📊 Experiments & Results
Evaluation Setup
Zero-shot (one-shot prompt with rules) evaluation on generated Tents puzzles of increasing size
Benchmarks:
- Tents Puzzle (Algorithmic/Logic Puzzle)
Metrics:
- Success Rate (binary solvability)
- Reasoning Effort (total token count)
- Problem Size (rows × columns)
- Statistical methodology: Linear regression (R² fit) used to analyze the relationship between problem size and reasoning effort
Experiment Figures
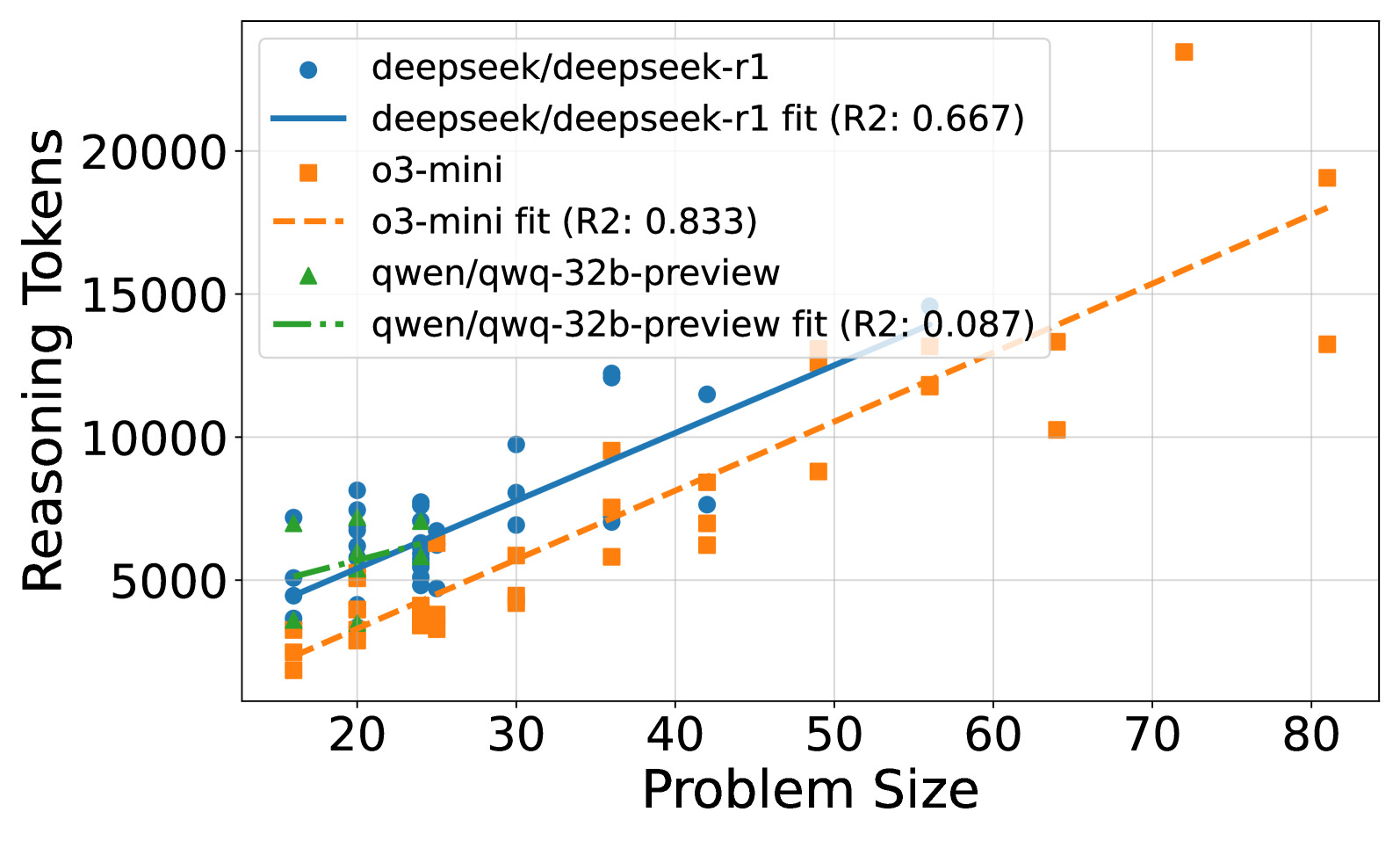
Scatter plot of Reasoning Tokens (Y-axis) vs. Problem Size (X-axis) for correctly solved puzzles across four models.
Bar chart or curve showing the maximum solvable problem size or success rate distribution.
