📝 Paper Summary
Dynamic Inference
Efficient LLM Deployment
Model Compression
Balcony enables efficient dynamic inference by attaching lightweight, trainable exit layers to a frozen pre-trained LLM, allowing adaptive computation without degrading the base model's performance.
Core Problem
Existing dynamic inference methods often require extensive retraining or modification of the base model, leading to performance degradation in the full model and conflicting gradients between intermediate and final layer objectives.
Why it matters:
- Real-world deployments face fluctuating computational constraints (latency, budget) that static models cannot handle efficiently
- Prior depth-based methods force intermediate layers to serve dual purposes (representation for next layer vs. final output), causing performance drops in the full model
- Retraining massive LLMs for dynamic inference is computationally expensive and risks catastrophic forgetting of pre-trained capabilities
Concrete Example:
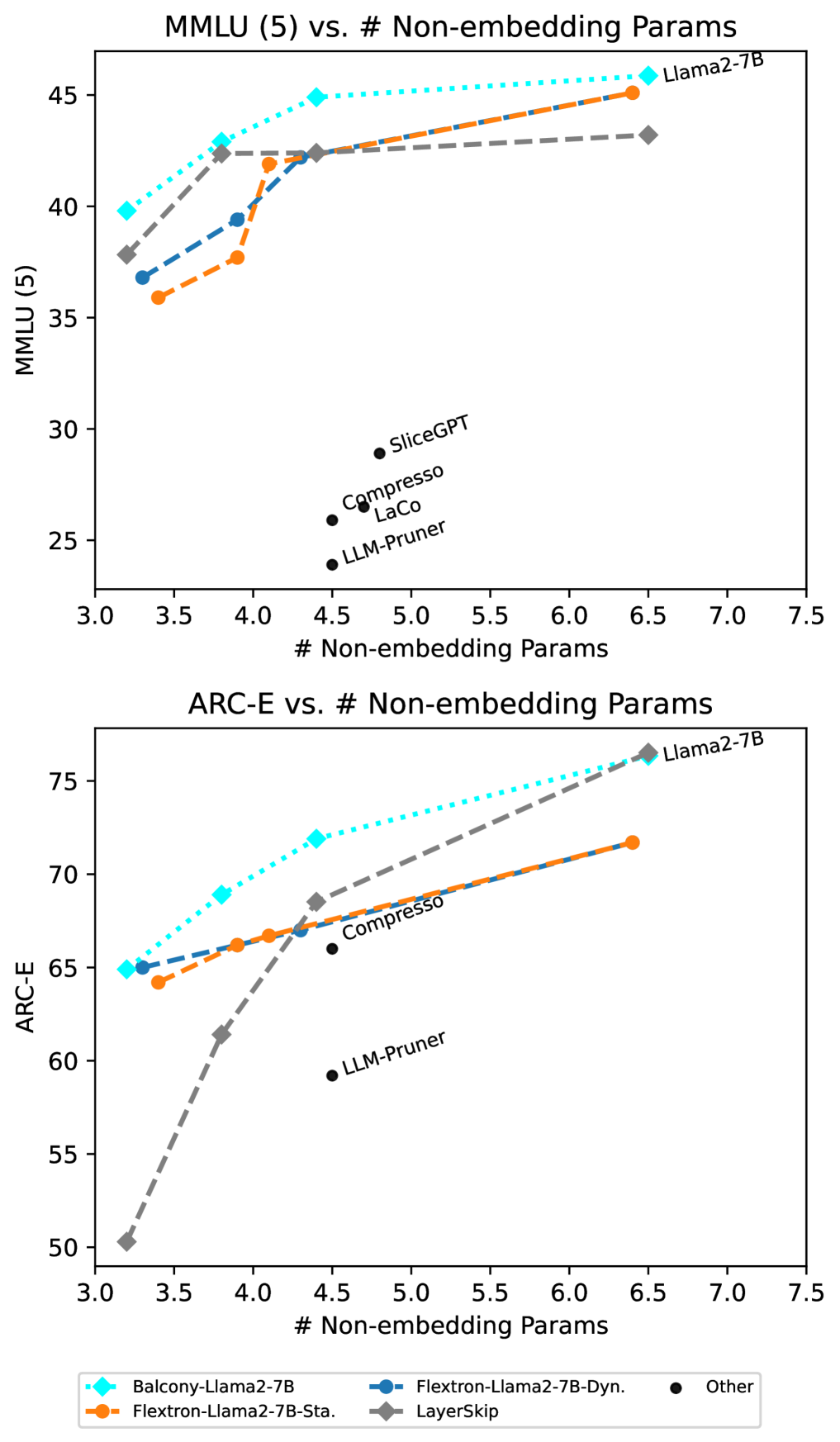
In methods like LayerSkip or Flextron, the base model weights are altered to support early exits. This creates a 'jack-of-all-trades' problem where the full model becomes worse than the original pre-trained checkpoint (e.g., LLaMA-2-7B accuracy drops from 46.1% to 42.1% in Flextron-Dynamic) because intermediate layers are pulled in different directions.
