📝 Paper Summary
Foundation Models (LLMs, Multimodal)
Artificial General Intelligence (AGI)
Reasoning Methodologies
This survey systematizes the field of reasoning with foundation models by categorizing tasks, techniques, and benchmarks to bridge the gap between pattern recognition and human-like logical deliberation.
Core Problem
While foundation models excel at pattern recognition (System 1), their ability to perform deliberate, logical, and complex reasoning (System 2) remains debated and fragmented across various domains.
Why it matters:
- Reasoning is a fundamental requirement for Artificial General Intelligence (AGI), enabling complex problem-solving in negotiation, medical diagnosis, and law.
- Current research is scattered across isolated domains (e.g., math vs. commonsense), lacking a unified view of how foundation models can be adapted for general reasoning.
- Transitioning from implicit 'System 1' intuition to explicit 'System 2' logical analysis is critical for reliability, interpretability, and robustness in real-world AI applications.
Concrete Example:
In a social reasoning task, a model must infer a person's emotional state (e.g., 'happy' vs 'likes cold') not just by matching keywords, but by logically connecting context ('moved to Florida') with preferences ('found Northeast too cold').
Key Novelty
Unified Taxonomy of Reasoning with Foundation Models
- Proposes a comprehensive taxonomy classifying reasoning into specific domains (Commonsense, Math, Logical, Causal, Visual, Audio, Multimodal, Embodied).
- Integrates diverse foundation model types (Language, Vision, Multimodal) with reasoning-specific techniques like Chain-of-Thought (CoT) and autonomous agents.
Architecture
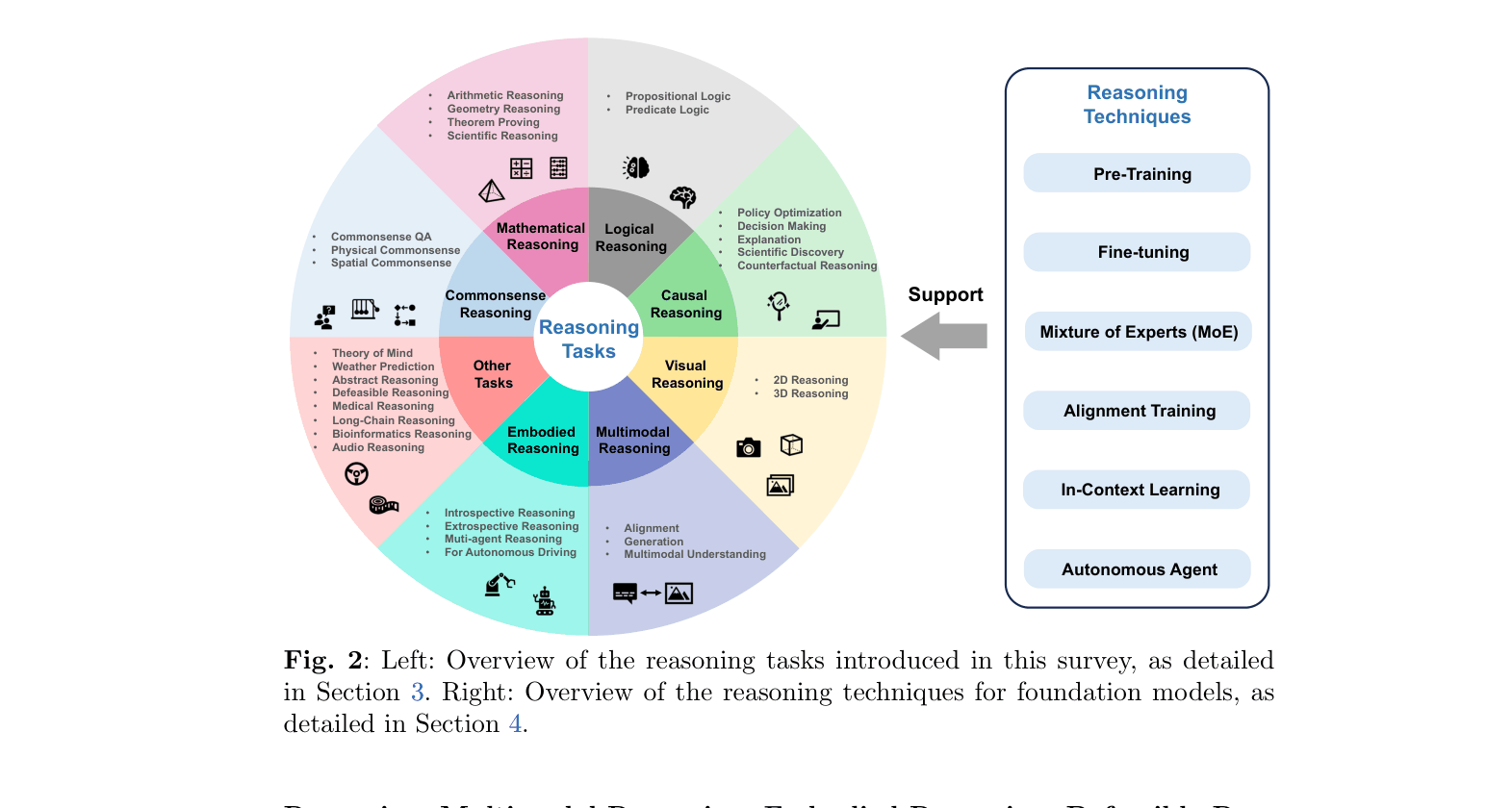
An overview of the reasoning landscape, mapping 'Reasoning Tasks' to 'Reasoning Techniques' and 'Support'.
Evaluation Highlights
- Surveys over 650 papers, categorizing them into tasks, techniques, and benchmarks.
- Highlights performance of specific models like Minerva (540B parameters), which answers nearly one-third of 200+ undergraduate-level science problems.
- identifies that Chain-of-Thought (CoT) prompting enables zero-shot reasoning on arithmetic benchmarks (GSM8K, SVAMP) without handcrafted examples.
Breakthrough Assessment
9/10
A highly extensive and timely survey that organizes a rapidly exploding field. It provides a critical roadmap for researchers by connecting disparate sub-fields (multimodal, logical, agentic) under the umbrella of reasoning.