📝 Paper Summary
Personalization
Alignment
Human-LLM Interaction
This paper presents a framework to train LLMs to implicitly infer and adapt to individual user personas during conversation, utilizing a large-scale synthetic dataset generated via multi-LLM role-playing.
Core Problem
Current alignment methods (like RLHF) enforce generalized principles (helpfulness, harmlessness) but ignore diverse individual preferences, leading to generic 'one-size-fits-all' responses that fail to adapt to specific user personas.
Why it matters:
- Neglecting individual differences undermines customized user experiences, particularly for minority groups or users with distinct communication styles
- Existing persona databases lack the detail required to guide consistent, long-context multi-turn conversations
- Standard models fail to implicitly infer unspoken preferences (e.g., personality traits) from conversation history, requiring explicit and rigid instructions instead
Concrete Example:
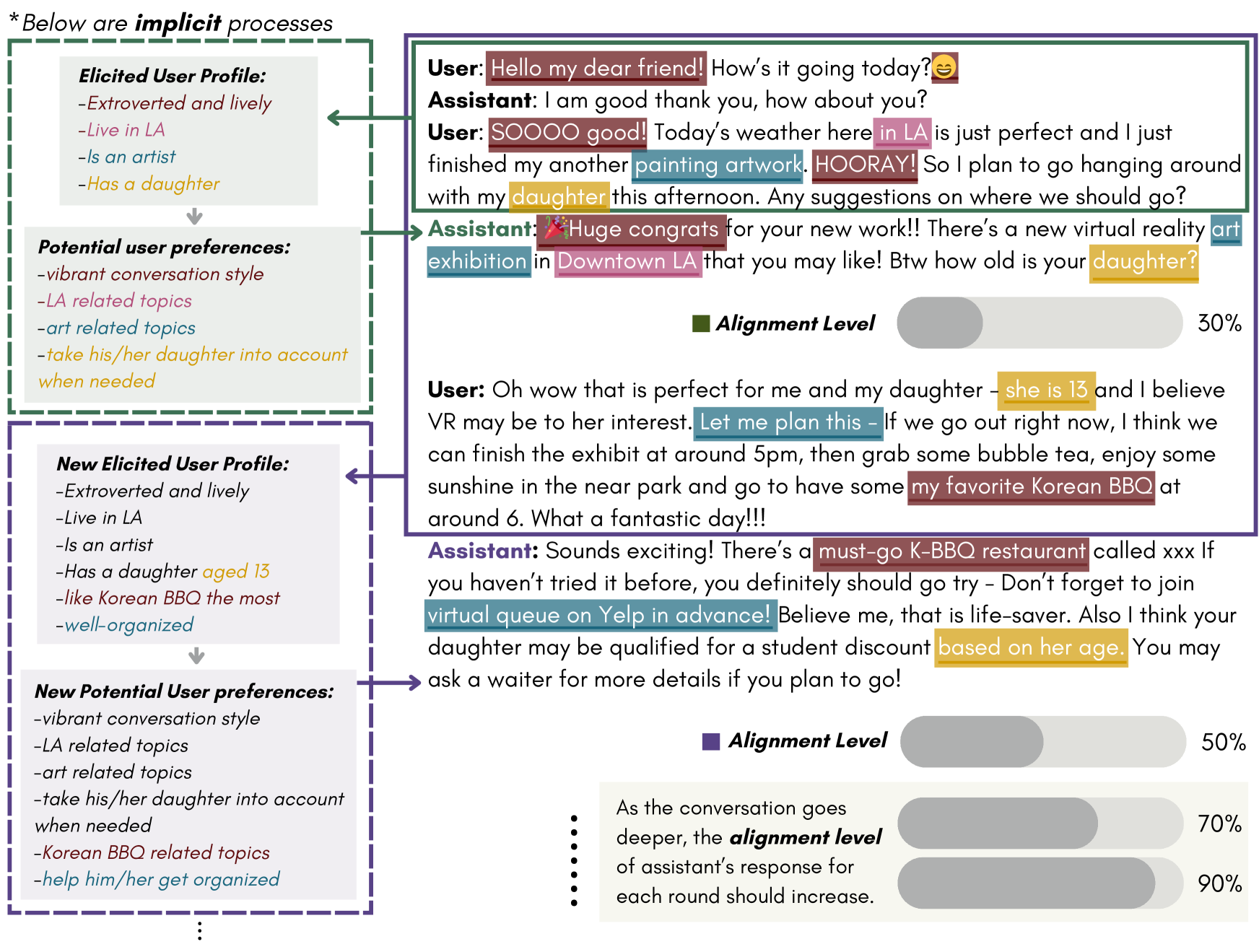
A user mentions living in a city and having an artistic background. A standard LLM gives a generic polite response. The proposed aligned model infers the user is an 'extroverted artist parent,' dynamically uses emojis, recommends specific art exhibitions, and asks about their daughter (Figure 1 case study).