Key Novelty
Frozen Base Model with Balcony Exits
- Instead of retraining the main LLM, Balcony keeps it completely frozen and attaches a single transformer decoder layer (the 'Balcony') at specific exit points.
- These added layers are trained via self-distillation to map intermediate hidden states to the final output distribution, acting as lightweight adapters that translate partial processing into final predictions.
Architecture
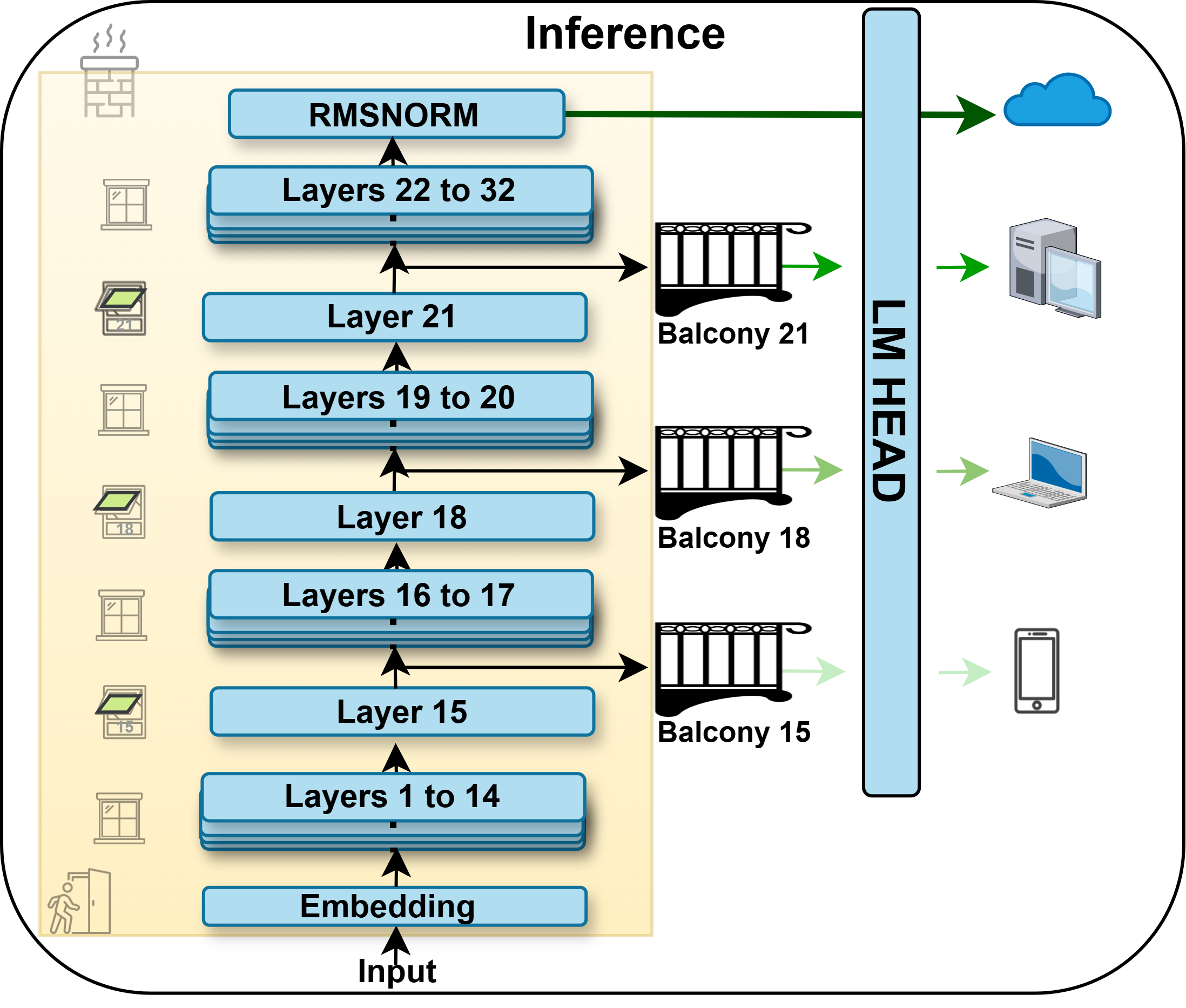
Conceptual framework of Balcony showing the frozen base model with attached trainable exit layers.
