📊 Experiments & Results
Evaluation Setup
Mathematical and Commonsense Reasoning
Benchmarks:
- GSM8K (Math Word Problems)
- AQUA-RAT (Algebra Word Problems)
- ECQA (Commonsense Reasoning)
- GSM8K-RANK (Math Reasoning with Ranking Feedback) [New]
Metrics:
- Accuracy
- Assessment Accuracy (AAccuracy)
- Perplexity (PPL)
- Statistical methodology: Reported mean and standard deviation over 3 runs with different seeds
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| AFT consistently improves accuracy over Vanilla Fine-Tuning (VFT) across multiple datasets and model sizes. | ||||
| GSM8K | Accuracy | 36.48 | 40.43 | +3.95 |
| GSM8K | Accuracy | 47.29 | 51.03 | +3.74 |
| AQUA | Accuracy | 31.19 | 33.20 | +2.01 |
| In ranking scenarios, AFT prevents the catastrophic degradation observed with other alignment methods like RRHF. | ||||
| GSM8K | Accuracy | 7.51 | 26.08 | +18.57 |
| GSM8K | Accuracy | 20.82 | 26.08 | +5.26 |
Experiment Figures

Perplexity comparison of different answers given by a VFT model.
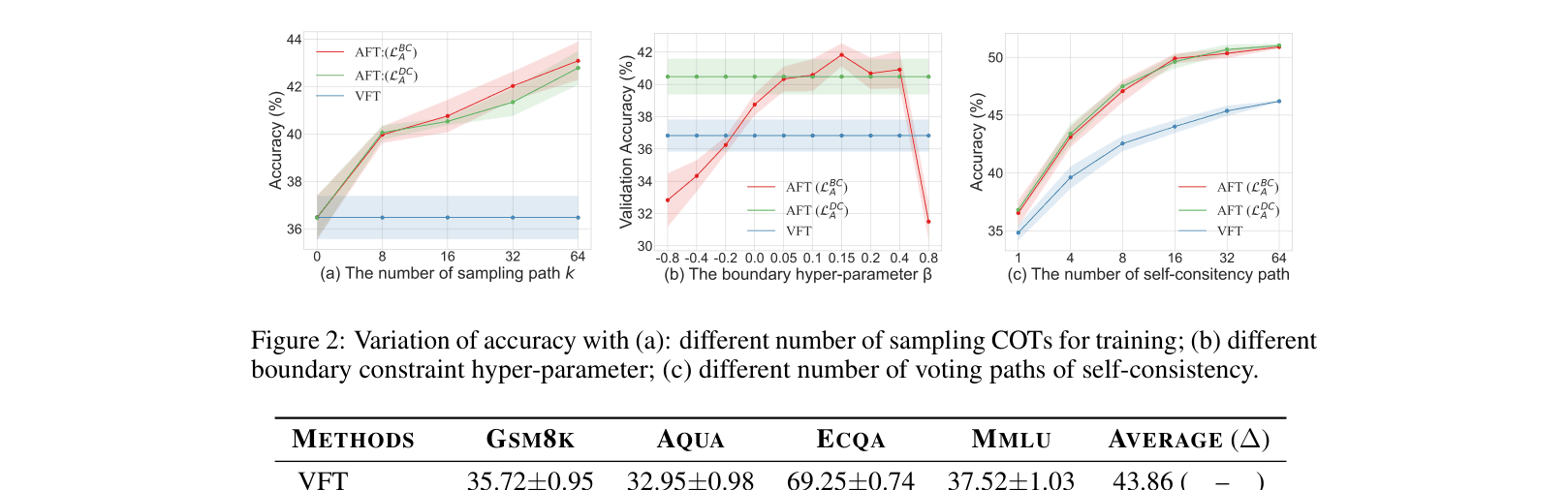
Ablation studies on sampling number k, boundary parameter beta, and self-consistency paths.
Main Takeaways
- Vanilla Fine-Tuning leads to 'Assessment Misalignment' where models cannot reliably distinguish good vs bad reasoning paths.
- Traditional alignment methods (RRHF, PRO) without constraints degrade reasoning capability by over-penalizing non-top-ranked reasoning paths.
- AFT's constraint mechanism allows the model to learn preferences while preserving generation quality, generalizing well to out-of-distribution tasks (MMLU) and enhancing Self-Consistency.