Key Novelty
Interaction-to-Align (I2A)
- Generates a massive, diverse pool of fine-grained user personas (combining profiles and personalities) via iterative self-generation and filtering
- Constructs a tree-structured multi-turn preference dataset using a 'Multi-LLM Collaboration' framework where agents play specific roles (User, Inducer, Preferred Responder, Rejected Responder) to simulate personalized dialogues
- Trains a single model to implicitly infer user traits from dialogue history and align its output style and content accordingly without explicit system prompts
Architecture
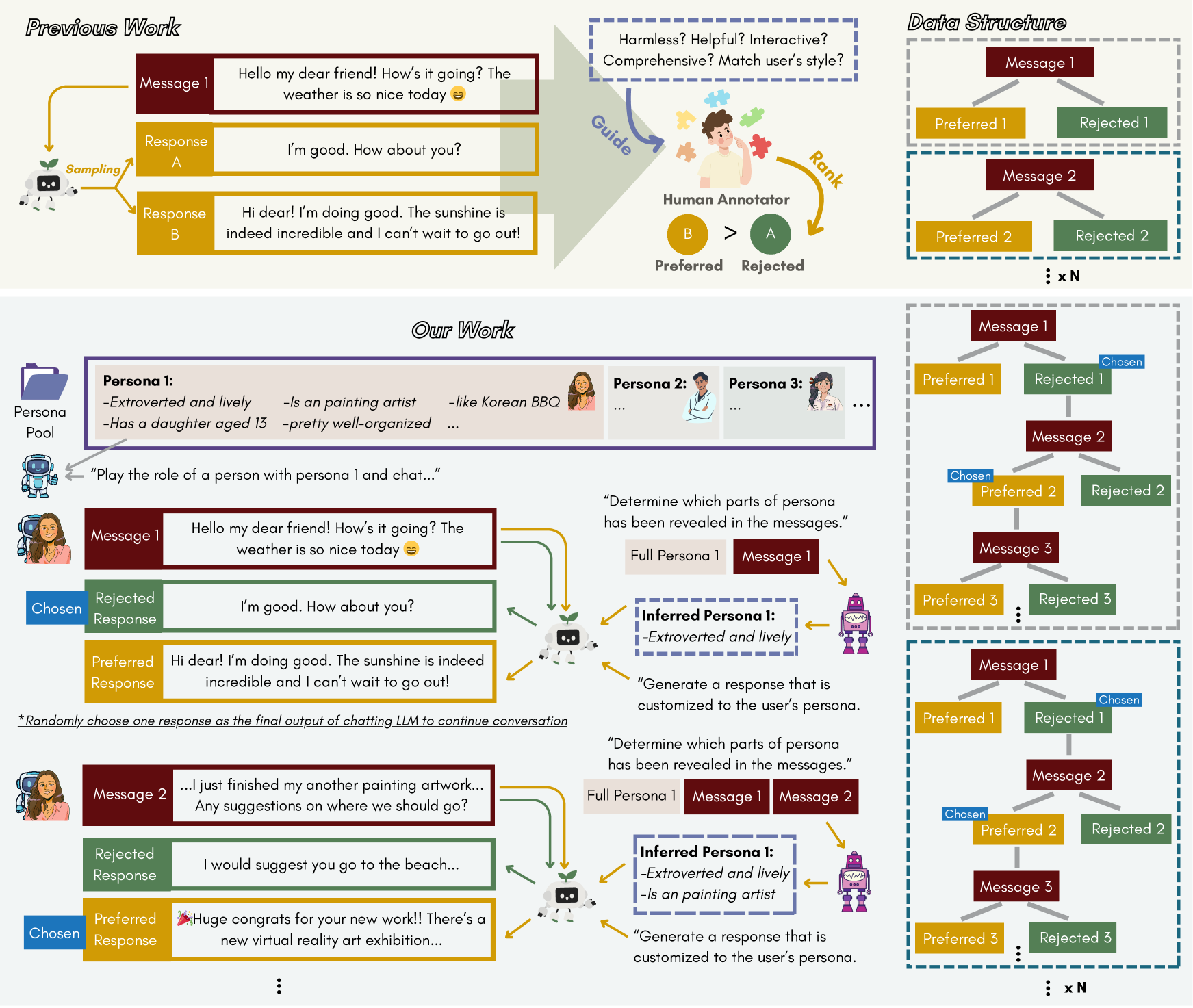
The Data Construction Pipeline (Multi-LLM Collaboration) used to create the training dataset. This is the core structural contribution of the paper.
Evaluation Highlights
- Achieves an average relative improvement of 32.0% in alignment performance compared to mainstream baselines like Llama-3 on the ALOE benchmark
- Demonstrates the ability to dynamically increase alignment levels as the conversation progresses, refining the understanding of the user's persona with each turn
- Successfully creates a diverse pool of 3,310 distinct user personas and over 3,000 multi-turn conversation trees for training
Breakthrough Assessment
7/10
Addresses a critical gap in personalization (implicit inference vs. explicit prompting) with a robust synthetic data pipeline. While the core model architecture is standard, the data-centric approach to dynamic alignment is significant.