📝 Paper Summary
Medical Multi-Agent Systems
Clinical Diagnosis
Reasoning & Argumentation
MedCollab improves clinical diagnosis by using a multi-agent team that structures reasoning into causal chains and traceable arguments, audited by a consensus mechanism to reduce hallucinations.
Core Problem
Existing medical LLMs and agents treat diagnosis as independent associations between symptoms and diseases, failing to model causal progression and leading to hallucinations lacking traceable evidence.
Why it matters:
- Correlation-based diagnosis often misses the root cause or pathological progression (e.g., treating a symptom rather than the underlying condition)
- Unstructured model outputs lack traceability, making it impossible for clinicians to audit the logic behind a high-stakes medical decision
- Hallucinations in clinical settings are dangerous; systems must strictly ground assertions in patient-specific examination results
Concrete Example:
A patient might present with Anemia. A standard model might simply output 'Anemia' as the diagnosis. MedCollab traces the causal chain: 'Trauma → Rib Fracture → Lung Hemorrhage → Anemia', identifying the root trauma and intermediate hemorrhage that require treatment, rather than just the final symptom.
Key Novelty
Causal-Driven IBIS Argumentation
- Transforms unstructured agent dialogue into a structured Issue-Based Information System (IBIS), requiring every diagnostic claim to be a 'Position' supported by an explicit 'Argument' and traceable 'Evidence'
- Constructs a Hierarchical Disease Causal Chain (HDCC) that links isolated diagnoses into a directed graph of pathological progression (Causality vs. Comorbidity)
- Implements a logic auditing mechanism where a General Practitioner agent iteratively penalizes and down-weights specialists whose arguments contradict the evidence
Architecture
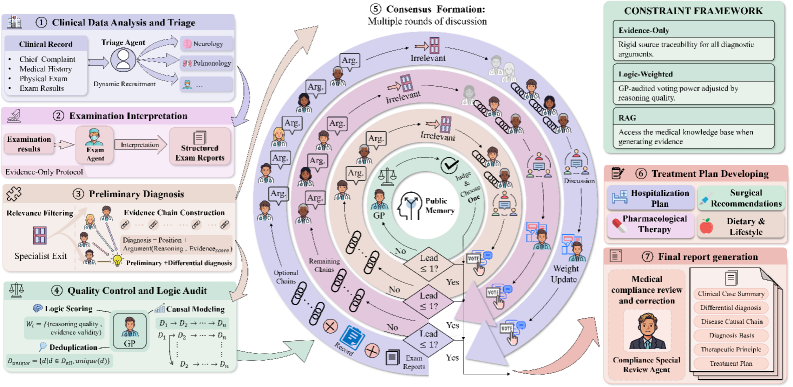
The MedCollab framework workflow, detailing the transition from Agent Recruitment to IBIS Argumentation, Causal Chain Construction, and Consensus Optimization.
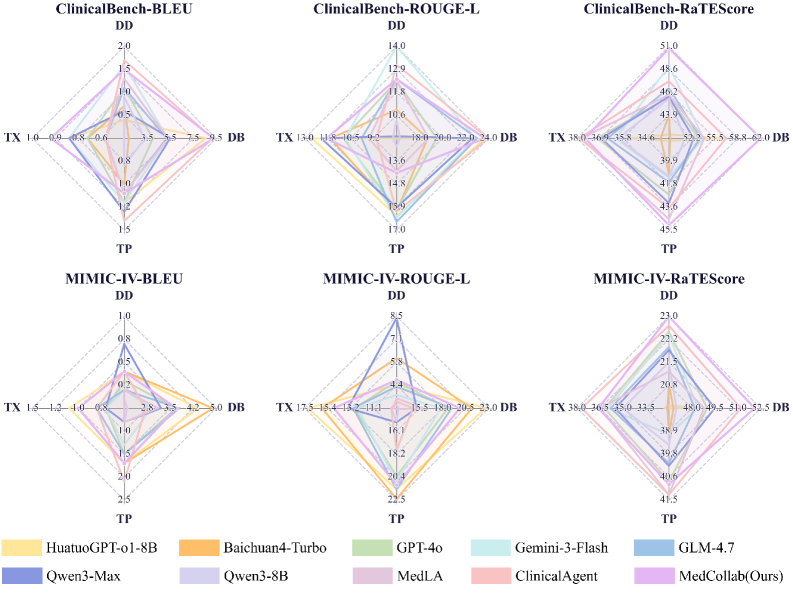
Evaluation Highlights
- Achieves 76.9% Accuracy on ClinicalBench, outperforming the strongest multi-agent baseline (ClinicalAgent) by 8.2 percentage points
- Reaches 72.4% Comprehensive Diagnostic Rate (CDR) on ClinicalBench, surpassing the best baseline by over 13.1 percentage points in multi-comorbidity cases
- Diagnostic Basis RaTEScore of 62.0% on ClinicalBench, significantly higher than leading LLMs like Gemini-3-Flash, indicating superior reasoning quality
Breakthrough Assessment
8/10
Strong contribution in structuring medical reasoning. Moving from flat predictions to causal chains and IBIS-structured argumentation directly addresses the 'black box' and hallucination issues in medical AI.