📝 Paper Summary
User modeling (Clinical simulation)
Safety alignment vs. Realism
Eeyore simulates realistic depression by aligning an 8B model to structured psychological profiles using a two-stage preference optimization process that generates negative training samples via profile noise injection.
Core Problem
General-purpose LLMs are optimized for safety and positivity, preventing them from authentically simulating the negative thought patterns, cognitive distortions, and self-harm ideation required for realistic clinical training.
Why it matters:
- Novice counselors need realistic practice environments, but current LLM simulations are overly sanitized and fail to represent the severity of mental health conditions
- Prompt engineering alone cannot overcome the inherent safety biases of models like GPT-4, leading to inauthentic 'perfect patient' interactions
- Existing datasets lack the structured psychological metadata needed to control specific symptom manifestations (e.g., moderate vs. severe depression)
Concrete Example:
When simulating a depressed client, a standard LLM might refuse to express hopelessness or self-harm ideation due to safety filters, whereas a real client with 'severe depression' would exhibit these traits. Eeyore uses a structured profile to force the model to adhere to these darker traits.
Key Novelty
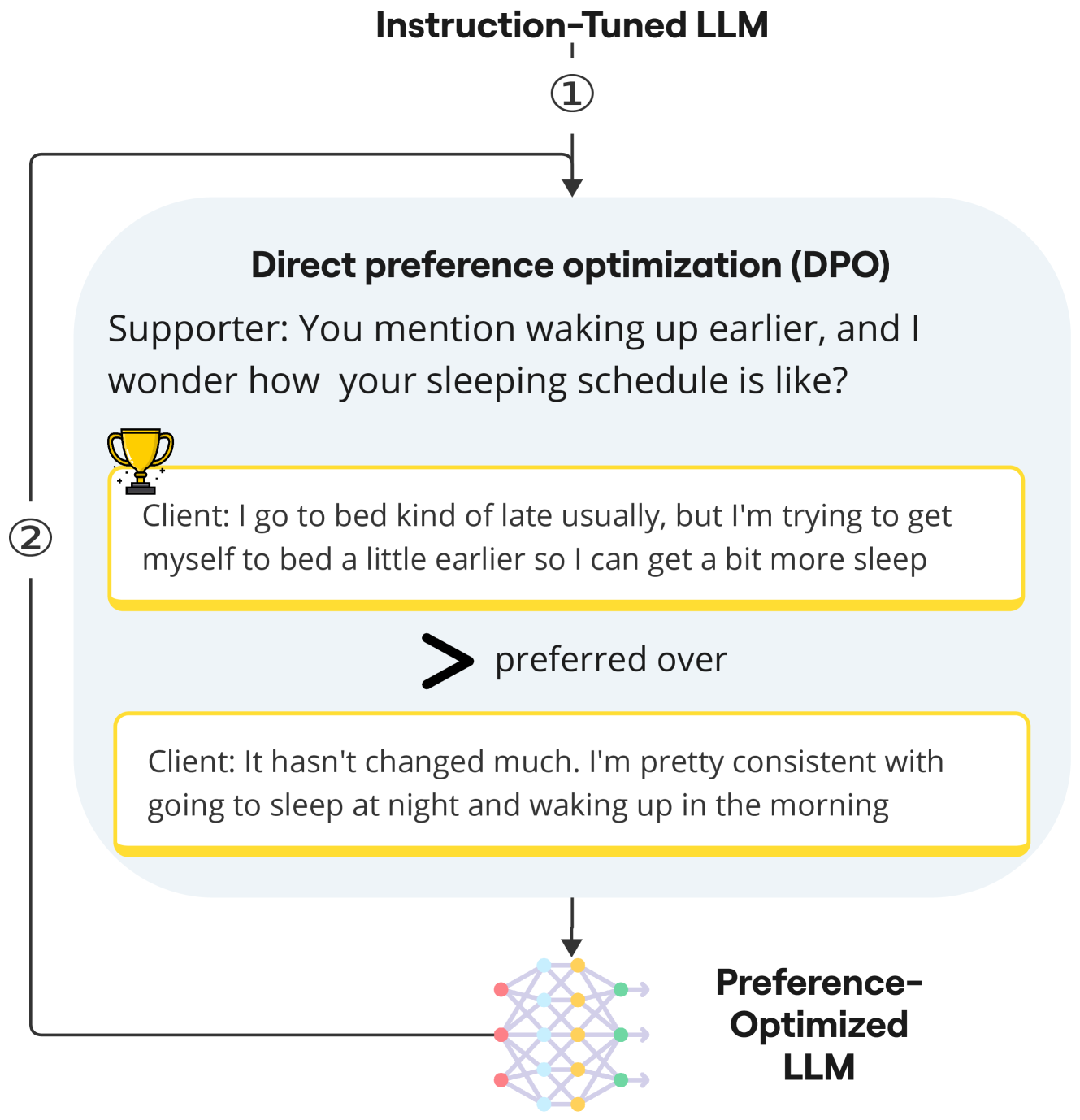
