📝 Paper Summary
Edge AI / On-device Inference
Efficient LLM Reasoning
Parameter-Efficient Fine-Tuning (PEFT)
This paper enables efficient, high-performance reasoning on edge devices by combining modular LoRA adapters, reinforcement learning with budget forcing to reduce verbosity, and dynamic inference routing.
Core Problem
Deploying reasoning-capable LLMs on edge devices is hindered by the memory bottlenecks of large models and the high latency/compute costs of verbose Chain-of-Thought generation.
Why it matters:
- Mobile devices have strict thermal, power, and memory (DRAM) constraints that standard reasoning models (like DeepSeek-R1) exceed
- Long reasoning traces rapidly exhaust the KV cache, causing out-of-memory errors or prohibitive latency for users
- Distilling reasoning into small models often results in 'lazy' generation or retains the verbose, redundant styles of teacher models
Concrete Example:
A standard reasoning model might generate a 4,000-token Chain-of-Thought to solve a simple math problem, draining the battery and taking seconds to respond. The proposed system detects the query difficulty and either routes it to a fast base model or uses a 'budget-forced' adapter that solves it in <2,000 tokens.
Key Novelty
Budget-Forced Modular Reasoning Pipeline
- Uses 'Budget Forcing' in Reinforcement Learning: a soft-barrier reward function that penalizes tokens exceeding a prompted length bucket (e.g., 1k, 3k), forcing the model to be concise
- Implements a 'Switcher' module: a lightweight classifier that dynamically routes queries between the cheap base model and the expensive reasoning LoRA adapter
- Enables 'Masked LoRA Training': allows the base model and reasoning adapter to share the same prompt KV-cache, eliminating the need to re-encode prompts when switching modes
Architecture
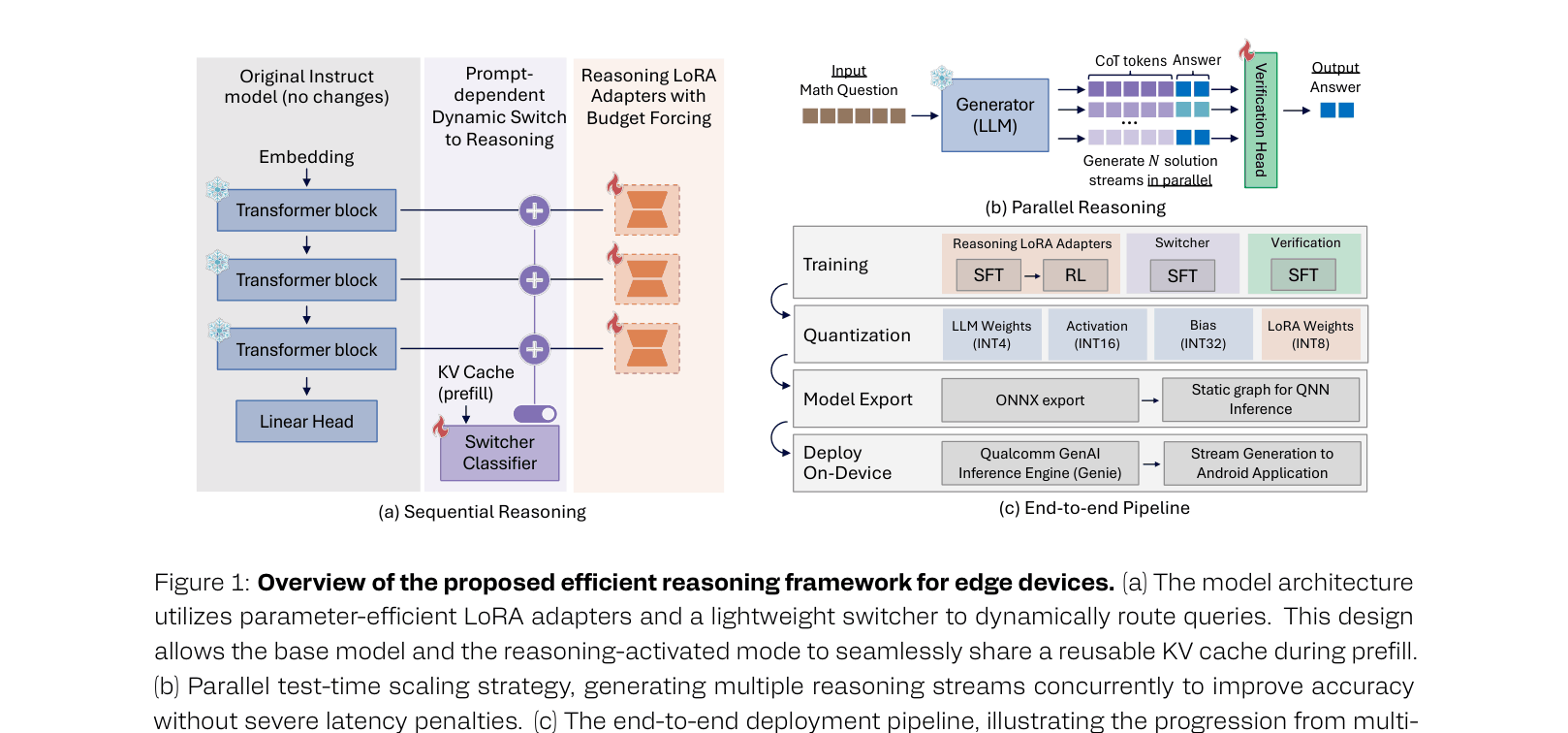
End-to-end inference pipeline: Switcher -> Base Model or LoRA -> Verification.
Evaluation Highlights
- Qwen2.5-7B with LoRA (rank 128) achieves 93% on MATH500, matching the fully distilled DeepSeek-R1-Distill-Qwen-7B (92%) while using only ~4% trainable parameters
- Reinforcement Learning with Budget Forcing reduces average reasoning completion length by ~2.4x (from ~4k to <2k tokens) while maintaining comparable accuracy on MATH500
- Dynamic Switcher effectively routes queries, maintaining 93.0% accuracy on MATH500 while significantly reducing average token generation cost compared to always-on reasoning
Breakthrough Assessment
9/10
Highly practical contribution. Successfully reconciles high-performance reasoning with edge constraints by attacking the problem from multiple angles (architecture, RL alignment, system-level optimization). The performance match with full-parameter distillation using only LoRA is particularly impressive.