📝 Paper Summary
Benchmark datasets
Agentic data generation
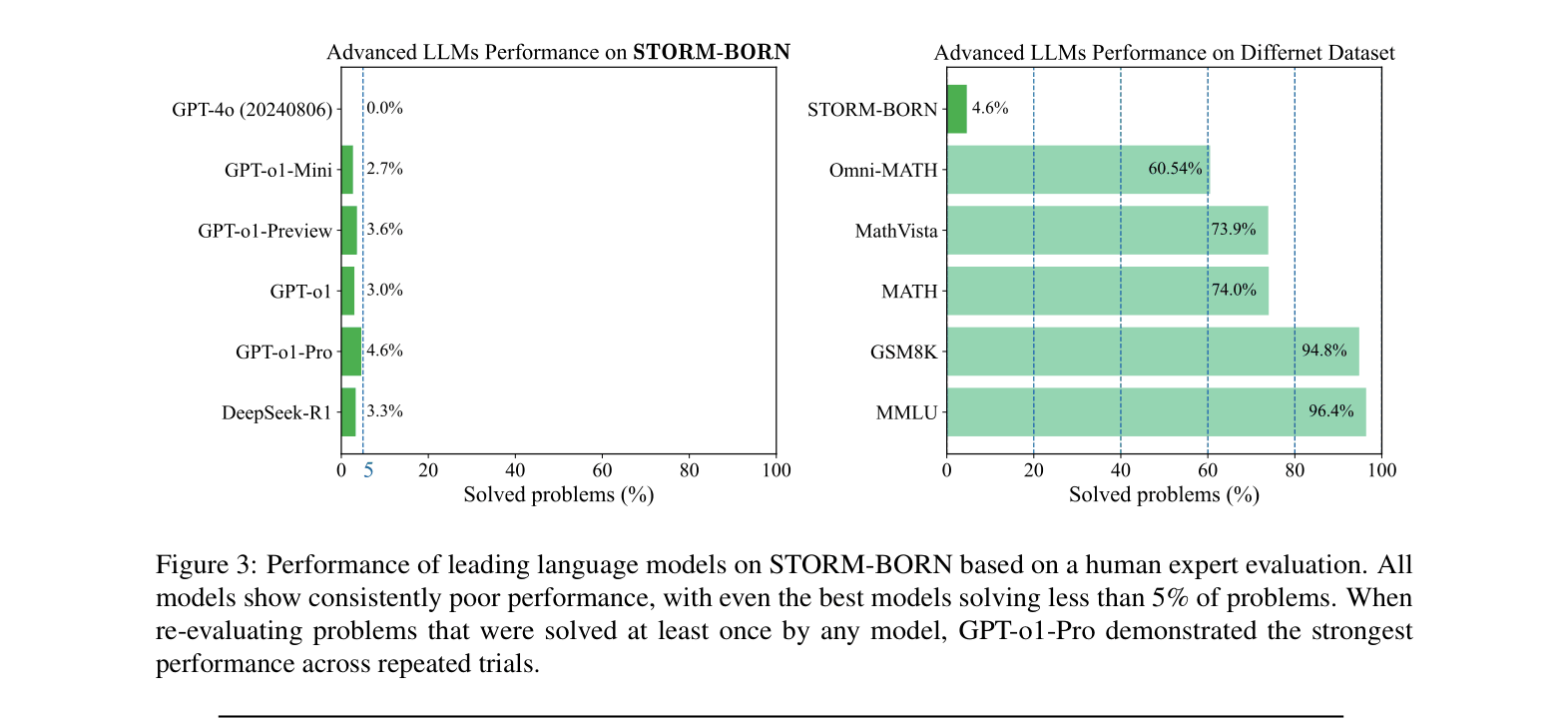
STORM-BORN is a highly challenging dataset of mathematical derivations extracted from research papers using a multi-agent framework and filtered by experts, on which even GPT-o1-Pro fails significantly.
Core Problem
Existing mathematical datasets are either too simple (numerical reasoning) or rely on formal languages that lack human-like intuition, while synthetic data often suffers from unreliable annotations.
Why it matters:
- Current LLMs have saturated traditional math benchmarks like GSM8K (~95% accuracy), necessitating harder challenges to probe intelligence upper bounds
- Formal proof datasets (e.g., MiniF2F) obscure interpretable, intuitive reasoning processes required for human-like mathematical understanding
- Reliable expert annotation for complex math is costly, and single-LLM generation lacks the necessary quality and reliability for deep derivation tasks
Concrete Example:
Numerical datasets ask for the expected value of a coin toss (calculating 0.25). Formal datasets ask to prove '7(3y+2)=21y+14' in Lean code. STORM-BORN asks to derive a specific partition function Z(x) for a KL-constrained reward maximization objective (Equation 4) based on a prior KL divergence formula (Equation 3) from a specific research paper, requiring multiple logical leaps and definitions.
