📝 Paper Summary
Federated Learning
Knowledge Distillation
Large Language Models (LLMs)
LaDa optimizes federated collaboration between a large server model and small client models by dynamically filtering training data based on learnability gaps and aligning reasoning patterns via contrastive distillation.
Core Problem
Existing federated large-small model collaborations suffer from a bidirectional learnability gap where models cannot identify which samples effectively transfer knowledge, and reasoning transfer methods fail to adapt to local domain distributions.
Why it matters:
- Small models (SLMs) have limited capacity and cannot absorb all knowledge from a Large Language Model (LLM), making indiscriminate distillation inefficient.
- LLMs struggle to identify which samples from SLMs provide novel domain knowledge versus redundant information.
- Standard supervised fine-tuning for reasoning transfer overfits to specific demonstrations rather than learning generalizable reasoning patterns adaptable to local data.
Concrete Example:
A client-side 1.5B GEMMA model fails to learn effectively from a server-side 70B LLaDa because it cannot identify samples matching its capacity, actually achieving better results when distilling from a smaller 13B LLaDa. Conversely, the 70B model cannot distinguish which SLM samples offer novel domain knowledge.
Key Novelty
Federated Reasoning Distillation with Learnability-Aware Data Allocation (LaDa)
- Introduces a Model Learnability-Aware Data Filter that uses an exploration-exploitation strategy to select high-reward samples tailored to the specific capacity gap between each LLM-SLM pair.
- Proposes Domain Adaptive Reasoning Distillation, which aligns the joint probabilities of reasoning paths between models using a contrastive objective (similar to DPO) rather than simple supervised fine-tuning.
Architecture
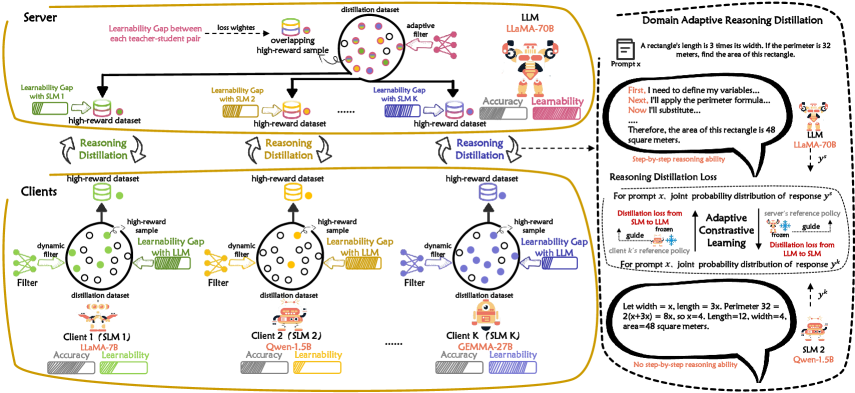
The overall architecture of LaDa, illustrating the interaction between the Server (LLM) and Client (SLM). It shows the Data Filter selecting samples from the Public Dataset and the bidirectional flow of reasoning paths (y_s, y_k) used for the Domain Adaptive Reasoning Distillation loss.
Evaluation Highlights
- Achieves up to 13.8% accuracy improvement over state-of-the-art baselines across four collaborative scenarios on MATHInstruct and GSM8K datasets.
- Outperforms FedMKT by +4.3% accuracy on the GSM8K dataset in the Standard Collaboration scenario.
- Demonstrates convergence guarantees with a rate of O(1/√T) for the collaboration framework enhanced with LaDa modules.
Breakthrough Assessment
8/10
Identifies and addresses the 'bidirectional learnability gap' in heterogeneous federated learning, a nuanced problem often overlooked. The solution combines RL-based data filtering with contrastive reasoning distillation, showing strong empirical gains.