📝 Paper Summary
Continual Pretraining
Lifelong Learning
Temporal Distribution Shift
TiC-LM introduces a massive time-stratified benchmark derived from 114 Common Crawl dumps to evaluate how well LLMs can be continually updated on evolving web data without catastrophic forgetting.
Core Problem
Current LLMs suffer from knowledge cutoffs and require expensive re-training from scratch to update, while existing continual learning benchmarks are too small (single domain) or lack long-term temporal shifts to model realistic web-scale evolution.
Why it matters:
- Retraining LLMs from scratch for every update is prohibitively expensive in terms of compute and energy
- Existing benchmarks focus on single domains (e.g., Wikipedia) or few timesteps, failing to capture the complex distribution shifts of the general web over decades
- Models deteriorate on new data due to knowledge cutoffs, but simply fine-tuning on new data causes catastrophic forgetting of older knowledge
Concrete Example:
A model trained on data up to 2016 performs well on NumPy (released 1995) but fails on PyTorch (released 2016). Continual training on 2017+ data might learn PyTorch but 'forget' NumPy details unless specific replay strategies are used.
Key Novelty
TiC-CC: A Web-Scale Time-Stratified Dataset & Benchmark
- Constructs a 2.9 trillion token dataset from 114 monthly Common Crawl dumps (2013–2024), preserving strict temporal causality (no future data leakage)
- Establishes a 10+ year experimental setup where models must update incrementally month-by-month, mirroring a realistic lifelong learning scenario
- Introduces dynamic domain-specific evaluations (TiC-Wiki, TiC-StackExchange, TiC-CodeDocs) to measure how forgetting varies across stable vs. rapidly evolving knowledge
Architecture
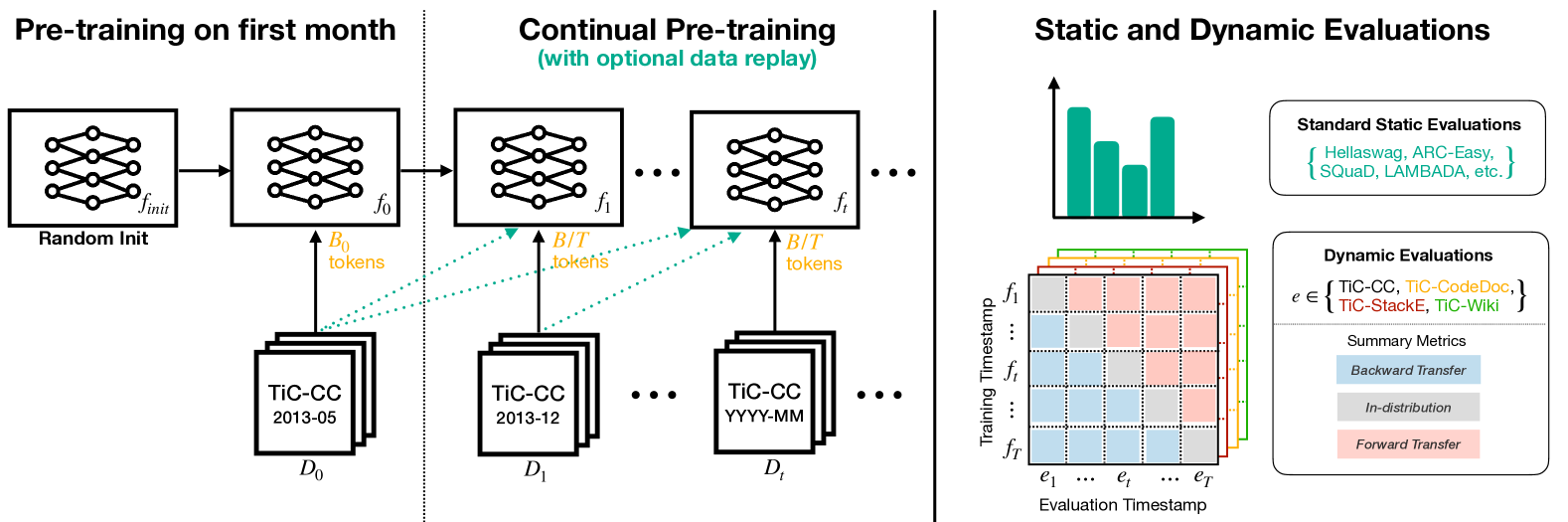
The TiC-LM benchmark construction and evaluation pipeline.
