📝 Paper Summary
LLM-based Recommender Systems
Retrieval-Augmented Generation (RAG)
DOKE augments frozen LLMs with domain-specific knowledge (item attributes and collaborative filtering signals) via prompt engineering, enabling high-performance recommendation without fine-tuning.
Core Problem
General-purpose LLMs lack two critical types of domain knowledge required for accurate recommendations: the full, evolving dataset of items and specific working patterns (like collaborative filtering signals) inherent in user interaction logs.
Why it matters:
- Fine-tuning massive LLMs on domain data is computationally expensive and prone to overfitting, potentially sacrificing general intelligence
- LLMs hallucinate on less popular or fresh items not present in their pre-training corpus
- Purely semantic-based recommendations by LLMs miss behavioral patterns (collaborative signals) found in interaction data
Concrete Example:
In a movie recommendation task, an LLM might recommend 'Good Will Hunting' to a user who watched 'Rain Man' because both are dramas (semantic similarity). However, domain interaction data shows users actually co-click 'Field of Dreams' (collaborative signal), a pattern the LLM misses without external knowledge.
Key Novelty
Domain-Specific Knowledge Extraction (DOKE) Paradigm
- Treats domain knowledge (attributes and interaction patterns) as 'plugins' injected into prompts rather than weights to be learned via fine-tuning
- Extracts collaborative filtering signals (Item-to-Item and User-to-Item relevance) from interaction logs using lightweight external models
- Translates numerical relevance scores into LLM-understandable formats: natural language templates or reasoning paths on a knowledge graph
Architecture
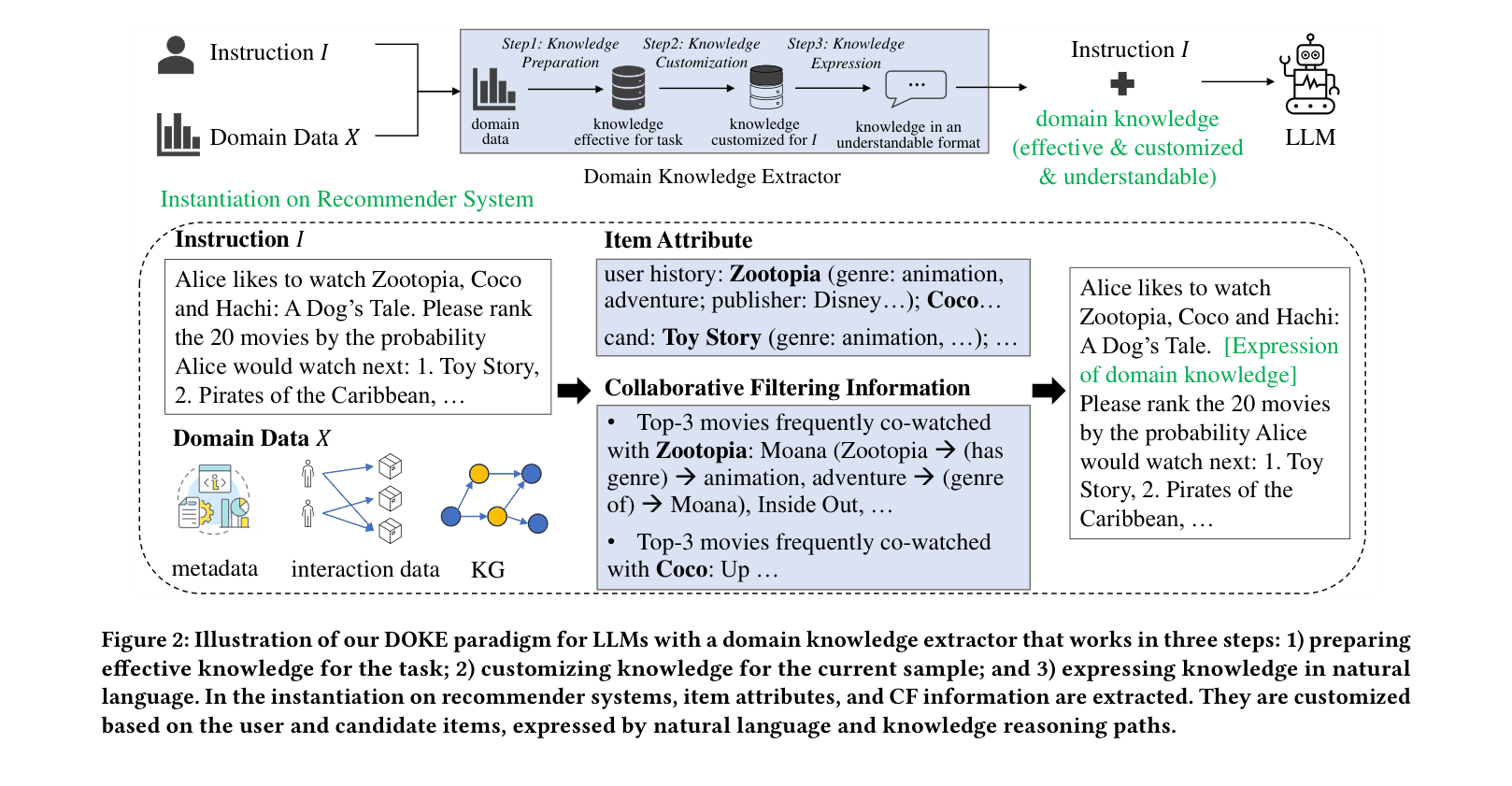
The workflow of the DOKE paradigm instantiated for Recommender Systems.
Evaluation Highlights
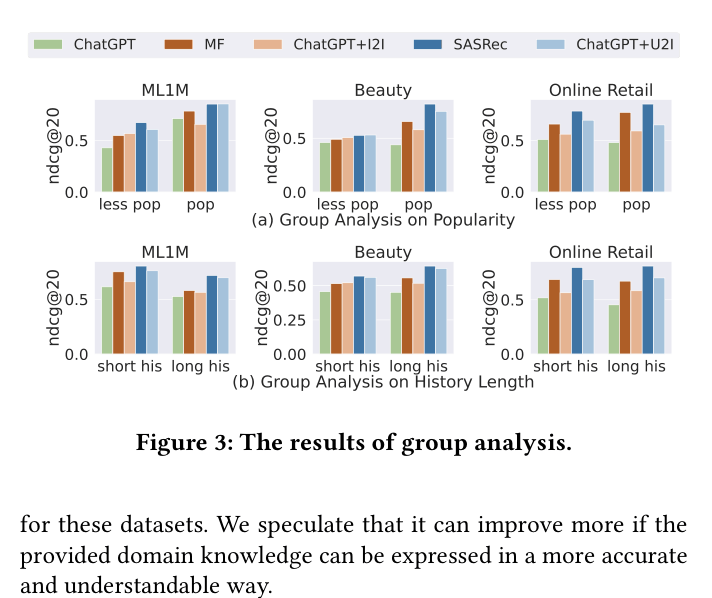
- Significantly outperforms zero-shot LLM baselines (e.g., +84.3% NDCG@1 on ML-1M for ChatGPT) by incorporating customized domain knowledge
- Achieves performance comparable to fully trained traditional models (e.g., SASRec) and fine-tuned LLMs (Llama-2-7b) without updating parameters
- Customized knowledge (history-candidate relevance) yields higher gains than global knowledge, improving NDCG@10 by +40.5% on ML-1M over standard prompts
Breakthrough Assessment
7/10
Strong practical contribution demonstrating that cheap prompt augmentation with CF signals competes with expensive fine-tuning. While methodologically simple, it effectively bridges the gap between semantic LLM reasoning and behavioral recommendation data.