📝 Paper Summary
Inference Acceleration
Tree-Search-Based Reasoning
SpecSearch accelerates tree-search-based reasoning by utilizing a small model to draft coarse-grained thoughts, which are then filtered by a quality-preserving rejection mechanism before large model verification.
Core Problem
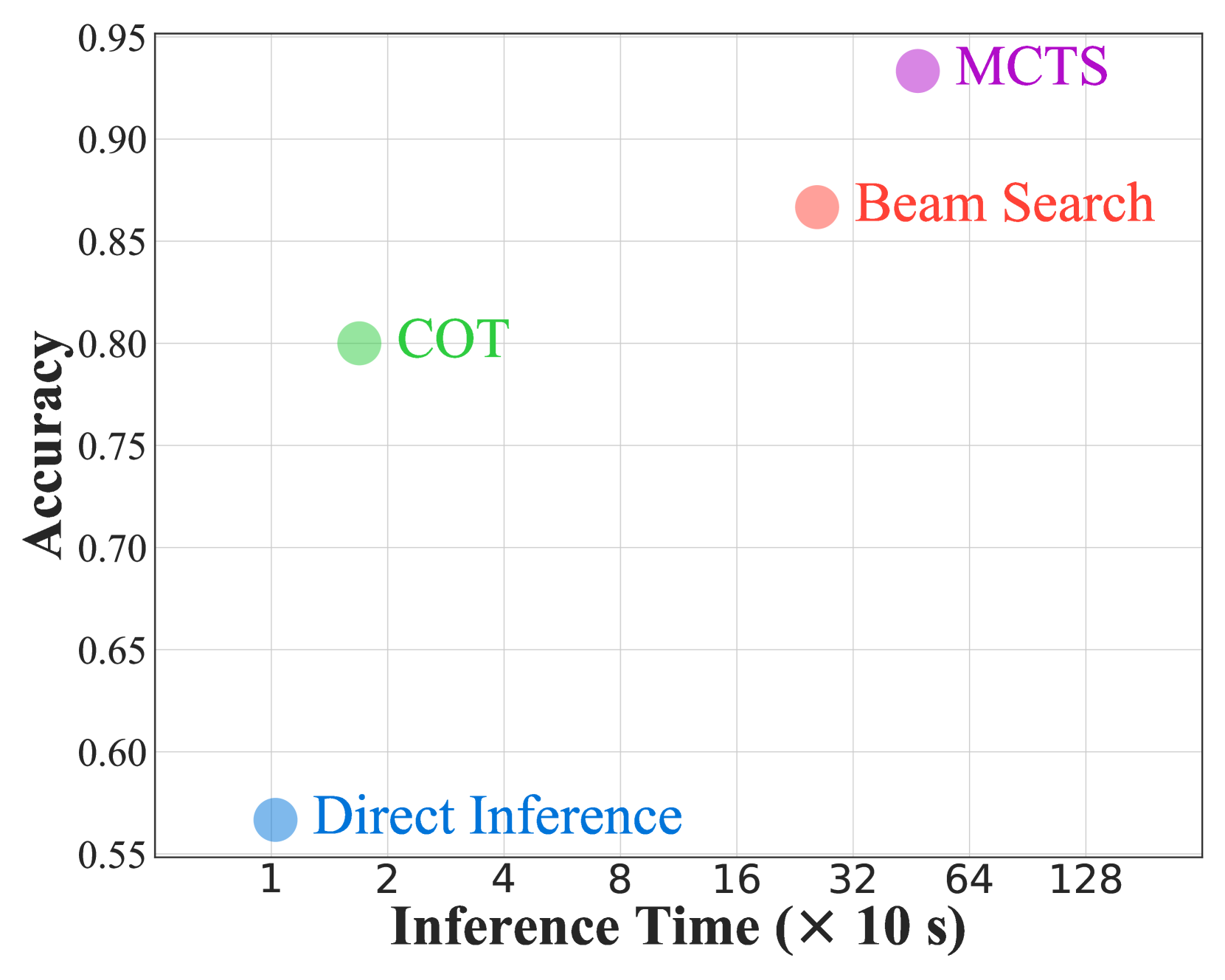
Tree-search-based reasoning methods significantly enhance LLM performance but suffer from substantial inference latency due to the need to explore a vast number of reasoning thoughts.
