📝 Paper Summary
Clinical Named Entity Recognition (NER)
Zero-Shot Learning
OEMA employs a multi-agent framework with an ontology-driven discriminator to align token-level example selection and integrate type descriptions with self-annotated examples for clinical entity recognition.
Core Problem
Zero-shot clinical NER struggles with the mismatch between sentence-level example retrieval and token-level entity tasks, and fails to effectively integrate prompt design with self-improvement frameworks.
Why it matters:
- Traditional supervised models like BioClinicalBERT require expensive, expert-annotated medical corpora
- Standard zero-shot methods use coarse retrieval (e.g., sentence similarity) that introduces noise by selecting examples with irrelevant entities
- Advanced prompt designs (like type descriptions) are rarely synergized with self-improvement loops, limiting performance
Concrete Example:
In a self-improvement framework, a retriever might select a neighbor sentence based on overall semantic similarity to the input, but that neighbor might contain entirely different medical entities (noise), misleading the LLM which relies on token-level precision.
Key Novelty
Ontology-Enhanced Multi-Agent Collaboration (OEMA)
- Decomposes the zero-shot NER task into three collaborative agents: a Self-Annotator (creates data), a Discriminator (filters data), and a Predictor (infers results)
- Uses a 'Discriminator' agent that leverages SNOMED CT ontology to score example helpfulness at the token level, rather than relying on shallow sentence-level cosine similarity
- Synergizes 'type priors' (descriptions of entity types) with 'structured examples' (self-annotated few-shot data) in the final prompt to boost inference
Architecture
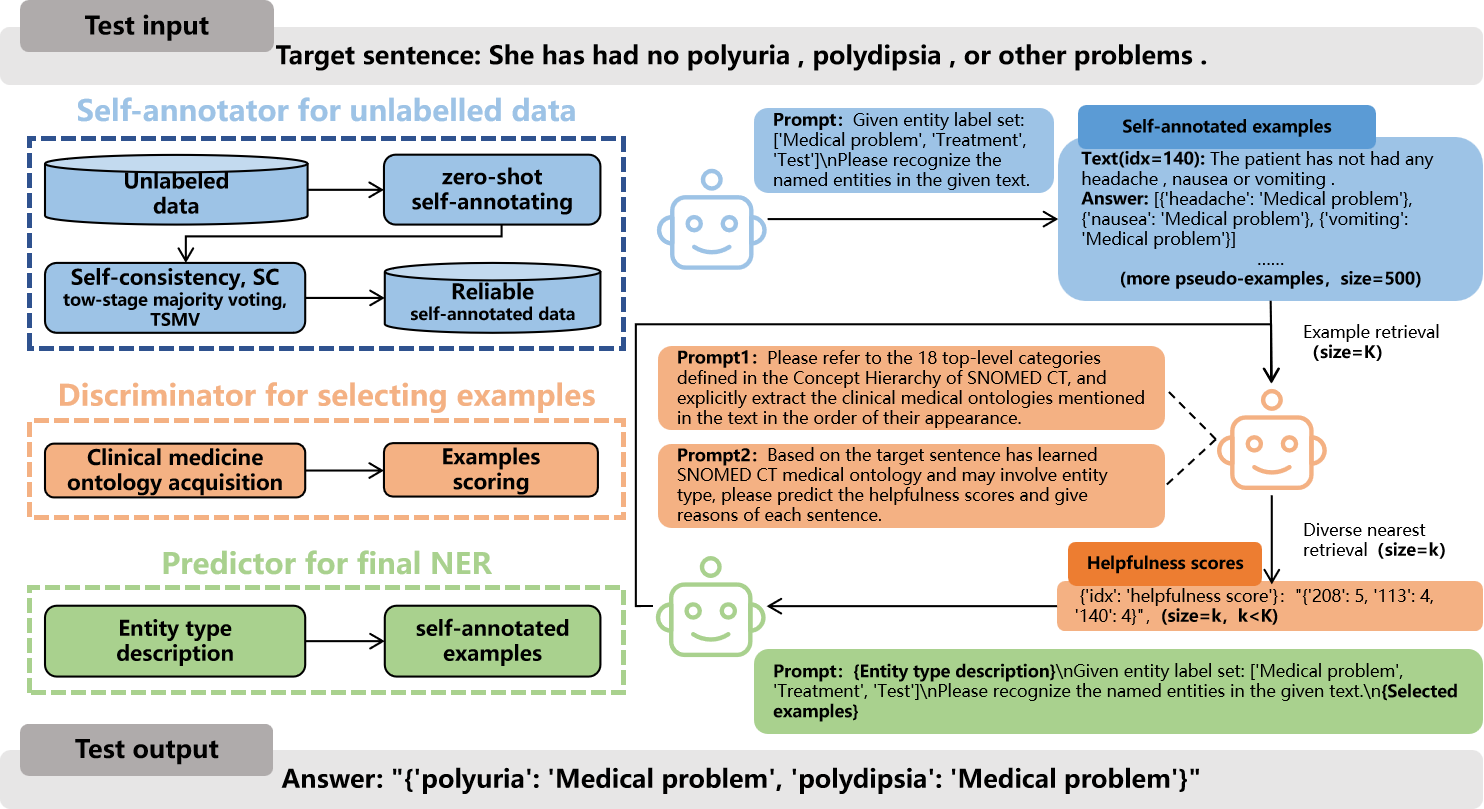
The overall OEMA framework illustrating the workflow between the three agents: Self-Annotator, Discriminator, and Predictor.
Breakthrough Assessment
7/10
Proposed multi-agent architecture addresses a specific granularity mismatch in ICL. While results are claimed to be SOTA, the snippet lacks numeric evidence to verify the magnitude of the breakthrough.