📝 Paper Summary
Visually-aware conversational recommendation
Vision-Language Models (VLMs)
LaViC compresses high-dimensional product images into minimal visual tokens via self-distillation, enabling Large Vision-Language Models to process multiple item candidates in conversational recommendation without exceeding context limits.
Core Problem
Processing multiple product images in conversational recommendation causes token explosion, exceeding VLM context windows and increasing computational cost.
Why it matters:
- Standard VLMs (e.g., LLaVA) use thousands of tokens per image, making it impossible to analyze multiple retrieval candidates simultaneously
- Text-only systems miss crucial visual details (style, color, design) essential for domains like fashion and home decor
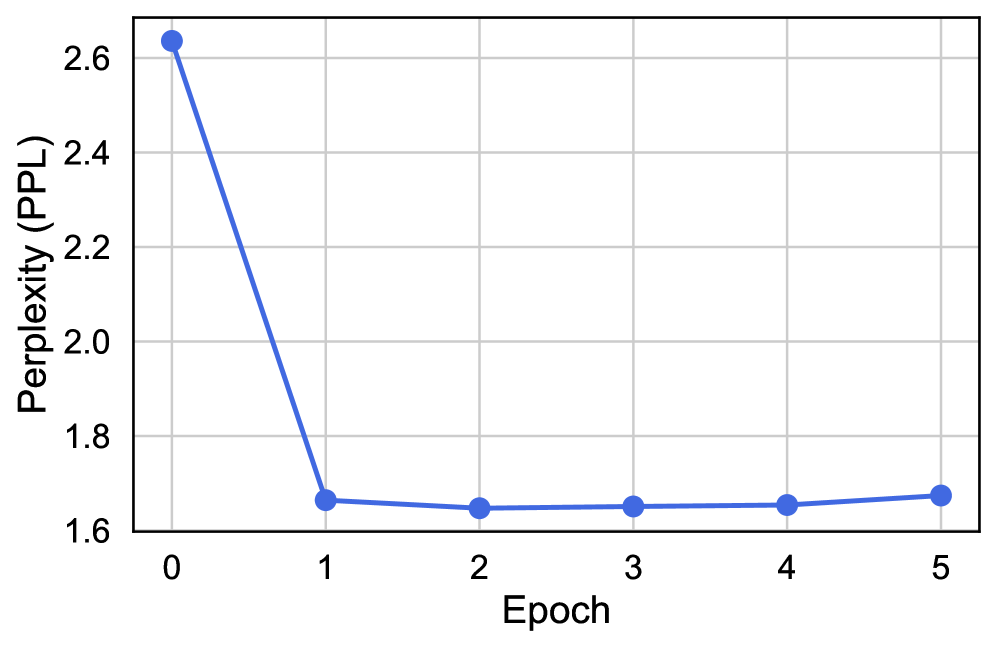
- Naive end-to-end fine-tuning of massive VLMs on limited recommendation data often leads to overfitting
Concrete Example:
A user requests a 'hoodie-like military-style jacket with chest pockets.' Text descriptions alone might match multiple items, but verifying the exact pocket arrangement or silhouette requires visual inspection. Feeding 10 candidate images (each ~2,885 tokens) into a VLM exceeds typical 4k context limits.