Why it matters:
- Inference latency increases by several orders of magnitude compared to standard prompting, making deployment in real-time applications difficult
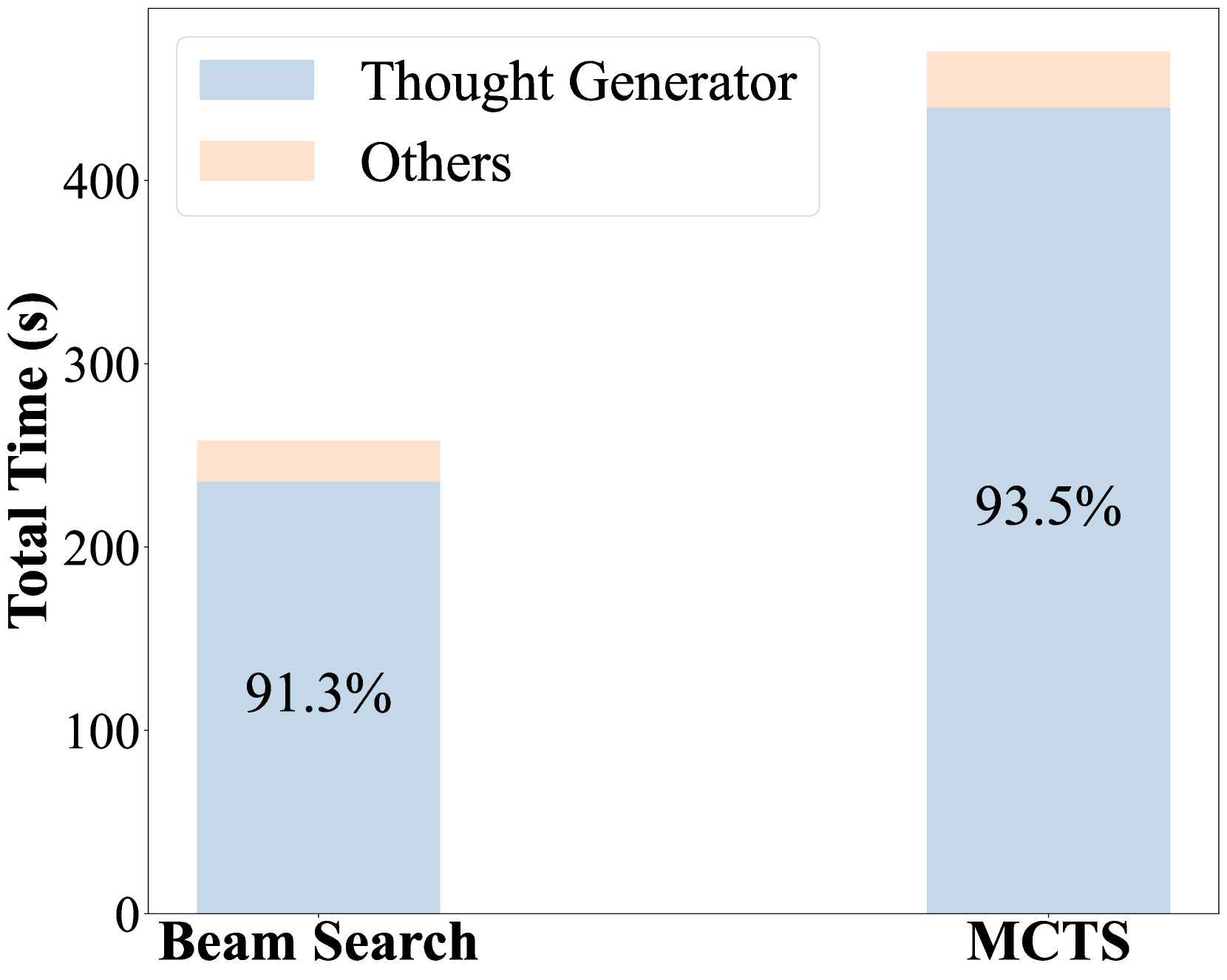
- Thought generation consumes over 91% of total computation time in tree-search methods, representing the primary efficiency bottleneck
- Existing acceleration methods like standard speculative decoding operate at the token level and fail to leverage the coarse-grained structure of reasoning thoughts
Concrete Example:
Solving '99^2 + 99 + 1' involves hard steps (99^2) and easy steps (9801+1). Using a large model for every step is inefficient; a small model can handle easier steps, but simply delegating without quality control degrades accuracy.
Key Novelty
Bi-Level Speculative Thought Generation
- Strategically collaborates a small model (drafter) and large model (verifier) at the coarse-grained 'thought' level rather than just the token level
- Uses a statistical rejection mechanism to filter out drafted thoughts that fall below the estimated quality of the large model without running the large model first
- Applies lossless token-level speculative decoding to correct only the rejected thoughts, ensuring the final output distribution matches the large model
Architecture
The SpecSearch framework workflow illustrating the interaction between the small model drafter, the thought evaluator, the rejection mechanism, and the large model corrector.
Evaluation Highlights
- Achieves up to 2.12x speedup on MATH and GSM8K datasets compared to standard tree-search baselines
- Maintains comparable reasoning quality to the large model (e.g., Qwen2.5-72B-Instruct) while significantly reducing latency
- Outperforms state-of-the-art acceleration methods like standard Speculative Decoding and TreeBon in terms of speedup
Breakthrough Assessment
8/10
Successfully generalizes speculative execution to the semantic 'thought' level for reasoning tasks, addressing a major bottleneck in advanced LLM reasoning systems with a strong theoretical guarantee.