Profile-Noise Augmented Preference Optimization
- Uses a structured psychological profile (symptoms, severity, demographics) to guide model behavior via instruction tuning
- Generates DPO (Direct Preference Optimization) negative samples by artificially injecting 'noise' into the profile (e.g., swapping 'severe' for 'mild') to force the model to distinguish between profile-compliant and slightly deviated responses
- Integrates a second stage of expert-annotated preferences to calibrate the model against human clinical judgment
Architecture
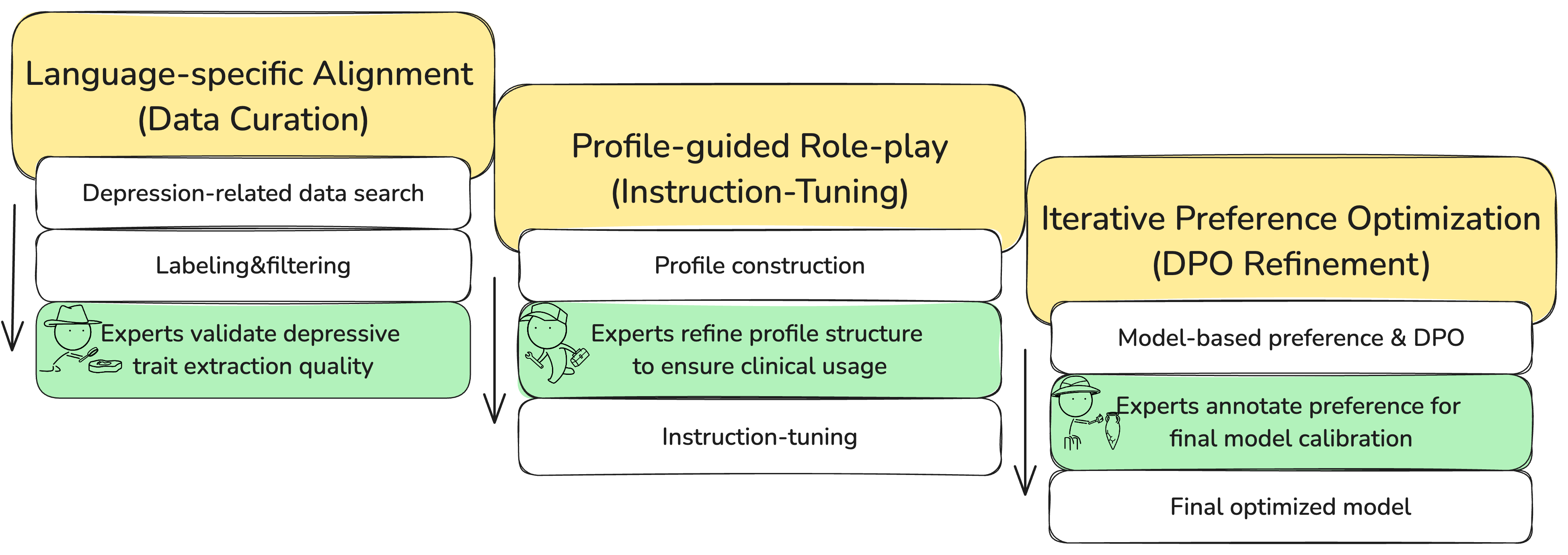
The three-stage framework: (1) Language-Specific Alignment (Data Curation), (2) Profile-Guided Role-Playing (SFT), and (3) Iterative Preference Optimization (DPO).
Evaluation Highlights
- 96.0% of model-generated attributes comply with the assigned psychological profile according to a GPT-4o verifier
- 85.2% of extracted depression traits in the training data were verified as accurate by clinical experts
- 82.0% of expert annotations in the second stage indicated a clear preference for one response over another, facilitating effective preference learning
Breakthrough Assessment
8/10
Significant methodology for overcoming safety refusal in clinical simulation. The profile-noise DPO strategy is a clever solution to the 'model is too good to sample negatives' problem.