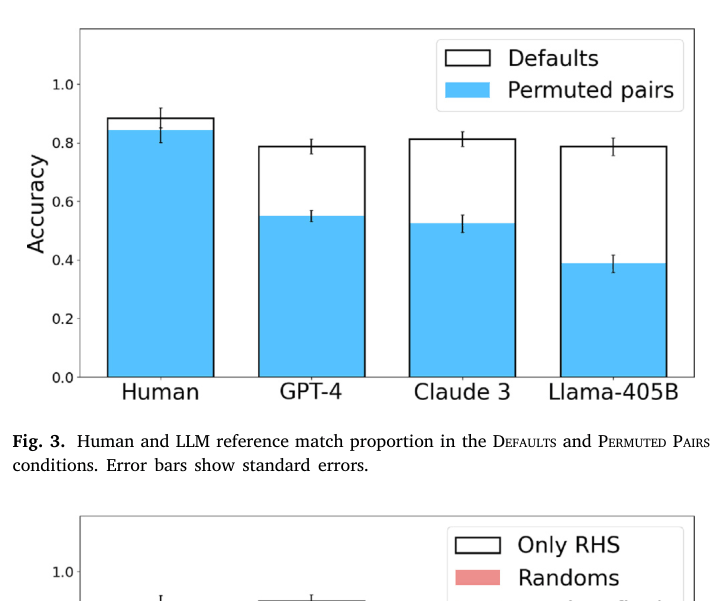
- GPT-4 and Claude 3 match human performance in the 'Defaults' condition (~0.8-0.9 reference match), suggesting potential for human-level analogical inference
- Human performance is robust to permuting the order of example pairs (~0.85 match), whereas GPT-4 performance drops significantly (~0.55 match) in the 'Permuted Pairs' condition
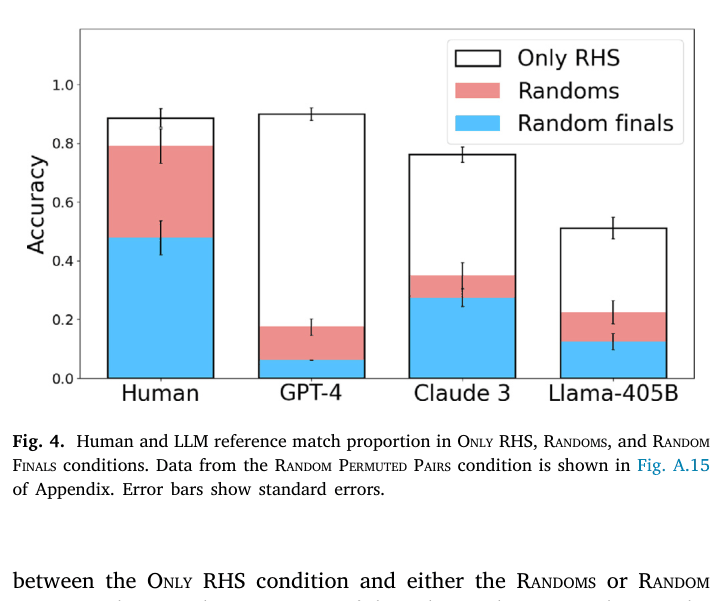
- Humans ignore misleading semantic inputs in 'Randoms' condition (maintaining ~0.8 match using only symbols), while GPT-4 drops drastically (~0.3 match), failing to switch strategies
Breakthrough Assessment
7/10
Strong behavioral analysis revealing that while LLMs mimic human outputs on analogy tasks, their sensitivity to order and distractors proves their internal mechanisms differ significantly from human reasoning.