📝 Paper Summary
Analogical Reasoning
Neuro-Symbolic AI
Large Reasoning Models (LRMs)
Large Reasoning Models like o3-mini fail significantly at analogical reasoning when visual inputs contain noise, whereas neuro-symbolic models with entropy-based regularization remain robust.
Core Problem
Current evaluations of Large Reasoning Models (LRMs) on analogical reasoning assume 'oracle perception' (perfect symbolic inputs), ignoring the noise and uncertainty inherent in real-world visual perception.
Why it matters:
- LRMs are being deployed for complex reasoning, but their robustness to noisy, real-world data remains untested and potentially brittle
- Assuming perfect perception bypasses the critical challenge of filtering irrelevant attributes (confounders) and handling uncertain values
- Existing benchmarks like I-RAVEN are too clean, leading to inflated performance estimates that do not reflect true generalization capabilities
Concrete Example:
In a Raven's Progressive Matrix puzzle, an LRM might easily solve the logic if given perfect symbols (e.g., 'Shape: Triangle'). However, if the input includes irrelevant background patterns (confounders) or the shape classifier outputs a probability distribution (e.g., 0.6 Triangle, 0.4 Square) instead of a certainty, the LRM's reasoning process collapses.
Key Novelty
Benchmarking under Simulated Perceptual Uncertainty & Entropy-Regularized Abduction
- Extends the I-RAVEN-X benchmark by injecting confounding attributes (irrelevant visual noise) and smoothing attribute values into probability distributions to simulate imperfect perception
- Introduces an entropy-based regularizer for neuro-symbolic models that weights attribute contributions by their confidence, allowing the model to ignore uncertain or noisy features during reasoning
Architecture
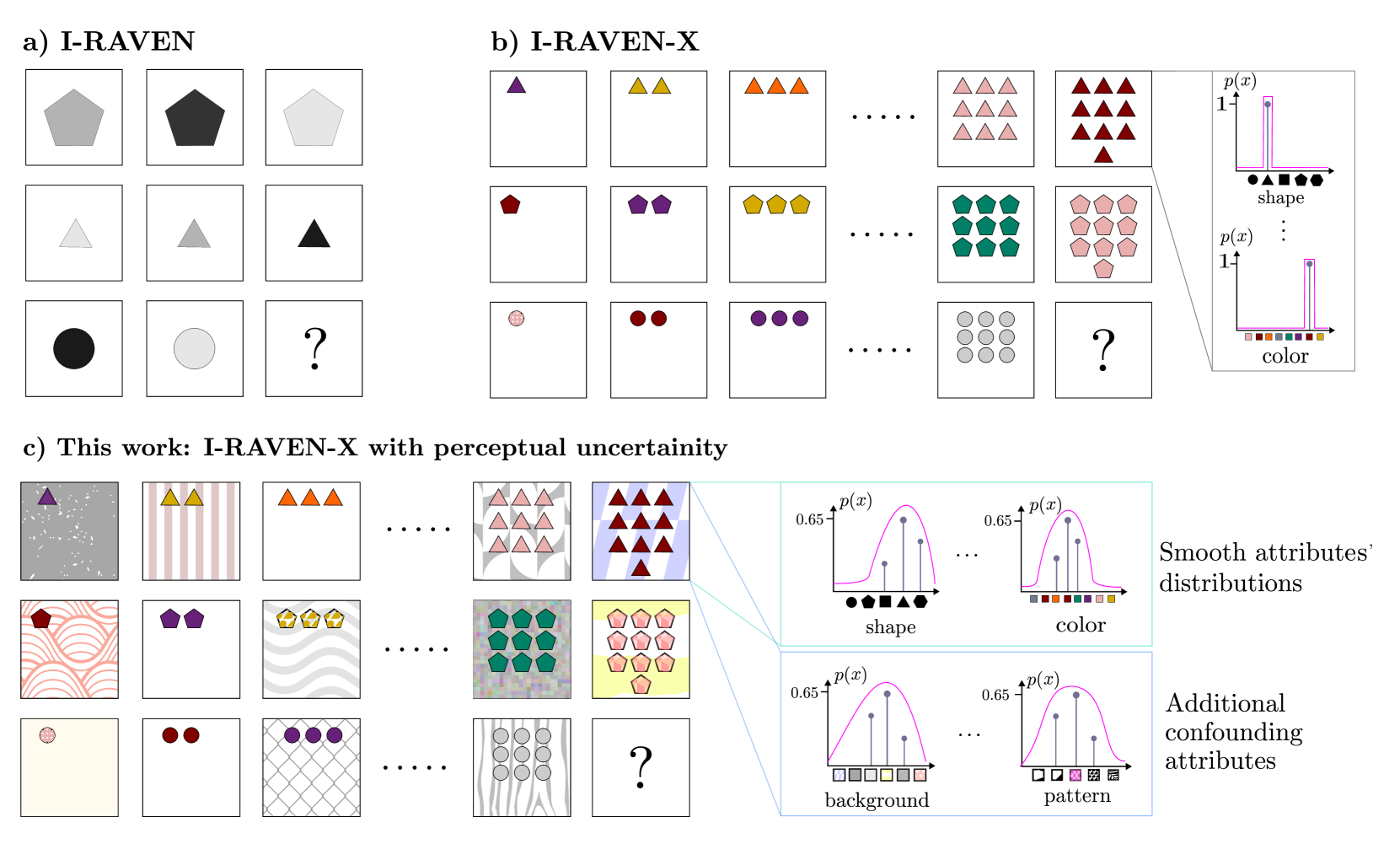
Comparison of the standard I-RAVEN task vs. the proposed I-RAVEN-X with perceptual uncertainty
Evaluation Highlights
- OpenAI o3-mini accuracy plummets from 86.6% on standard I-RAVEN to 17.0% on the noisy I-RAVEN-X extension, approaching random chance
- DeepSeek R1 shows a similar decline, dropping from 80.6% to 23.2% accuracy under perceptual uncertainty
- The proposed neuro-symbolic model (ARLC) maintains strong robustness, dropping only from 98.6% to 88.0% accuracy on the same difficult benchmark
Breakthrough Assessment
8/10
Reveals a critical brittleness in state-of-the-art LRMs (o3-mini, R1) regarding noisy inputs, countering the hype of their reasoning dominance, while demonstrating a viable neuro-symbolic solution.