Key Novelty
Human-in-the-Loop Multi-Agent Framework (STORM)
- Decomposes complex data generation into specialized agents (Extraction, Query Drafting, Retrieval, Context Collection) to handle long-context reasoning better than single models
- Integrates 'Reasoning-dense Content Filtering' to select source material rich in derivations (e.g., proofs in appendices) rather than simple descriptions
- Employs a rigorous human-expert selection process to curate only the most challenging, creative, and reasoning-dense problems from the synthetic pool
Architecture
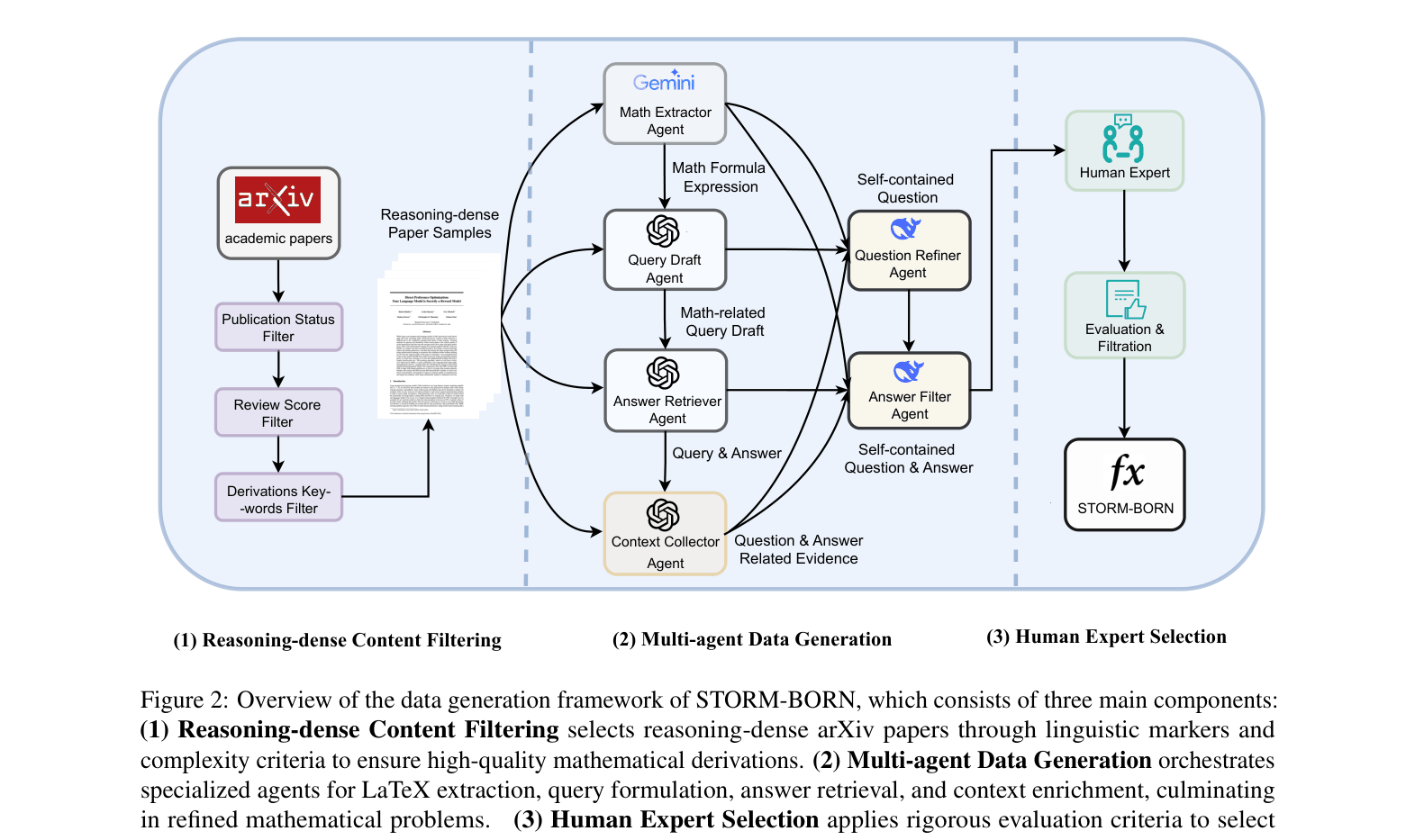
Overview of the data generation framework consisting of Filtering, Multi-agent Generation, and Human Selection.
Evaluation Highlights
- Less than 5% accuracy for state-of-the-art models (GPT-o1-Pro, DeepSeek-R1) on STORM-BORN, compared to ~95% on GSM8K
- +9.12% accuracy improvement on MATH benchmark for Qwen2.5-7B after fine-tuning on just 100 STORM-BORN samples
- TinyLlama-1.1B achieves a 233% relative improvement on the MATH dataset after fine-tuning on STORM-BORN
Breakthrough Assessment
8/10
Provides a necessary 'next-level' difficulty benchmark where current SOTA fails completely, while demonstrating that small, high-quality data (100 samples) significantly boosts reasoning generalization.