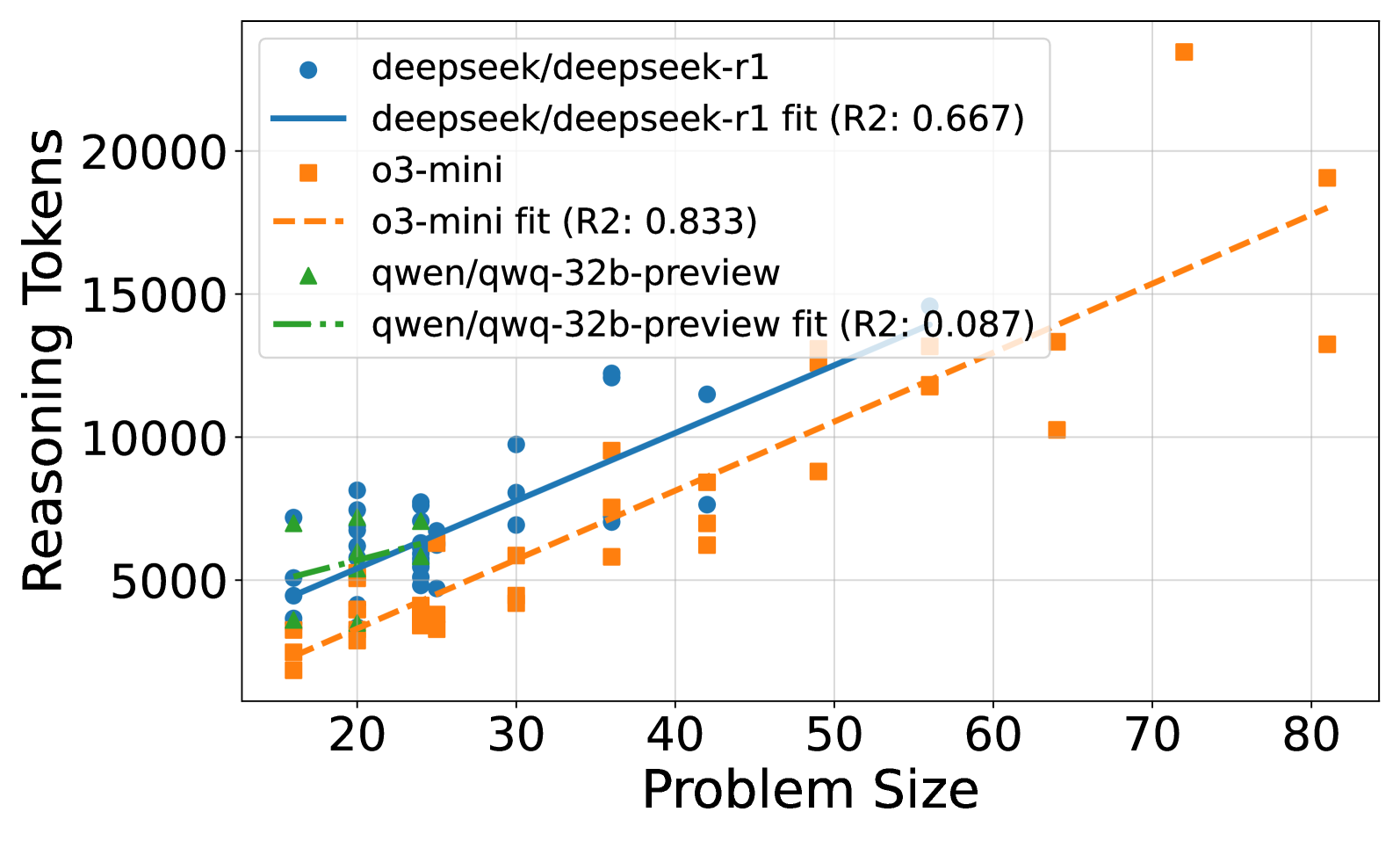
Detailed scaling of o3-mini's reasoning effort including failed attempts, showing a peak.
Main Takeaways
- Reasoning effort scales linearly with problem size for models that can solve the tasks (o3-mini, R1), suggesting they are performing actual algorithmic work.
- There is a 'logical coherence limit': no model successfully solved puzzles larger than size 100 (10x10 grid), regardless of the reasoning tokens generated.
- o3-mini exhibits a 'frustration' effect where reasoning effort peaks and then drops for unsolvable/large puzzles, whereas other models might just fail without the drop.
- Higher reasoning effort strategies (in o3-mini) allow solving larger puzzles but are token-inefficient for smaller, simpler puzzles compared to low-effort strategies.