Evaluation Highlights
- Outperforms state-of-the-art Flextron and LayerSkip on LLaMA-2-7B and LLaMA-3-8B across 8 benchmarks while using significantly less training data (0.2% of pretraining tokens)
- Maintains 100% of the original base model's performance (lossless), whereas baselines degrade the full model by up to ~4 percentage points
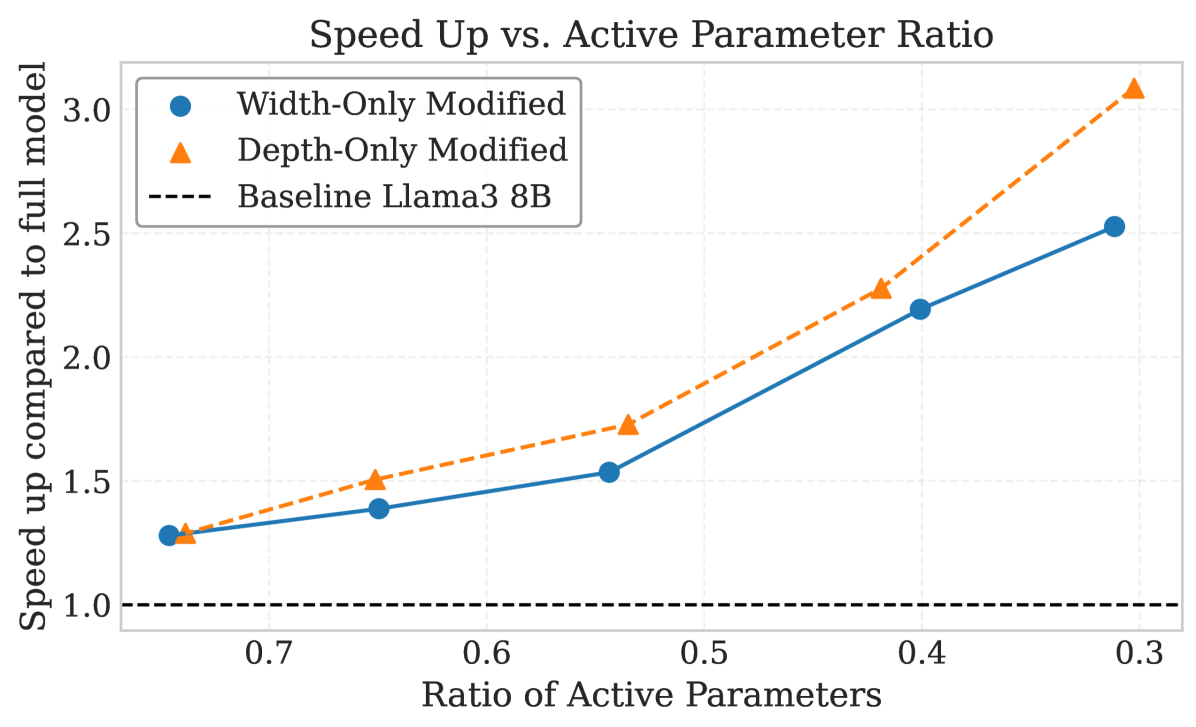
- Achieves ~2.8x speedup with minimal accuracy loss on LLaMA-3-8B by exiting at earlier layers compared to the full model
Breakthrough Assessment
8/10
Simple yet highly effective solution to the 'conflicting gradients' problem in dynamic inference. By freezing the base model, it guarantees no degradation of the full model—a critical advantage over prior work—while achieving superior sub-model performance.