📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation and RLVR training on procedural tasks.
Benchmarks:
- Reasoning Gym (Internal) (Procedural Reasoning Tasks (Algebra, Games, Logic, etc.)) [New]
- MATH (Competition Mathematics)
- GSM8K (Grade School Math)
- Big-Bench Hard (BBH) (Challenging Reasoning Tasks)
- MMLU-Pro (Academic and Professional Knowledge)
Metrics:
- Accuracy (%)
- Reward (Accuracy + Format Reward)
- Statistical methodology: Experiments typically involved 3 independent runs on identical evaluation sets of 50 problems.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Zero-shot evaluation reveals a significant gap between reasoning-optimized models and general-purpose models on Reasoning Gym tasks. | ||||
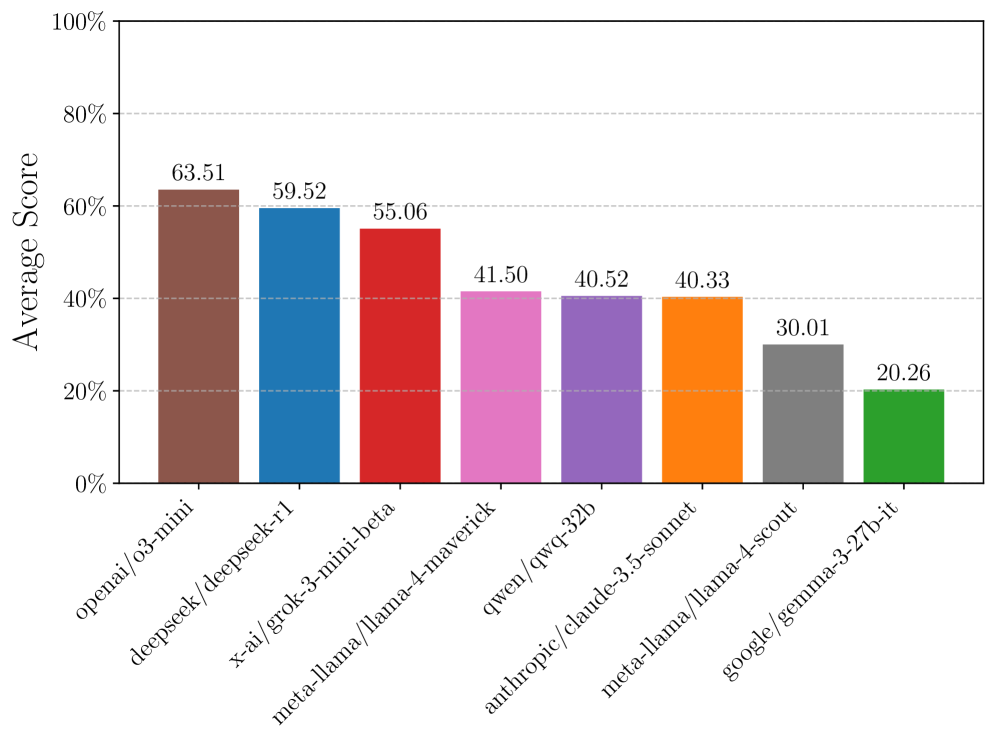
| Reasoning Gym (Aggregate) | Accuracy | 41.5 | 63.5 | +22.0 |
| Reasoning Gym (Aggregate) | Accuracy | 40.3 | 59.5 | +19.2 |
| Intra-domain transfer experiments show that training on a subset of domain tasks improves performance on held-out tasks within the same domain. | ||||
| Reasoning Gym (Algebra) | Accuracy | 13.3 | 25.0 | +11.7 |
| Reasoning Gym (Algorithmic) | Accuracy | 27.1 | 34.5 | +7.4 |
| Cross-domain transfer experiments demonstrate that skills learned in one domain (e.g., Algorithmic) generalize to distinct domains (e.g., Algebra, Geometry). | ||||
| Reasoning Gym (Algebra) | Accuracy | 13.3 | 42.4 | +29.1 |
| Reasoning Gym (Geometry) | Accuracy | 19.6 | 41.9 | +22.3 |