Evaluation Highlights
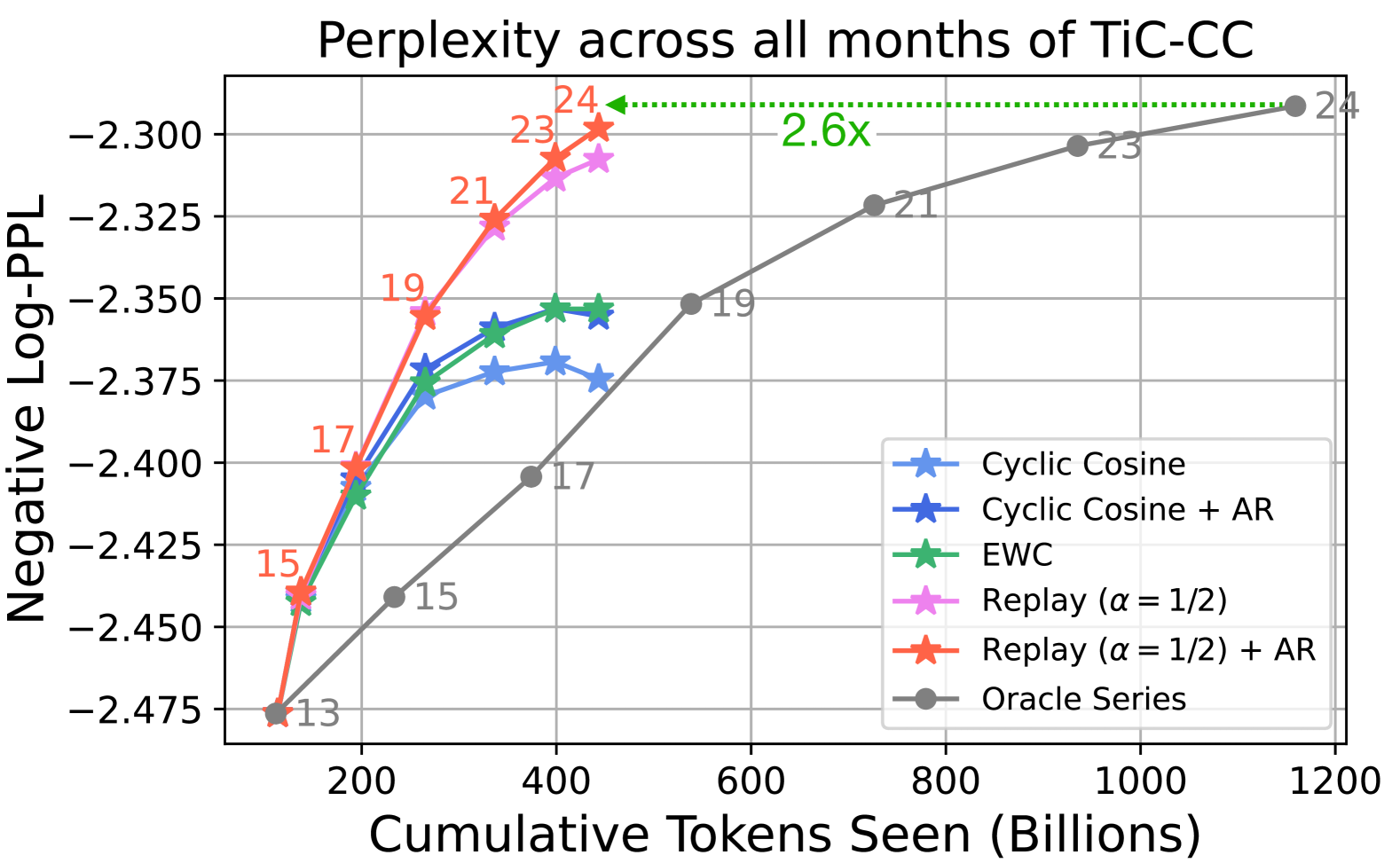
- Continual pretraining with replay and learning rate schedules matches the performance of re-training from scratch (Oracles) while requiring 2.6x less compute
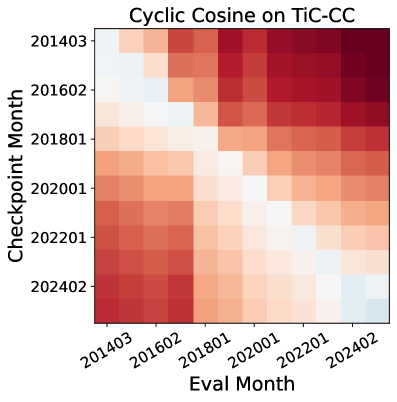
- On general web data (TiC-CC), replay is essential; without it, models suffer significant catastrophic forgetting of older dumps
- Forgetting is domain-dependent: Replay hurts performance on rapidly evolving topics like PyTorch (where old data is obsolete) but helps on stable topics like NumPy
Breakthrough Assessment
9/10
Significantly scales up continual learning research by orders of magnitude (2.9T tokens vs prior ~100B benchmarks) and provides the first realistic web-scale testbed for lifelong LLM training.