📝 Paper Summary
Knowledge Distillation
Reasoning
QR-Distill improves knowledge distillation by filtering teacher reasoning paths for quality, adaptively routing them to students based on compatibility, and enabling peer collaboration between students.
Core Problem
Distilling reasoning capabilities from powerful teachers is limited by standard token-level supervision and the variable quality of reasoning paths, which may be incorrect or unsuitable for specific student models.
Why it matters:
- Standard black-box distillation supervises only a narrow slice of the teacher's distribution, failing to capture full reasoning nuances
- Simply using all available teacher paths is suboptimal because some are incorrect, spurious, or mismatched to a student's architecture
- Deploying large proprietary models is resource-intensive; effective distillation to smaller models is crucial for efficiency
Concrete Example:
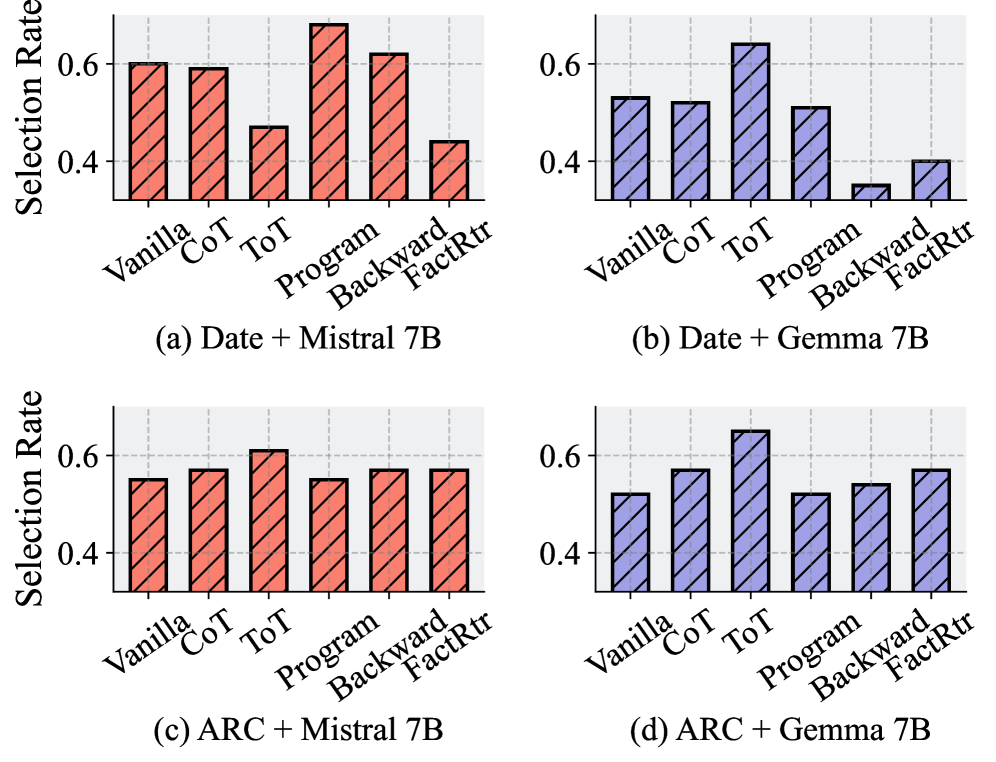
A program-style explanation might benefit a model strong in algorithmic reasoning but confuse a model optimized for natural language, while a long multi-hop chain might overcomplicate a simple question.
Key Novelty
Quality-filtered Routing with Cooperative Distillation (QR-Distill)
- Selects high-quality reasoning paths by verifying final answers and using an LLM-as-judge to remove spurious steps
- Uses a trainable router to dynamically assign specific reasoning paths to the student model most likely to benefit from them
- Enables students to act as peer teachers by sharing knowledge through a soft ensemble representation, bridging gaps in individual coverage
Architecture

The overall framework of QR-Distill, illustrating the flow from path generation to filtering, routing, and cooperative distillation.
Evaluation Highlights
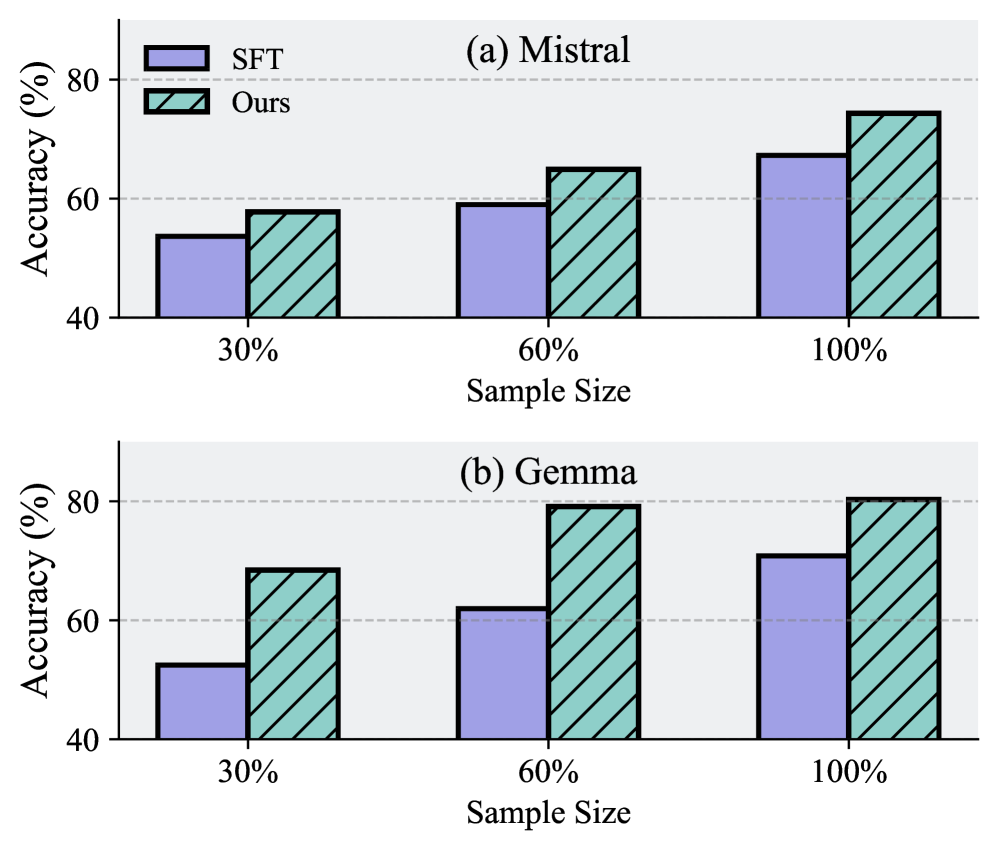
- Achieves an average improvement of 41.44% (Mistral) and 63.33% (Gemma) over zero-shot performance across diverse reasoning benchmarks
- Outperforms single-path distillation baselines by 24.32% on average, confirming the value of diverse reasoning paths
- Surpasses multi-path baselines without routing/collaboration by up to 13.36%, demonstrating the efficacy of adaptive assignment and peer learning
Breakthrough Assessment
7/10
Strong empirical gains and a novel combination of routing and peer distillation. Addresses a clear bottleneck in multi-path distillation (path quality/suitability).