| External benchmark results confirm that Reasoning Gym training transfers to established static benchmarks. | ||||
| MATH | Accuracy | 39.9 | 49.6 | +9.7 |
| Big-Bench Hard | Accuracy | 39.9 | 47.6 | +7.7 |
| Curriculum learning experiments show adaptive difficulty progression outperforms fixed difficulty training. | ||||
| Spell Backward (Len 4) | Accuracy | 46.00 | 86.67 | +40.67 |
Experiment Figures
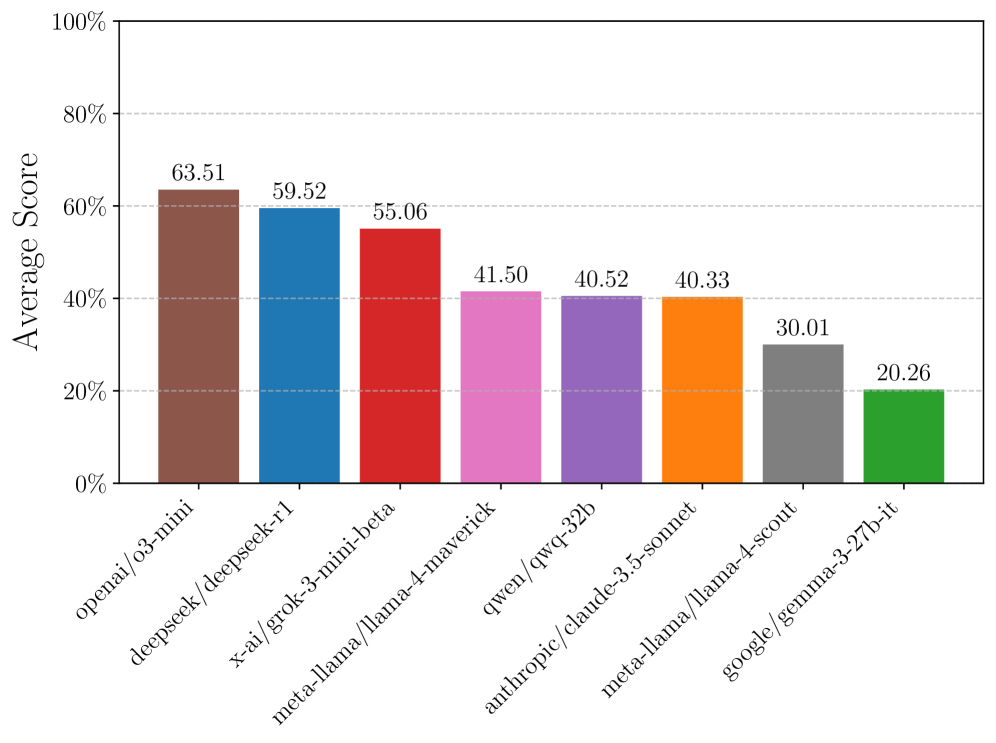
Zero-shot performance of various models across categories (Easy vs. Hard settings) and the 'difficulty cliff' (performance drop when moving from easy to hard).
Training dynamics (reward curves) for intra-domain transfer across categories.

Comparison of Curriculum vs. Non-Curriculum training dynamics.
Main Takeaways
- Procedural data generation effectively overcomes the 'data wall', enabling sustained improvement via RLVR without relying on finite human-labeled datasets.
- Algorithmic reasoning training serves as a strong foundation, transferring surprisingly well to mathematical domains like algebra and geometry (Cross-Domain Transfer).
- Curriculum learning, where difficulty scales with agent performance, yields significantly better final models than training on uniform difficulty distributions.
- A 'difficulty cliff' exists: performance drops sharply as task complexity increases (e.g., graph size, code length), revealing that current models often rely on shallow pattern matching rather than robust reasoning.