📝 Paper Summary
Multi-Agent Collaboration
Efficiency Optimization for LLMs
RouteMoA reduces Mixture-of-Agents computational costs by using a lightweight scorer to pre-filter models without inference, followed by a mixture of judges for refinement.
Core Problem
Existing Mixture-of-Agents (MoA) methods are computationally expensive because they require inference from all models before filtering or aggregating outputs.
Why it matters:
- Standard MoA scales poorly: executing all models at every layer multiplies cost and latency, making large model pools infeasible
- Sparse MoA attempts to filter responses but still requires full inference from all models first, failing to save compute on the actual generation step
Concrete Example:
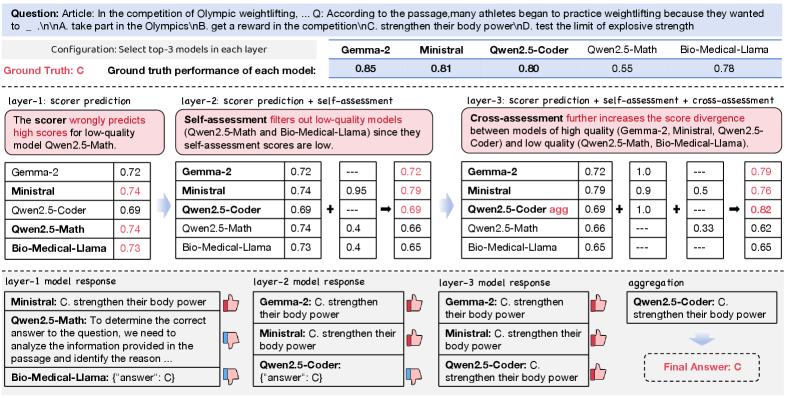
In a math query, standard MoA might invoke a biology model (Bio-Medical-Llama) and a math model (Qwen-Math). The biology model wastes compute generating a poor answer, which is then discarded. RouteMoA predicts the biology model is unsuitable purely from the query and never invokes it.
Key Novelty
Dynamic Routing without Pre-Inference (RouteMoA)
- Introduces a lightweight scorer (SLM) that predicts model performance based on the query alone, filtering out weak models before they run
- Refines these scores using a 'mixture of judges' that incorporates self-assessment (model confidence) and cross-assessment (peer review) from previous layers without extra inference
Architecture
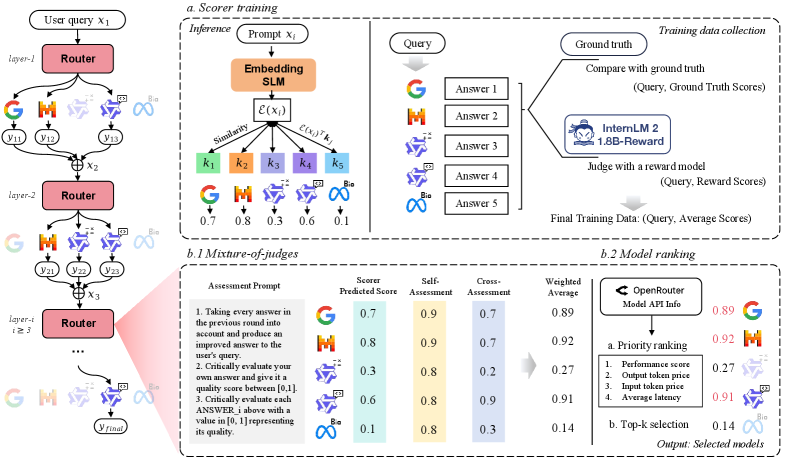
The RouteMoA workflow across multiple layers, showing the interaction between the Scorer, Model Ranking, and Mixture of Judges.
Evaluation Highlights
- Reduces inference cost by 89.8% and latency by 63.6% compared to standard MoA on a large-scale 15-model pool
- Achieves 78.6% average accuracy on 30 datasets, outperforming standard MoA (71.3%) and Sparse MoA (69.7%)
- Scorer achieves 97.9% Top-3 Hit Rate, effectively identifying high-potential models without running them
Breakthrough Assessment
8/10
Significantly improves the practicality of MoA by addressing its primary bottleneck (cost/latency) while maintaining or improving accuracy. The 'no pre-inference' routing is a crucial efficiency step.