📝 Paper Summary
Agentic AI
E-commerce Search
Synthetic Data Generation
ProductResearch improves e-commerce shopping agents by training them on synthetic trajectories generated by a multi-agent system where supervisory feedback is distilled into the agent's own reflective reasoning.
Core Problem
Existing e-commerce agents lack the depth for complex research, while open-domain 'Deep Research' agents struggle with domain gaps like mixing web search with strict product catalog queries.
Why it matters:
- Modern users need comprehensive analysis (e.g., comparing technical specs for professional gear), not just simple item retrieval or binary recommendations
- Open-domain research models hallucinate or fail to use specialized e-commerce tools effectively
- ReAct-style agents often prioritize short-term task completion over the evidentiary rigor required for high-stakes purchasing decisions
Concrete Example:
When a user asks for 'a professional camera system for specific environmental conditions,' a standard Deep Research agent might hallucinate features or fail to check inventory. The proposed system ensures the agent verifies claims against the product catalog and synthesizes expert reviews into a structured report.
Key Novelty
Multi-Agent Synthetic Trajectory Distillation
- Employs a Supervisor Agent with a state machine to critique the Research Agent at every step (Plan, Tool Use, Report), ensuring logic and coverage
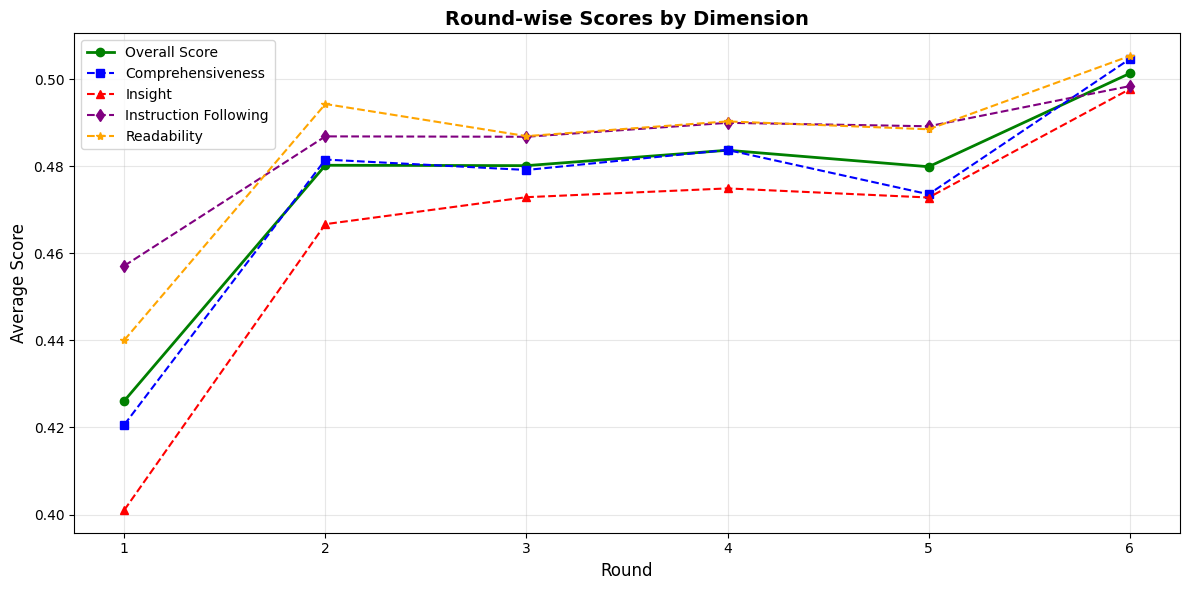
- Uses 'Reflective Internalization' to convert multi-turn supervisor-worker arguments into coherent single-turn 'thought' traces, allowing standard models to learn from the supervision without needing a supervisor at inference time
- User Agent generates dynamic, query-specific evaluation rubrics (weights for depth, readability, etc.) to guide the generation process
