📝 Paper Summary
Test-time compute scaling
Token-efficient inference
Reasoning aggregation
PACER improves reasoning accuracy by generating a compact summary of peer answers (a consensus packet) and allowing high-confidence but incorrect traces to self-correct in a single revision step.
Core Problem
Standard majority voting generates many redundant, expensive traces, while efficient early-stopping methods evaluate traces in isolation, failing to correct 'confidently wrong' hallucinations that could be fixed by seeing peer consensus.
Why it matters:
- Majority voting scales linearly in cost with the number of samples, making high accuracy prohibitively expensive for real-world deployment
- Independent evaluation leaves a 'blind spot': models often generate hallucinated paths with misleadingly high confidence that survive uncertainty filters but are logically flawed compared to correct peers
Concrete Example:
In hard math problems, a model might confidently generate a wrong answer supported by flawed logic (a 'confident hallucination'). DeepConf would keep this trace because its token probability is high. Without seeing that 10 other traces found a different answer with more stable reasoning, this trace has no mechanism to doubt or correct itself.
Key Novelty
Packet-Conditioned Revision (PACER)
- Introduces a 'consensus packet': a compact, text-based summary of the top candidate answers, their support counts, and one representative rationale per answer derived from the initial sample pool
- Performs a single-round 'peer review': existing traces read the packet and optionally revise their answer if they detect their reasoning diverges from a more stable group consensus
Architecture
The three-stage workflow of PACER: (1) DeepConf Screening, (2) Packet Construction, (3) Packet-Conditioned Revision.
Evaluation Highlights
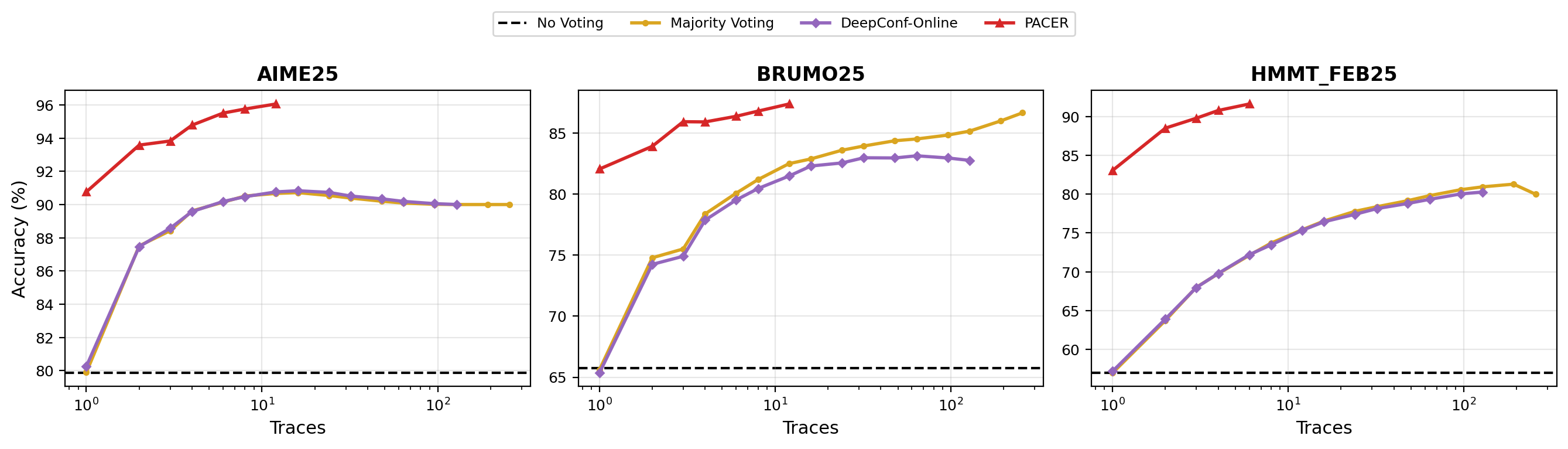
- +10.0 absolute percentage points on HMMT 2025 using GPT-OSS compared to the DeepConf-Online baseline (28/30 vs 25/30)
- Matches or exceeds the accuracy of 256-sample Majority Voting (MV@256) on AIME and BRUMO benchmarks while generating significantly fewer tokens
- Consistently improves the accuracy-token tradeoff compared to raw ensemble baselines across multiple competitive math benchmarks (AIME 2024/2025, HMMT 2025, BRUMO 2025)
Breakthrough Assessment
7/10
Offers a smart, low-overhead mechanism to bridge the gap between expensive ensembles and cheap early-stopping methods. The concept of a 'consensus packet' is a reusable primitive for efficient coordination.