Key Novelty
Two-stage Visual Compression and Recommendation Framework
- Visual Knowledge Self-Distillation: Compresses thousands of image tokens into just 5 [CLS] embeddings per item by training the vision projector to reproduce detailed captions from these few tokens alone
- Recommendation Prompt Tuning: Fine-tunes the LLM to take these compressed visual tokens and text context to select the correct item ID from a candidate list, avoiding hallucination
Architecture
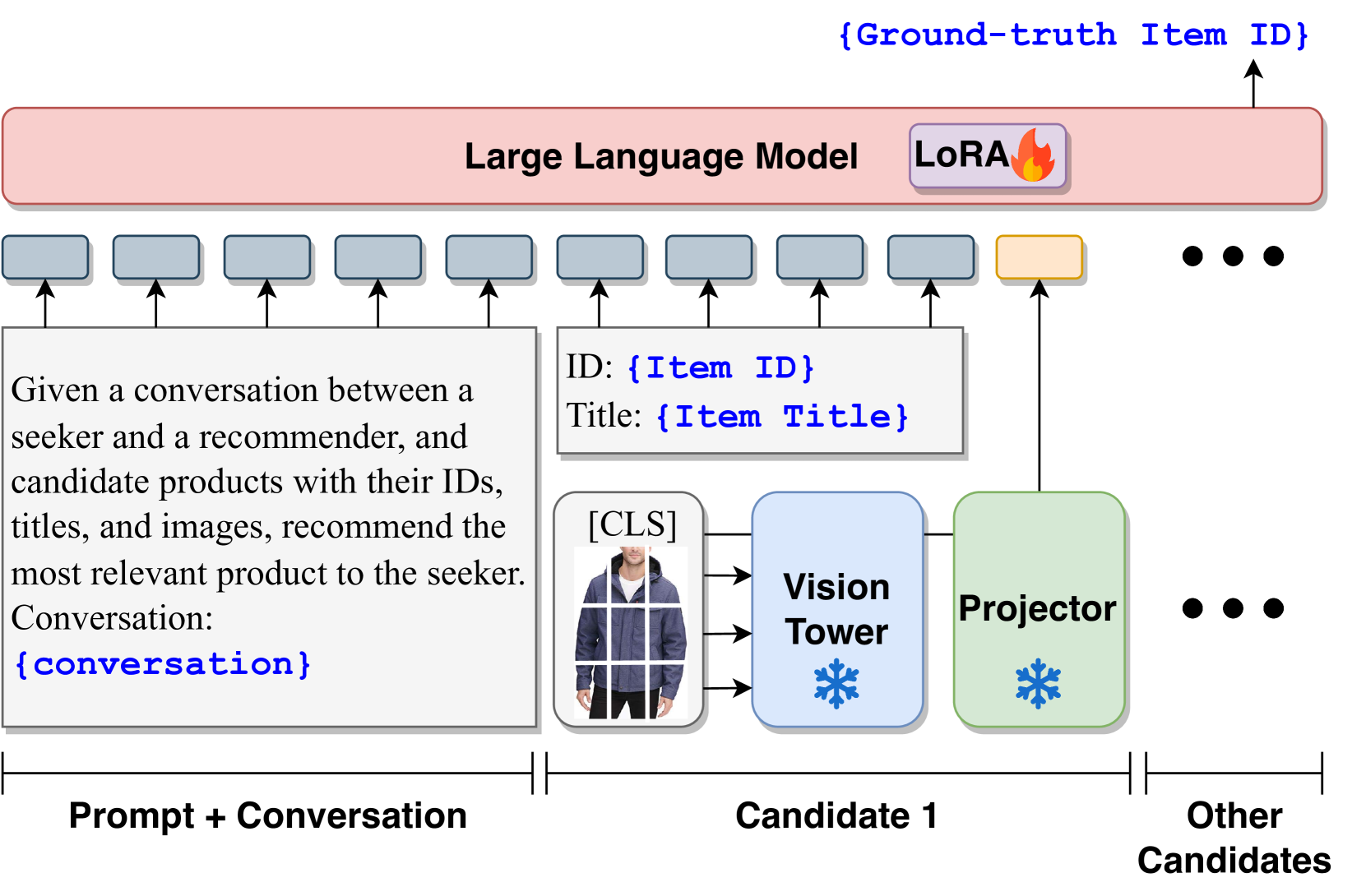
The recommendation inference workflow of LaViC.
Evaluation Highlights
- Significantly outperforms text-only baselines (e.g., +24.4% accuracy vs LLaMA-2-7B on Fashion subset)
- Surpasses standard VLM baselines (e.g., LLaVA-v1.5) by effectively handling multiple images within context limits
- Achieves competitive or superior accuracy compared to proprietary models like GPT-4o, despite being much smaller and open-source
Breakthrough Assessment
7/10
Effective solution to the multi-image token context bottleneck in VLMs. While the architecture relies on existing components (LLaVA), the self-distillation strategy for compression is practical and the new dataset fills a gap in visual conversational recommendation.