Architecture
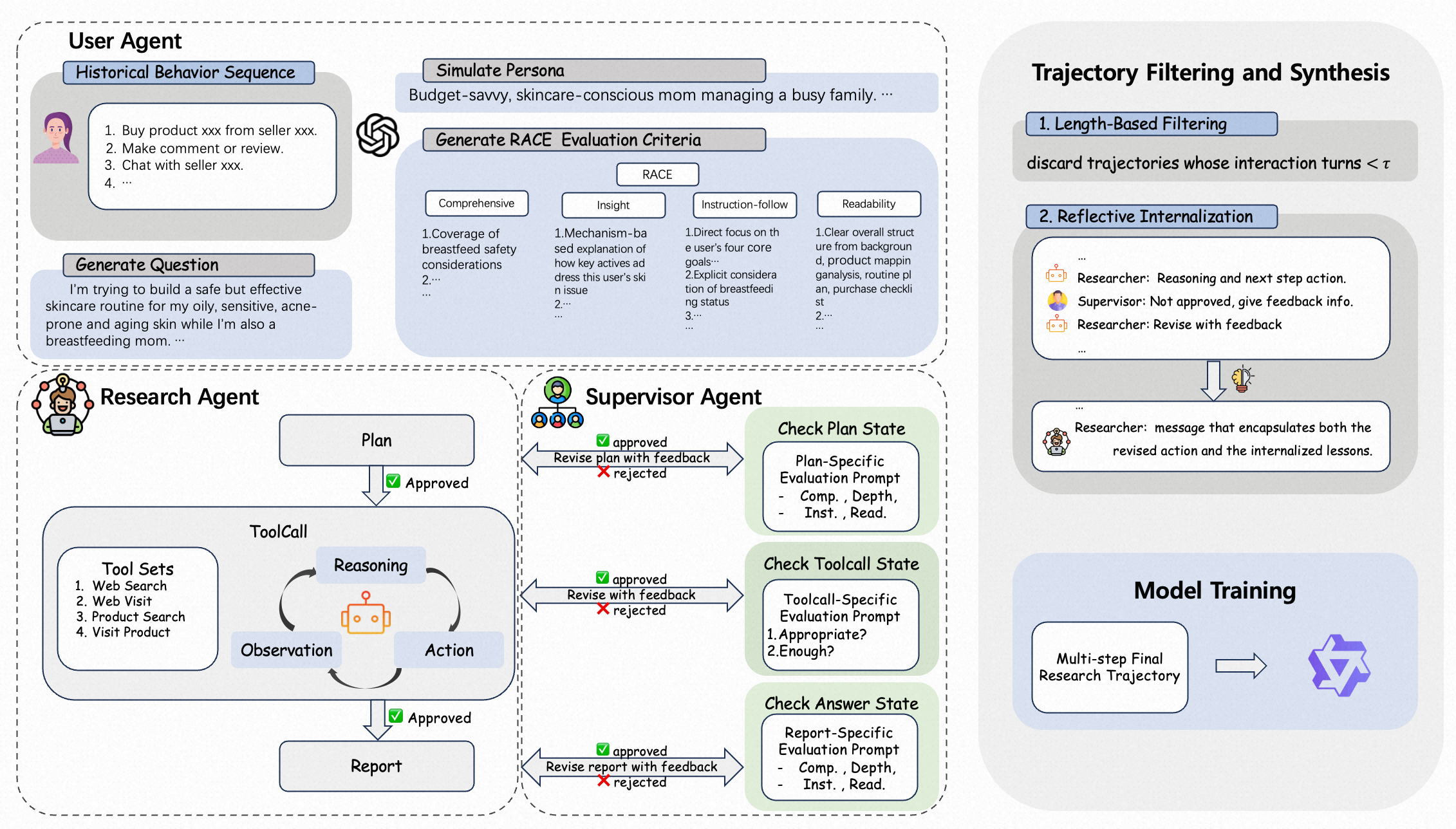
The ProductResearch framework workflow: User Profiling -> Supervised Research Execution -> Distillation
Evaluation Highlights
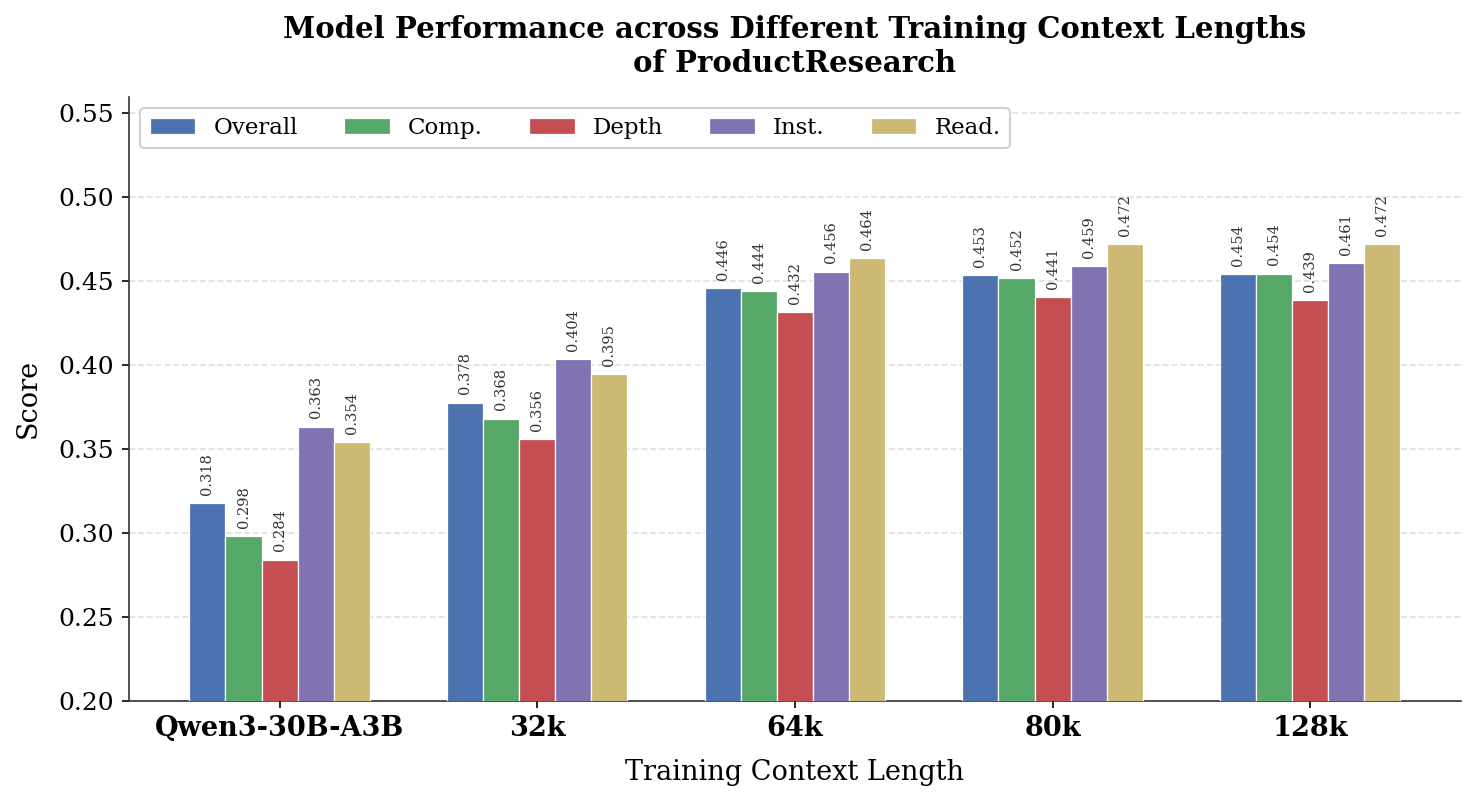
- Fine-tuned Qwen3-30B-A3B achieves a RACE score of 45.40, outperforming its base model (31.78) and the open-source Tongyi-DeepResearch (29.84)
- The model achieves an Effective Product Count of 12.45, more than tripling the base model's 3.58, indicating significantly broader product coverage
- Performance matches proprietary frontier systems like Gemini-DeepResearch (45.56) on the e-commerce research benchmark
Breakthrough Assessment
8/10
Successfully adapts the 'Deep Research' paradigm to the constrained e-commerce domain using a clever distillation method that internalizes supervision, enabling small models to match proprietary giants.